Week 11 [Oct 29]
Todo
Admin info to read:
Release as a jar file, release updated user guide, peer-test released products, verify code authorship.
v1.3 Summary of Milestone
| Milestone | Minimum acceptable performance to consider as 'reached' |
|---|---|
| Contributed code to v1.3 | code merged |
| Code is RepoSense-compatible | as stated in mid-v1.3 |
| v1.3 jar file released on GitHub | as stated |
| v1.3 milestone properly wrapped up on GitHub | as stated |
| Documentation updated to match v1.3 | at least the User Guide and the README.adoc is updated |
v1.3 Project Management
Ensure your code is RepoSense-compatible,
Using RepoSense
In previous semesters we asked students to annotate all their code using special @@author tags so that we can extract each student's code for grading. This semester, we are trying out a new tool called RepoSense that is expected to reduce the need for such tagging, and also make it easier for you to see (and learn from) code written by others.
1. View the current status of code authorship data:
- The report generated by the tool is available at Project Code Dashboard (BETA). The feature that is most relevant to you is the Code Panel (shown on the right side of the screenshot above). It shows the code attributed to a given author. You are welcome to play around with the other features (they are still under development and will not be used for grading this semester).
- Click on your name to load the code attributed to you (based on Git blame/log data) onto the code panel on the right.
- If the code shown roughly matches the code you wrote, all is fine and there is nothing for you to do.
2. If the code does not match:
-
Here are the possible reasons for the code shown not to match the code you wrote:
- the git username in some of your commits does not match your GitHub username (perhaps you missed our instructions to set your Git username to match GitHub username earlier in the project, or GitHub did not honor your Git username for some reason)
- the actual authorship does not match the authorship determined by git blame/log e.g., another student touched your code after you wrote it, and Git log attributed the code to that student instead
-
In those cases,
- Install RepoSense (see the Getting Started section of the RepoSense User Guide)
- Use the two methods described in the RepoSense User Guide section Configuring a Repo to Provide Additional Data to RepoSense to provide additional data to the authorship analysis to make it more accurate.
- If you add a
config.jsonfile to your repo (as specified by one of the two methods),- Please use the template json file given in the module website so that your display name matches the name we expect it to be.
- If your commits have multiple author names, specify all of them e.g.,
"authorNames": ["theMyth", "theLegend", "theGary"] - Update the line
config.jsonin the.gitignorefile of your repo as/config.jsonso that it ignores theconfig.jsonproduced by the app but not the_reposense/config.json.
- If you add
@@authorannotations, please follow the guidelines below:
Adding @@author tags indicate authorship
-
Mark your code with a
//@@author {yourGithubUsername}. Note the double@.
The//@@authortag should indicates the beginning of the code you wrote. The code up to the next//@@authortag or the end of the file (whichever comes first) will be considered as was written by that author. Here is a sample code file://@@author johndoe method 1 ... method 2 ... //@@author sarahkhoo method 3 ... //@@author johndoe method 4 ... -
If you don't know who wrote the code segment below yours, you may put an empty
//@@author(i.e. no GitHub username) to indicate the end of the code segment you wrote. The author of code below yours can add the GitHub username to the empty tag later. Here is a sample code with an emptyauthortag:method 0 ... //@@author johndoe method 1 ... method 2 ... //@@author method 3 ... method 4 ... -
The author tag syntax varies based on file type e.g. for java, css, fxml. Use the corresponding comment syntax for non-Java files.
Here is an example code from an xml/fxml file.<!-- @@author sereneWong --> <textbox> <label>...</label> <input>...</input> </textbox> ... -
Do not put the
//@@authorinside java header comments.
👎/** * Returns true if ... * @@author johndoe */👍
//@@author johndoe /** * Returns true if ... */
What to and what not to annotate
-
Annotate both functional and test code There is no need to annotate documentation files.
-
Annotate only significant size code blocks that can be reviewed on its own e.g., a class, a sequence of methods, a method.
Claiming credit for code blocks smaller than a method is discouraged but allowed. If you do, do it sparingly and only claim meaningful blocks of code such as a block of statements, a loop, or an if-else statement.- If an enhancement required you to do tiny changes in many places, there is no need to annotate all those tiny changes; you can describe those changes in the Project Portfolio page instead.
- If a code block was touched by more than one person, either let the person who wrote most of it (e.g. more than 80%) take credit for the entire block, or leave it as 'unclaimed' (i.e., no author tags).
- Related to the above point, if you claim a code block as your own, more than 80% of the code in that block should have been written by yourself. For example, no more than 20% of it can be code you reused from somewhere.
- 💡 GitHub has a blame feature and a history feature that can help you determine who wrote a piece of code.
-
Do not try to boost the quantity of your contribution using unethical means such as duplicating the same code in multiple places. In particular, do not copy-paste test cases to create redundant tests. Even repetitive code blocks within test methods should be extracted out as utility methods to reduce code duplication. Individual members are responsible for making sure code attributed to them are correct. If you notice a team member claiming credit for code that he/she did not write or use other questionable tactics, you can email us (after the final submission) to let us know.
-
If you wrote a significant amount of code that was not used in the final product,
- Create a folder called
{project root}/unused - Move unused files (or copies of files containing unused code) to that folder
- use
//@@author {yourGithubUsername}-unusedto mark unused code in those files (note the suffixunused) e.g.
//@@author johndoe-unused method 1 ... method 2 ...Please put a comment in the code to explain why it was not used.
- Create a folder called
-
If you reused code from elsewhere, mark such code as
//@@author {yourGithubUsername}-reused(note the suffixreused) e.g.//@@author johndoe-reused method 1 ... method 2 ... -
You can use empty
@@authortags to mark code as not yours when RepoSense attribute the to you incorrectly.-
Code generated by the IDE/framework, should not be annotated as your own.
-
Code you modified in minor ways e.g. adding a parameter. These should not be claimed as yours but you can mention these additional contributions in the Project Portfolio page if you want to claim credit for them.
-
- After you are satisfied with the new results (i.e., results produced by running RepoSense locally), push the
config.jsonfile you added and/or the annotated code to your repo. We'll use that information the next time we run RepoSense (we run it at least once a week). - If you choose to annotate code, please annotate code chunks not smaller than a method. We do not grade code snippets smaller than a method.
- If you encounter any problem when doing the above or if you have questions, please post in the forum.
We recommend you ensure your code is RepoSense-compatible by v1.3
v1.3 Product
-
As before, move the product towards v2.0.
-
Do a
proper product release as described in the Developer Guide. Do some manual tests to ensure the jar file works.
v1.3 Documentation
v1.3 user guide should be updated to match the current version of the product. Reason: v1.3 will be subjected to a trial acceptance testing session
-
README page: Update to look like a real product (rather than a project for learning SE) if you haven't done so already. In particular, update the
Ui.pngto match the current product. -
User Guide: This document will be used by acceptance testers. Update to match the current version. In particular,
- Clearly indicate which features are not implemented yet e.g. tag those features with a
Coming in v2.0. - For those features already implemented, ensure their descriptions match the exact behavior of the product e.g. replace mockups with actual screenshots
- Clearly indicate which features are not implemented yet e.g. tag those features with a
-
Developer Guide: As before, update if necessary.
-
AboutUs page: Update to reflect current state of roles and responsibilities.
Submission: Must be included in the version tagged v1.3.
v1.3 Demo
- Do a quick demo of the main features using the jar file. Objective: demonstrate that the jar file works.
v1.3 Testing (aka Practical Exam Dry Run)
See info in the panel below:
Relevant: [
What: The v1.3 is subjected to a round of peer acceptance/system testing, also called the Practical Exam Dry Run as this round of testing will be similar to the graded
When, where: uses a 30 minute slot at the start of week 11 lecture
Objectives:
- Evaluate your manual testing skills, product evaluation skills, effort estimation skills
- Peer-evaluate your product design , implementation effort , documentation quality
When, where: Week 13 lecture
Grading:
- Your performance in the practical exam will be considered for your final grade (under the QA category and under Implementation category, about 10 marks in total).
- You will be graded based on your effectiveness as a tester (e.g., the percentage of the bugs you found, the nature of the bugs you found) and how far off your evaluation/estimates are from the evaluator consensus. Explanation: we understand that you have limited expertise in this area; hence, we penalize only if your inputs don't seem to be based on a sincere effort to test/evaluate.
- The bugs found in your product by others will affect your v1.4 marks. You will be given a chance to reject false-positive bug reports.
Preparation:
-
Ensure that you can access the relevant issue tracker given below:
-- for PE Dry Run (at v1.3): nus-cs2103-AY1819S1/pe-dry-run
-- for PE (at v1.4): nus-cs2103-AY1819S1/pe (will open only near the actual PE)- These are private repos!. If you cannot access the relevant repo, you may not have accepted the invitation to join the GitHub org used by the module. Go to https://github.com/orgs/nus-cs2103-AY1819S1/invitation to accept the invitation.
- If you cannot find the invitation, post in our forum.
-
Ensure you have access to a computer that is able to run module projects e.g. has the right Java version.
-
Have a good screen grab tool with annotation features so that you can quickly take a screenshot of a bug, annotate it, and post in the issue tracker.
- 💡 You can use Ctrl+V to paste a picture from the clipboard into a text box in GitHub issue tracker.
-
Charge your computer before coming to the PE session. The testing venue may not have enough charging points.
During:
- Take note of your team to test. It will be given to you by the teaching team (distributed via IVLE gradebook).
- Download from IVLE all files submitted by the team (i.e. jar file, User Guide, Developer Guide, and Project Portfolio Pages) into an empty folder.
- [~40 minutes] Test the product and report bugs as described below:
Testing instructions for PE and PE Dry Run
-
What to test:
- PE Dry Run (at v1.3):
- Test the product based on the User Guide (the UG is most likely accessible using the
helpcommand). - Do system testing first i.e., does the product work as specified by the documentation?. If there is time left, you can do acceptance testing as well i.e., does the product solve the problem it claims to solve?.
- Test the product based on the User Guide (the UG is most likely accessible using the
- PE (at v1.4):
- Test based on the Developer Guide (Appendix named Instructions for Manual Testing) and the User Guide. The testing instructions in the Developer Guide can provide you some guidance but if you follow those instructions strictly, you are unlikely to find many bugs. You can deviate from the instructions to probe areas that are more likely to have bugs.
- Do system testing only i.e., verify actual behavior against documented behavior. Do not do acceptance testing.
- PE Dry Run (at v1.3):
-
What not to test:
- Omit features that are driven by GUI inputs (e.g. buttons, menus, etc.) Reason: Only CLI-driven features can earn credit, as per given project constraints. Some features might have both a GUI-driven and CLI-driven ways to invoke them, in which case test only the CLI-driven way of invoking it.
- Omit feature that existed in AB-4.
-
These are considered bugs:
- Behavior differs from the User Guide
- A legitimate user behavior is not handled e.g. incorrect commands, extra parameters
- Behavior is not specified and differs from normal expectations e.g. error message does not match the error
- Problems in the User Guide e.g., missing/incorrect info
-
Where to report bugs: Post bug in the following issue trackers (not in the team's repo):
- PE Dry Run (at v1.3): nus-cs2103-AY1819S1/pe-dry-run.
- PE (at v1.4): nus-cs2103-AY1819S1/pe.
-
Bug report format:
- Post bugs as you find them (i.e., do not wait to post all bugs at the end) because the issue tracker will close exactly at the end of the allocated time.
- Do not use team ID in bug reports. Reason: to prevent others copying your bug reports
- Each bug should be a separate issue.
- Write good quality bug reports; poor quality or incorrect bug reports will not earn credit.
- Use a descriptive title.
- Give a good description of the bug with steps to reproduce and screenshots.
- Assign a severity to the bug report. Bug report without a priority label are considered
severity.Low(lower severity bugs earn lower credit):
Bug Severity labels:
severity.Low: A flaw that is unlikely to affect normal operations of the product. Appears only in very rare situations and causes a minor inconvenience only.severity.Medium: A flaw that causes occasional inconvenience to some users but they can continue to use the product.severity.High: A flaw that affects most users and causes major problems for users. i.e., makes the product almost unusable for most users.
-
About posting suggestions:
- PE Dry Run (at v1.3): You can also post suggestions on how to improve the product. 💡 Be diplomatic when reporting bugs or suggesting improvements. For example, instead of criticising the current behavior, simply suggest alternatives to consider.
- PE (at v1.4): Do not post suggestions.
-
If the product doesn't work at all: If the product fails catastrophically e.g., cannot even launch, you can test the fallback team allocated to you. But in this case you must inform us immediately after the session so that we can send your bug reports to the correct team.
-
[~50 minutes] Evaluate the following aspects. Note down your evaluation in a hard copy (as a backup). Submit via TEAMMATES.
-
A. Cohesiveness of product features []: Do the features fit together and match the stated target user and the value proposition?
unable to judge: You are unable to judge this aspect for some reason.low: One of these- target user is too general i.e. wider than AB4
- target user and/or value proposition not clear from the user guide
- features don't seem to fit together for the most part
medium: Some features fit together but some don't.high: All features fit together but the features are not very high value to the target user.excellent: The target user is clearly defined (not too general) and almost all new features are of high-value to the target user. i.e. the product is very attractive to the target user.
-
B. Quality of user docs []: Evaluate based on the parts of the user guide written by the person, as reproduced in the project portfolio. Evaluate from an end-user perspective.
unable to judge: Less than 1 page worth of UG content written by the student.low: Hard to understand, often inaccurate or missing important information.medium: Needs some effort to understand; some information is missing.high: Mostly easy to follow. Only a few areas need improvements.excellent: Easy to follow and accurate. Just enough information, visuals, examples etc. (not too much either). Understandable to the target end user.
-
C. Quality of developer docs []: Evaluate based on the developer docs cited/reproduced in the respective project portfolio page. Evaluate from the perspective of a new developer trying to understand how the features are implemented.
unable to judge: One of these- less than 0.5 pages worth of content.
- other problems in the document e.g. looks like included wrong content.
low: One of these- Very small amount of content (i.e., 0.5 - 1 page).
- Hardly any use to the reader (i.e., content doesn't make much sense or redundant).
- Uses ad-hoc diagrams where UML diagrams could have been used instead.
- Multiple notation errors in UML diagrams.
medium: Some diagrams, some descriptions, but does not help the reader that much e.g. overly complicated diagrams.high: Enough diagrams (at lest two kinds of UML diagrams used) and enough descriptions (about 2 pages worth) but explanations are not always easy to follow.excellent: Easy to follow. Just enough information (not too much). Minimum repetition of content/diagrams. Good use of diagrams to complement text descriptions. Easy to understand diagrams with just enough details rather than very complicated diagrams that are hard to understand.
-
D. Depth of feature []: Evaluate the feature done by the student for difficulty, depth, and completeness. Note: examples given below assume that AB4 did not have the commands
edit,undo, andredo.unable to judge: You are unable to judge this aspect for some reason.low: An easy feature e.g. make the existing find command case insensitive.medium: Moderately difficult feature, barely acceptable implementation e.g. an edit command that requires the user to type all fields, even the ones that are not being edited.high: One of the below- A moderately difficult feature but fully implemented e.g. an edit command that allows editing any field.
- A difficult feature with a reasonable implementation but some aspects are not covered undo/redo command that only allows a single undo/redo.
excellent: A difficult feature, all reasonable aspects are fully implemented undo/redo command that allows multiple undo/redo.
-
E. Amount of work []: Evaluate the amount of work, on a scale of 0 to 30.
- Consider this PR (
historycommand) as 5 units of effort which means this PR (undo/redocommand) is about 15 points of effort. Given that 30 points matches an effort twice as that needed for theundo/redofeature (which was given as an example of anAgrade project), we expect most students to be have efforts lower than 20. - Consider the main feature only. Exclude GUI inputs, but consider GUI outputs of the feature. Count all implementation/testing/documentation work as mentioned in that person's PPP. Also look at the actual code written by the person. We understand that it is not possible to know exactly which part of the code is for the main feature; make a best-guess judgement call based on the available info.
- Do not give a high value just to be nice. If your estimate is wildly inaccurate, it means you are unable to estimate the effort required to implement a feature in a project that you are supposed to know well at this point. You will lose marks if that is the case.
- Consider this PR (
-
Processing PE Bug Reports:
There will be a review period for you to respond to the bug reports you received.
Duration: The review period will start around 1 day after the PE (exact time to be announced) and will last until the following Wednesday midnight. However, you are recommended to finish this task ASAP, to minimize cutting into your exam preparation work.
Bug reviewing is recommended to be done as a team as some of the decisions need team consensus.
Instructions for Reviewing Bug Reports
-
First, don't freak out if there are lot of bug reports. Many can be duplicates and some can be false positives. In any case, we anticipate that all of these products will have some bugs and our penalty for bugs is not harsh. Furthermore, it depends on the severity of the bug. Some bug may not even be penalized.
-
Do not edit the subject or the description. Do not close bug reports. Your response (if any) should be added as a comment.
-
If the bug is reported multiple times, mark all copies EXCEPT one as duplicates using the
duplicatetag (if the duplicates have different severity levels, you should keep the one with the highest severity). In addition, use this technique to indicate which issue they are duplicates of. Duplicates can be omitted from processing steps given below. -
If a bug seems to be for a different product (i.e. wrongly assigned to your team), let us know (email prof).
-
Decide if it is a real bug and apply ONLY one of these labels.
Response Labels:
response.Accepted: You accept it as a bug.response.Rejected: What tester treated as a bug is in fact the expected behavior. The penalty for rejecting a bug using an unjustifiable explanation is higher than the penalty if the same bug was accepted. You can reject bugs that you inherited from AB4.response.CannotReproduce: You are unable to reproduce the behavior reported in the bug after multiple tries.response.IssueUnclear: The issue description is not clear.
- If applicable, decide the type of bug. Bugs without
type-are consideredtype-FunctionalityBugby default (which are liable to a heavier penalty):
Bug Type Labels:
type-FunctionalityBug: the bug is a flaw in how the product works.type-DocumentationBug: the bug is in the documentation.
- If you disagree with the original severity assigned to the bug, you may change it to the correct level, in which case add a comment justifying the change. All such changes will be double-checked by the teaching team and unreasonable lowering of severity will be penalized extra.:
Bug Severity labels:
severity.Low: A flaw that is unlikely to affect normal operations of the product. Appears only in very rare situations and causes a minor inconvenience only.severity.Medium: A flaw that causes occasional inconvenience to some users but they can continue to use the product.severity.High: A flaw that affects most users and causes major problems for users. i.e., makes the product almost unusable for most users.
-
Decide who should fix the bug. Use the
Assigneesfield to assign the issue to that person(s). There is no need to actually fix the bug though. It's simply an indication/acceptance of responsibility. If there is no assignee, we will distribute the penalty for that bug (if any) among all team members. -
Add an explanatory comment explaining your choice of labels and assignees.
Grading: Taking part in the PE dry run is strongly encouraged as it can affect your grade in the following ways.
- If the product you are allocated to test in the Practical Exam (at v1.4) had a very low bug count, we will consider your performance in PE dry run as well when grading the PE.
- PE dry run will help you practice for the actual PE.
- Taking part in the PE dry run will earn you participation points.
- There is no penalty for bugs reported in your product. Every bug you find is a win-win for you and the team whose product you are testing.
Objectives:
- To train you to do manual testing, bug reporting, bug
triaging, bug fixing, communicating with users/testers/developers, evaluating products etc. - To help you improve your product before the final submission.
Preparation:
-
Ensure that you can access the relevant issue tracker given below:
-- for PE Dry Run (at v1.3): nus-cs2103-AY1819S1/pe-dry-run
-- for PE (at v1.4): nus-cs2103-AY1819S1/pe (will open only near the actual PE)- These are private repos!. If you cannot access the relevant repo, you may not have accepted the invitation to join the GitHub org used by the module. Go to https://github.com/orgs/nus-cs2103-AY1819S1/invitation to accept the invitation.
- If you cannot find the invitation, post in our forum.
-
Ensure you have access to a computer that is able to run module projects e.g. has the right Java version.
-
Have a good screen grab tool with annotation features so that you can quickly take a screenshot of a bug, annotate it, and post in the issue tracker.
- 💡 You can use Ctrl+V to paste a picture from the clipboard into a text box in GitHub issue tracker.
-
Charge your computer before coming to the PE session. The testing venue may not have enough charging points.
During the session:
- Take note of your team to test. Distributed via IVLE gradebook and via email.
- Download the latest jar file from the team's GitHub page. Copy it to an empty folder.
- Confirm you are testing the allocated product by comparing the product UI with the UI screenshot sent via email.
Testing instructions for PE and PE Dry Run
-
What to test:
- PE Dry Run (at v1.3):
- Test the product based on the User Guide (the UG is most likely accessible using the
helpcommand). - Do system testing first i.e., does the product work as specified by the documentation?. If there is time left, you can do acceptance testing as well i.e., does the product solve the problem it claims to solve?.
- Test the product based on the User Guide (the UG is most likely accessible using the
- PE (at v1.4):
- Test based on the Developer Guide (Appendix named Instructions for Manual Testing) and the User Guide. The testing instructions in the Developer Guide can provide you some guidance but if you follow those instructions strictly, you are unlikely to find many bugs. You can deviate from the instructions to probe areas that are more likely to have bugs.
- Do system testing only i.e., verify actual behavior against documented behavior. Do not do acceptance testing.
- PE Dry Run (at v1.3):
-
What not to test:
- Omit features that are driven by GUI inputs (e.g. buttons, menus, etc.) Reason: Only CLI-driven features can earn credit, as per given project constraints. Some features might have both a GUI-driven and CLI-driven ways to invoke them, in which case test only the CLI-driven way of invoking it.
- Omit feature that existed in AB-4.
-
These are considered bugs:
- Behavior differs from the User Guide
- A legitimate user behavior is not handled e.g. incorrect commands, extra parameters
- Behavior is not specified and differs from normal expectations e.g. error message does not match the error
- Problems in the User Guide e.g., missing/incorrect info
-
Where to report bugs: Post bug in the following issue trackers (not in the team's repo):
- PE Dry Run (at v1.3): nus-cs2103-AY1819S1/pe-dry-run.
- PE (at v1.4): nus-cs2103-AY1819S1/pe.
-
Bug report format:
- Post bugs as you find them (i.e., do not wait to post all bugs at the end) because the issue tracker will close exactly at the end of the allocated time.
- Do not use team ID in bug reports. Reason: to prevent others copying your bug reports
- Each bug should be a separate issue.
- Write good quality bug reports; poor quality or incorrect bug reports will not earn credit.
- Use a descriptive title.
- Give a good description of the bug with steps to reproduce and screenshots.
- Assign a severity to the bug report. Bug report without a priority label are considered
severity.Low(lower severity bugs earn lower credit):
Bug Severity labels:
severity.Low: A flaw that is unlikely to affect normal operations of the product. Appears only in very rare situations and causes a minor inconvenience only.severity.Medium: A flaw that causes occasional inconvenience to some users but they can continue to use the product.severity.High: A flaw that affects most users and causes major problems for users. i.e., makes the product almost unusable for most users.
-
About posting suggestions:
- PE Dry Run (at v1.3): You can also post suggestions on how to improve the product. 💡 Be diplomatic when reporting bugs or suggesting improvements. For example, instead of criticising the current behavior, simply suggest alternatives to consider.
- PE (at v1.4): Do not post suggestions.
-
If the product doesn't work at all: If the product fails catastrophically e.g., cannot even launch, you can test the fallback team allocated to you. But in this case you must inform us immediately after the session so that we can send your bug reports to the correct team.
At the end of the project each student is required to submit a Project Portfolio Page.
-
Objective:
- For you to use (e.g. in your resume) as a well-documented data point of your SE experience
- For us to use as a data point to evaluate your,
- contributions to the project
- your documentation skills
-
Sections to include:
-
Overview: A short overview of your product to provide some context to the reader.
-
Summary of Contributions:
- Code contributed: Give a link to your code on Project Code Dashboard, which should be
https://nus-cs2103-ay1819s1.github.io/cs2103-dashboard/#=undefined&search=githbub_username_in_lower_case(replacegithbub_username_in_lower_casewith your actual username in lower case e.g.,johndoe). This link is also available in the Project List Page -- linked to the icon under your photo. - Main feature implemented: A summary of the main feature (the so called major enhancement) you implemented
- Other contributions:
- Other minor enhancements you did which are not related to your main feature
- Contributions to project management e.g., setting up project tools, managing releases, managing issue tracker etc.
- Evidence of helping others e.g. responses you posted in our forum, bugs you reported in other team's products,
- Evidence of technical leadership e.g. sharing useful information in the forum
- Code contributed: Give a link to your code on Project Code Dashboard, which should be
-
Contributions to the User Guide: Reproduce the parts in the User Guide that you wrote. This can include features you implemented as well as features you propose to implement.
The purpose of allowing you to include proposed features is to provide you more flexibility to show your documentation skills. e.g. you can bring in a proposed feature just to give you an opportunity to use a UML diagram type not used by the actual features. -
Contributions to the Developer Guide: Reproduce the parts in the Developer Guide that you wrote. Ensure there is enough content to evaluate your technical documentation skills and UML modelling skills. You can include descriptions of your design/implementations, possible alternatives, pros and cons of alternatives, etc.
-
If you plan to use the PPP in your Resume, you can also include your SE work outside of the module (will not be graded)
-
-
Format:
-
File name:
docs/team/githbub_username_in_lower_case.adoce.g.,docs/team/johndoe.adoc -
Follow the example in the AddressBook-Level4, but ignore the following two lines in it.
- Minor enhancement: added a history command that allows the user to navigate to previous commands using up/down keys.
- Code contributed: [Functional code] [Test code] {give links to collated code files}
-
💡 You can use the Asciidoc's
includefeature to include sections from the developer guide or the user guide in your PPP. Follow the example in the sample. -
It is assumed that all contents in the PPP were written primarily by you. If any section is written by someone else e.g. someone else wrote described the feature in the User Guide but you implemented the feature, clearly state that the section was written by someone else (e.g.
Start of Extract [from: User Guide] written by Jane Doe). Reason: Your writing skills will be evaluated based on the PPP -
Page limit: If you have more content than the limit given below, shorten (or omit some content) so that you do not exceed the page limit. Having too much content in the PPP will be viewed unfavorably during grading. Note: the page limits given below are after converting to PDF format. The actual amount of content you require is actually less than what these numbers suggest because the HTML → PDF conversion adds a lot of spacing around content.
Content Limit Overview + Summary of contributions 0.5-1 Contributions to the User Guide 1-3 Contributions to the Developer Guide 3-6 Total 5-10
-
After the session:
- We'll transfer the relevant bug reports to your repo over the weekend. Once you have received the bug reports for your product, it is up to you to decide whether you will act on reported issues before the final submission v1.4. For some issues, the correct decision could be to reject or postpone to a version beyond v1.4.
- You can post in the issue thread to communicate with the tester e.g. to ask for more info, etc. However, the tester is not obliged to respond.
- 💡 Do not argue with the issue reporter to try to convince that person that your way is correct/better. If at all, you can gently explain the rationale for the current behavior but do not waste time getting involved in long arguments. If you think the suggestion/bug is unreasonable, just thank the reporter for their view and close the issue.
Outcomes
Design
W11.1 Can apply some more design patterns
W11.1a Can explain the Model View Controller (MVC) design pattern
Design → Design Patterns → MVC Pattern →
Context
Most applications support storage/retrieval of information, displaying of information to the user (often via multiple UIs having different formats), and changing stored information based on external inputs.
Problem
The high coupling that can result from the interlinked nature of the features described above.
Solution
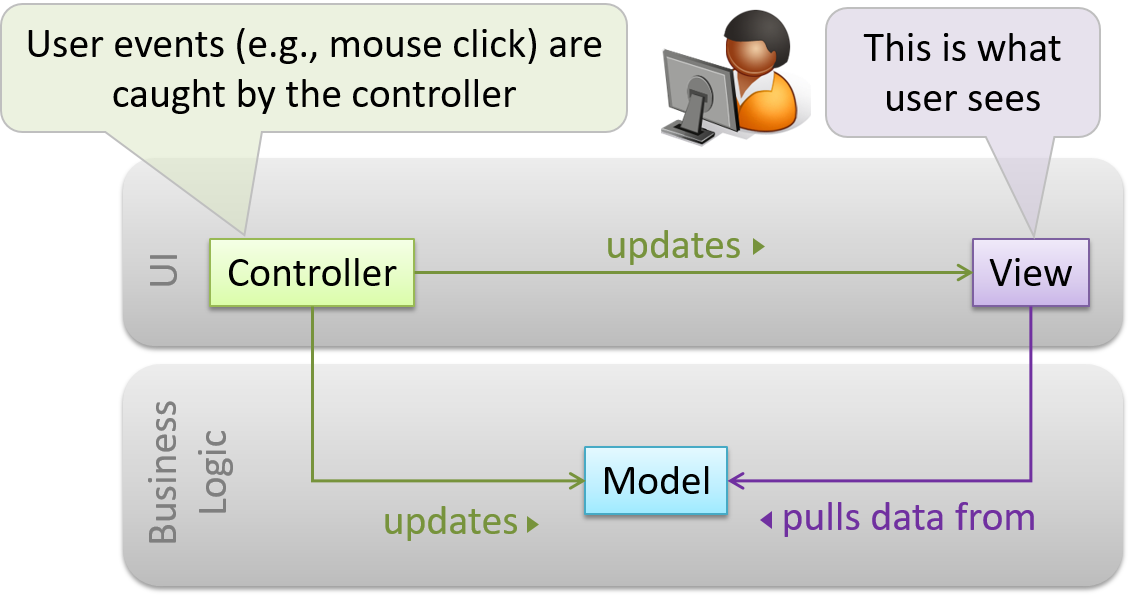
Decouple data, presentation, and control logic of an application by separating them into three different components: Model, View and Controller.
- View: Displays data, interacts with the user, and pulls data from the model if necessary.
- Controller: Detects UI events such as mouse clicks, button pushes and takes follow up action. Updates/changes the model/view when necessary.
- Model: Stores and maintains data. Updates views if necessary.
The relationship between the components can be observed in the diagram below. Typically, the UI is the combination of view and controller.
Given below is a concrete example of MVC applied to a student management system. In this scenario, the user is retrieving data of one student.
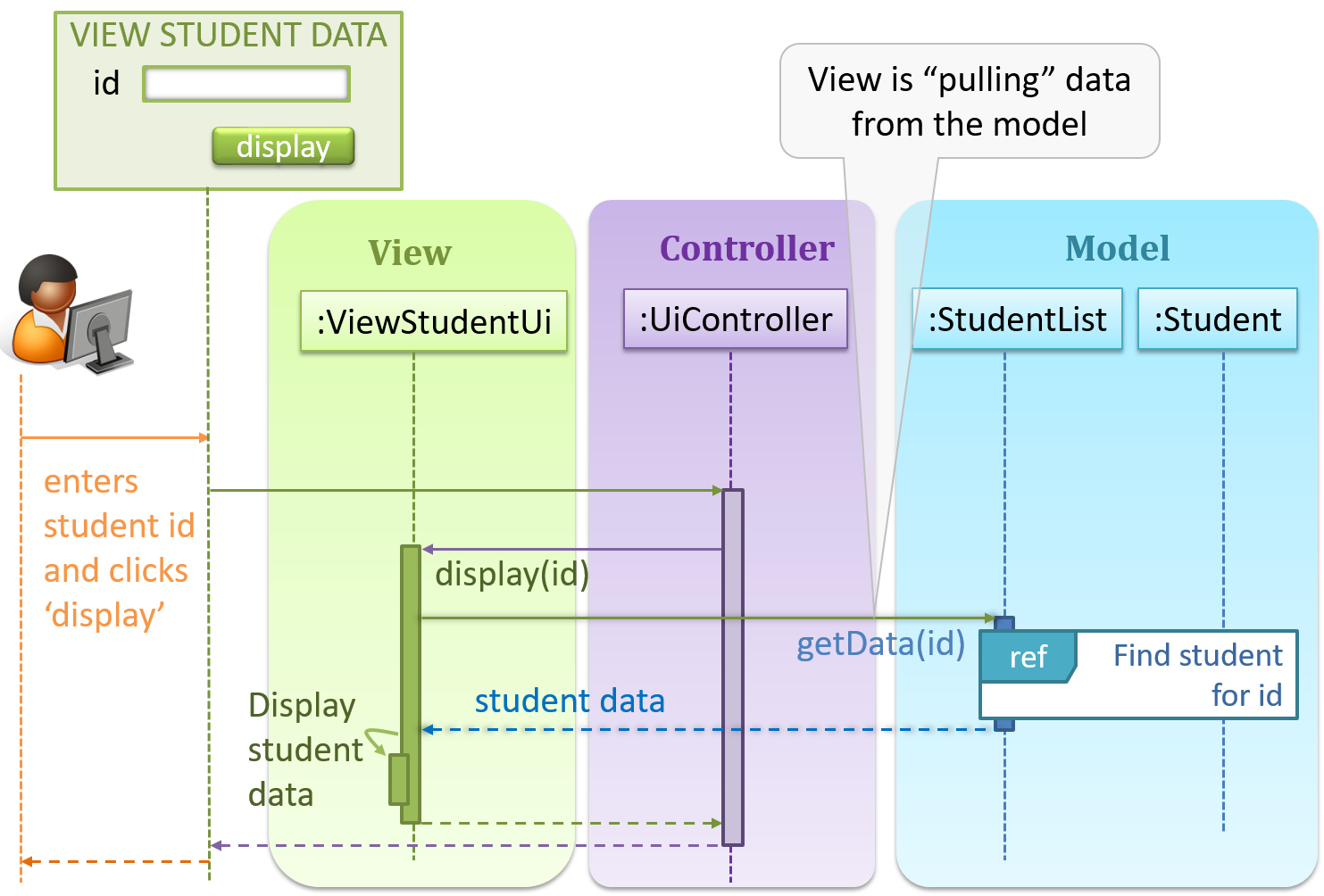
In the diagram above, when the user clicks on a button using the UI, the ‘click’ event is caught and handled by the UiController. The ref frame indicates that the interactions within that frame have been extracted out to another separate sequence diagram.
Note that in a simple UI where there’s only one view, Controller and View can be combined as one class.
There are many variations of the MVC model used in different domains. For example, the one used in a desktop GUI could be different from the one used in a Web application.
Evidence:
Explain relevance of the pattern to the project.
W11.1b Can explain the Observer design pattern
Design → Design Patterns → Observer Pattern →
Context
An object (possibly, more than one) is interested to get notified when a change happens to another object. That is, some objects want to ‘observe’ another object.
Consider this scenario from the a student management system where the user is adding a new student to the system.
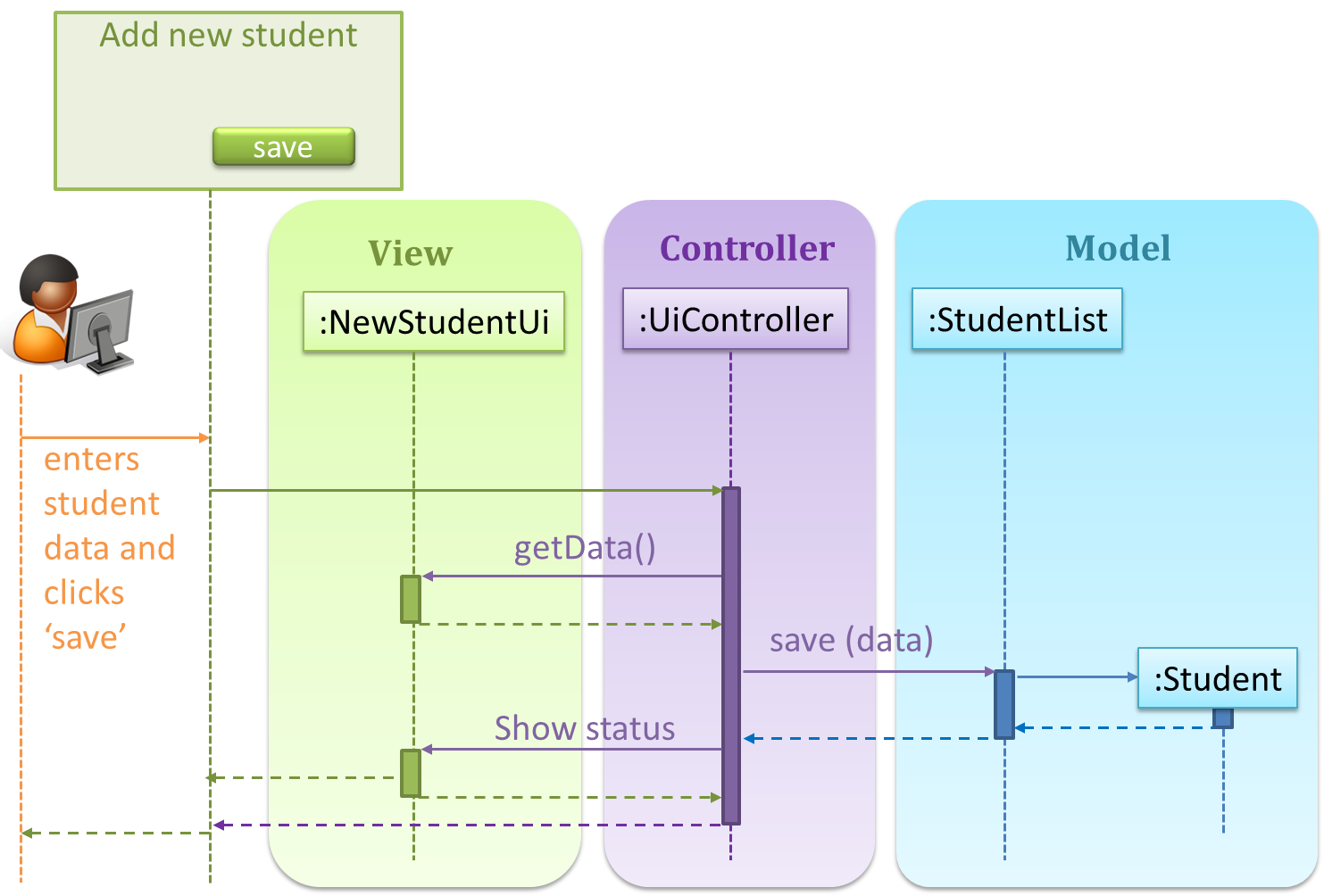
Now, assume the system has two additional views used in parallel by different users:
StudentListUi: that accesses a list of students andStudentStatsUi: that generates statistics of current students.
When a student is added to the database using NewStudentUi shown above, both StudentListUi and StudentStatsUi should get updated automatically, as shown below.
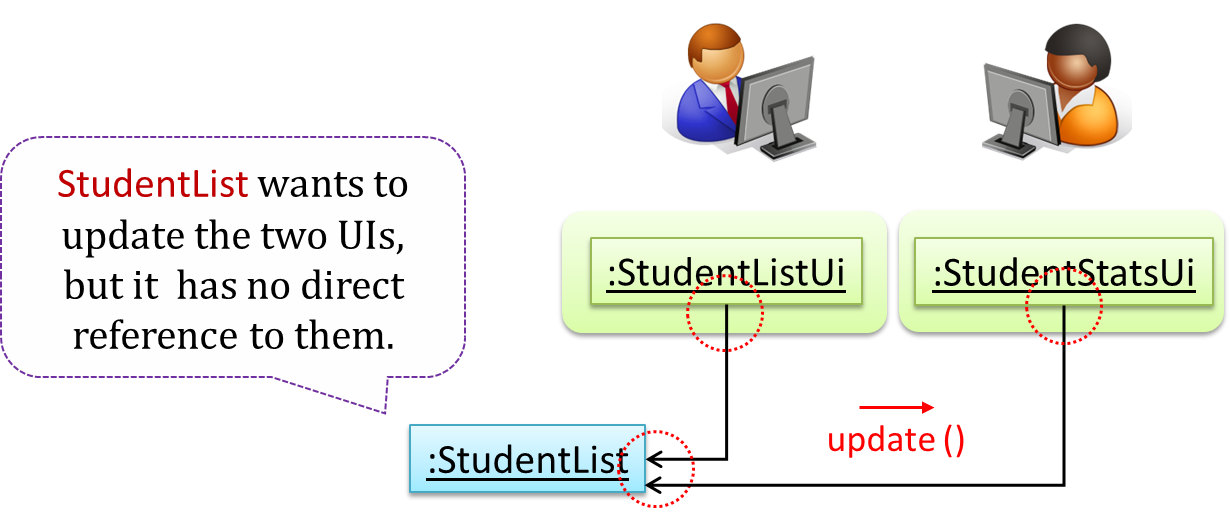
However, the StudentList object has no knowledge about StudentListUi and StudentStatsUi (note the direction of the navigability) and has no way to inform those objects. This is an example of the type of problem addressed by the Observer pattern.
Problem
The ‘observed’ object does not want to be coupled to objects that are ‘observing’ it.
Solution
Force the communication through an interface known to both parties.
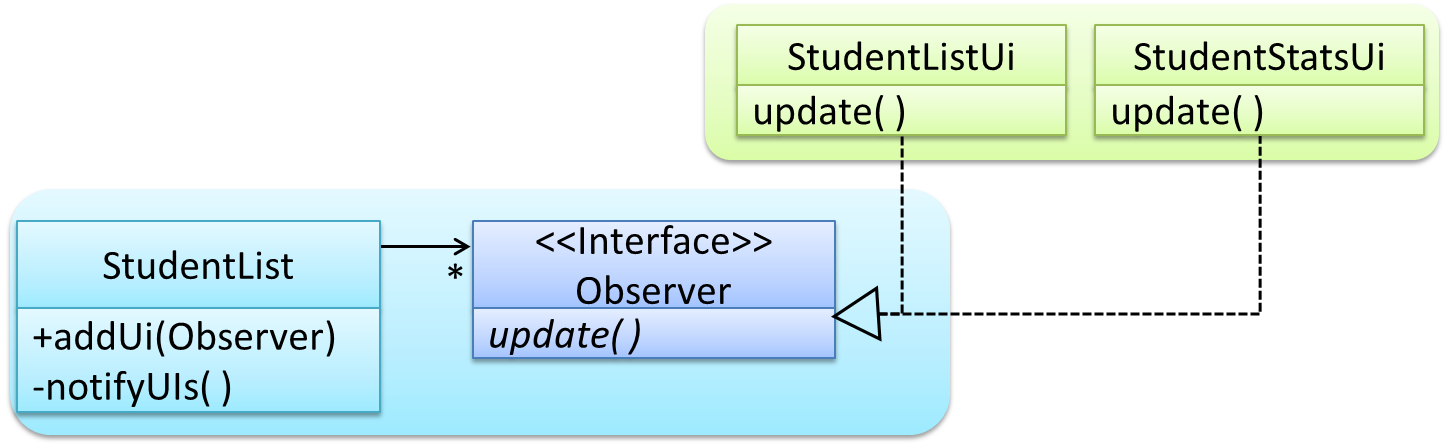
Here is the Observer pattern applied to the student management system.
During the initialization of the system,
-
First, create the relevant objects.
StudentList studentList = new StudentList(); StudentListUi listUi = new StudentListUi(); StudentStatusUi statusUi = new StudentStatsUi(); -
Next, the two UIs indicate to the
StudentListthat they are interested in being updated wheneverStudentListchanges. This is also known as ‘subscribing for updates’.studentList.addUi(listUi); studentList.addUi(statusUi); -
Within the
addUioperation ofStudentList, all Observer objects subscribers are added to an internal data structure calledobserverList.//StudentList class public void addUi(Observer o) { observerList.add(o); }
Now, whenever the data in StudentList changes (e.g. when a new student is added to the StudentList),
-
All interested observers are updated by calling the
notifyUIsoperation.//StudentList class public void notifyUIs() { //for each observer in the list for(Observer o: observerList){ o.update(); } } -
UIs can then pull data from the
StudentListwhenever theupdateoperation is called.//StudentListUI class public void update() { //refresh UI by pulling data from StudentList }Note that
StudentListis unaware of the exact nature of the two UIs but still manages to communicate with them via an intermediary.
Here is the generic description of the observer pattern:

<<Observer>>is an interface: any class that implements it can observe an<<Observable>>. Any number of<<Observer>>objects can observe (i.e. listen to changes of) the<<Observable>>object.- The
<<Observable>>maintains a list of<<Observer>>objects.addObserver(Observer)operation adds a new<<Observer>>to the list of<<Observer>>s. - Whenever there is a change in the
<<Observable>>, thenotifyObservers()operation is called that will call theupdate()operation of all<<Observer>>sin the list.
In a GUI application, how is the Controller notified when the “save” button is clicked? UI frameworks such as JavaFX has inbuilt support for the Observer pattern.
Explain how polymorphism is used in the Observer pattern.

With respect to the general form of the Observer pattern given above, when the Observable object invokes the notifyObservers() method, it is treating all ConcreteObserver objects as a general type called Observer and calling the update() method of each of them. However, the update() method of each ConcreteObserver could potentially show different behavior based on its actual type. That is, update() method shows polymorphic behavior.
In the example given below, the notifyUIs operation can result in StudentListUi and StudentStatsUi changing their views in two different ways.
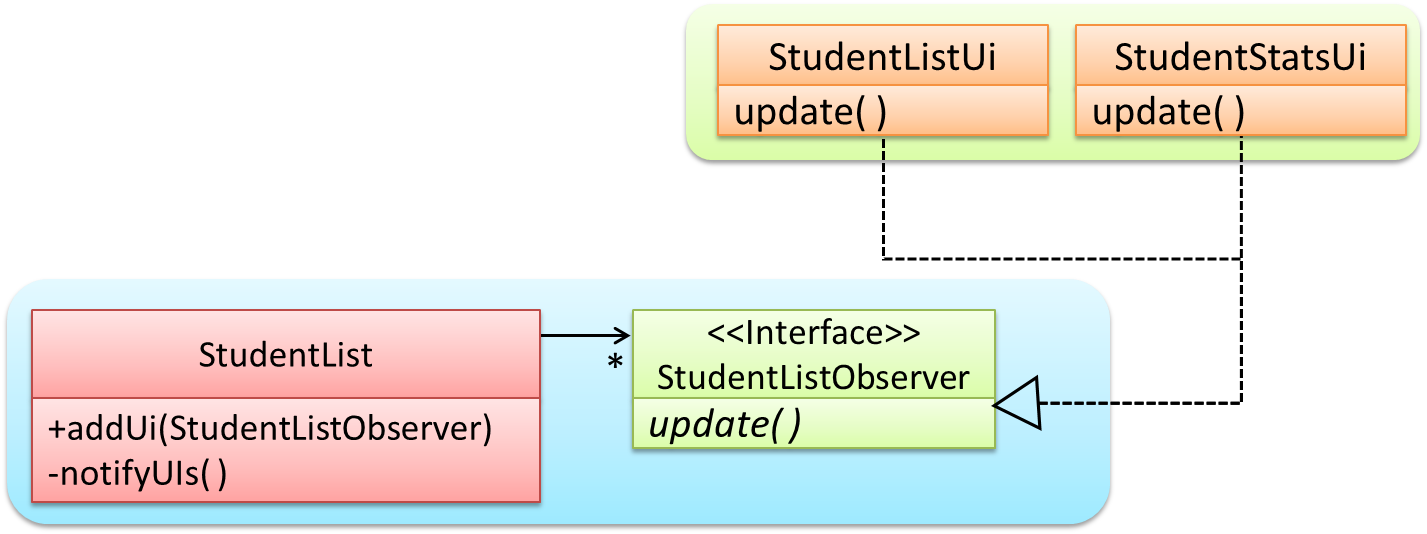
The Observer pattern can be used when we want one object to initiate an activity in another object without having a direct dependency from the first object to the second object.
True
Explanation: Yes. For example, when applying the Observer pattern to an MVC structure, Views can get notified and update themselves about a change to the Model without the Model having to depend on the Views.
Evidence:
Explain relevance of the pattern to the project.
W11.1c Can recognize some of the GoF design patterns
Design → Design Patterns →
The most famous source of design patterns is the "Gang of Four" (GoF) book which contains 23 design patterns divided into three categories:
- Creational: About object creation. They separate the operation of an application from how its objects are created.
- Abstract Factory, Builder, Factory Method, Prototype, Singleton
- Structural: About the composition of objects into larger structures while catering for future extension in structure.
- Adapter, Bridge, Composite, Decorator, Façade, Flyweight, Proxy
- Behavioral: Defining how objects interact and how responsibility is distributed among them.
- Chain of Responsibility, Command, Interpreter, Template Method, Iterator, Mediator, Memento, Observer, State, Strategy, Visitor
Evidence:
Name a few GoF patterns not covered in the module.
W11.2 Can optimize the use of design patterns
W11.2a Can combine multiple patterns to fit a context
Design → Design Patterns →
Design patterns are usually embedded in a larger design and sometimes applied in combination with other design patterns.
Let us look at a case study that shows how design patterns are used in the design of a class structure for a Stock Inventory System (SIS) for a shop. The shop sells appliances, and accessories for the appliances. SIS simply stores information about each item in the store.
Use Cases:
- Create a new item
- View information about an item
- Modify information about an item
- View all available accessories for a given appliance
- List all items in the store
SIS can be accessed using multiple terminals. Shop assistants use their own terminals to access SIS, while the shop manager’s terminal continuously displays a list of all items in store. In the future, it is expected that suppliers of items use their own applications to connect to SIS to get real-time information about current stock status. User authentication is not required for the current version, but may be required in the future.
A step by step explanation of the design is given below. Note that this is one out of many possible designs. Design patterns are also applied where appropriate.
A StockItem can be an Appliance or an Accessory.
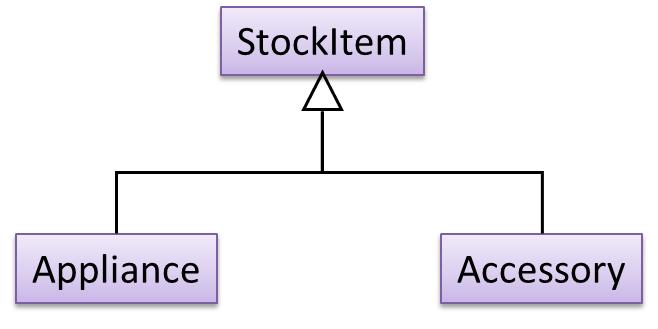
To track that each Accessory is associated with the correct Appliance, consider the following alternative class structures.
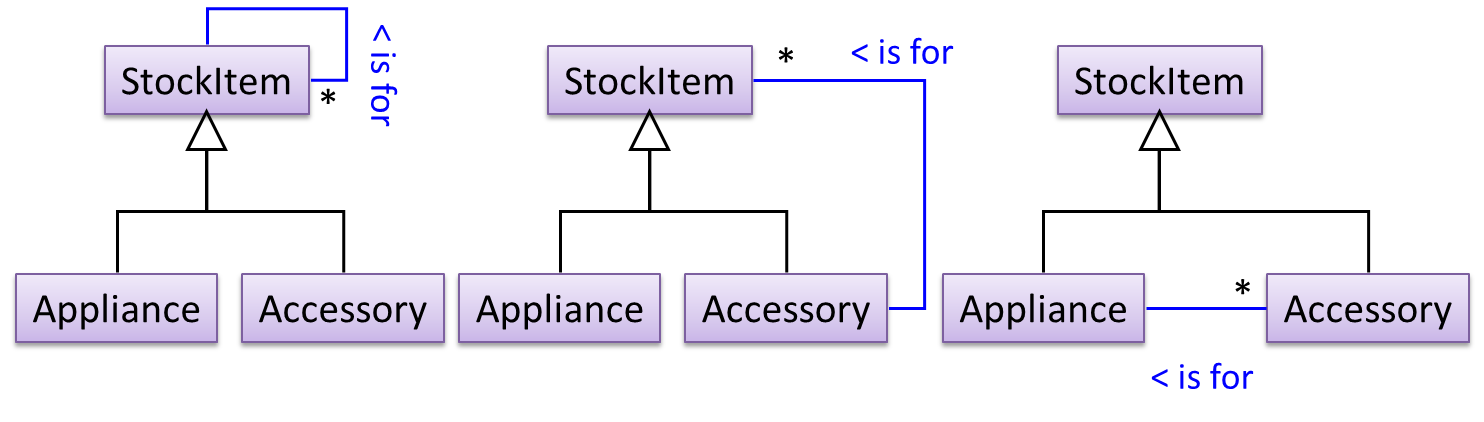
The third one seems more appropriate (the second one is suitable if accessories can have accessories). Next, consider between keeping a list of Appliances, and a list of StockItems. Which is more appropriate?
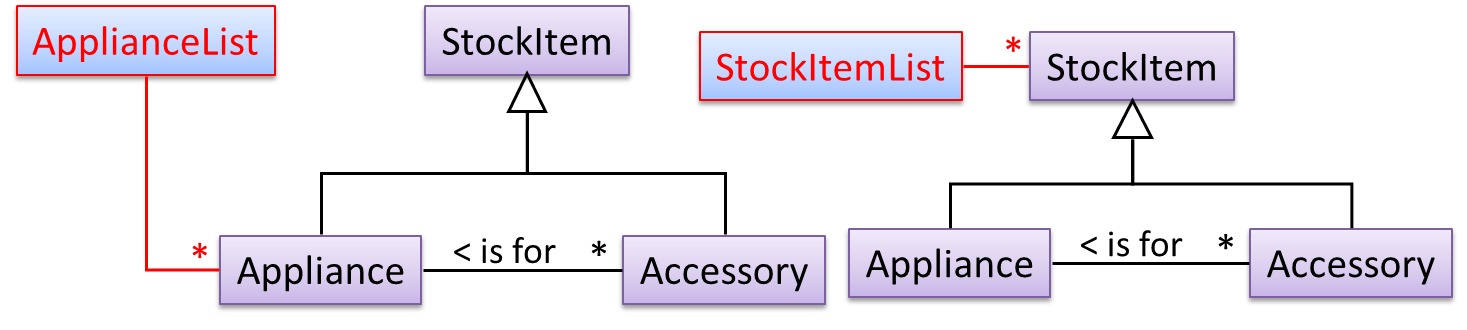
The latter seems more suitable because it can handle both appliances and accessories the same way. Next, an abstraction occurrence pattern is applied to keep track of StockItems.
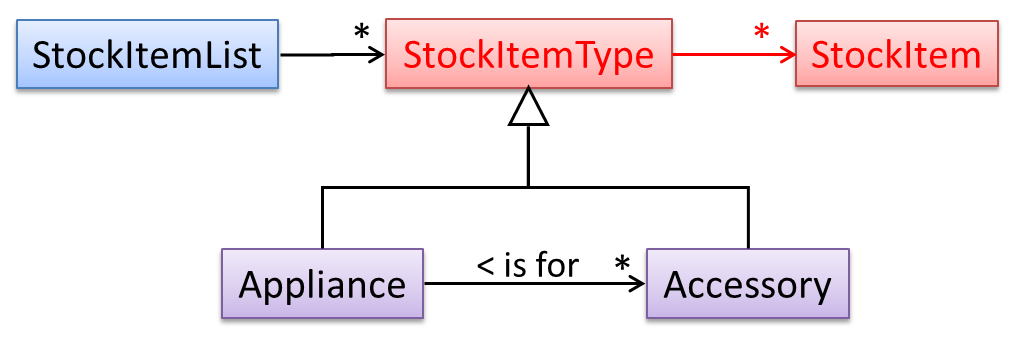
Note the inclusion of navigabilities. Here’s a sample object diagram based on the class model created thus far.
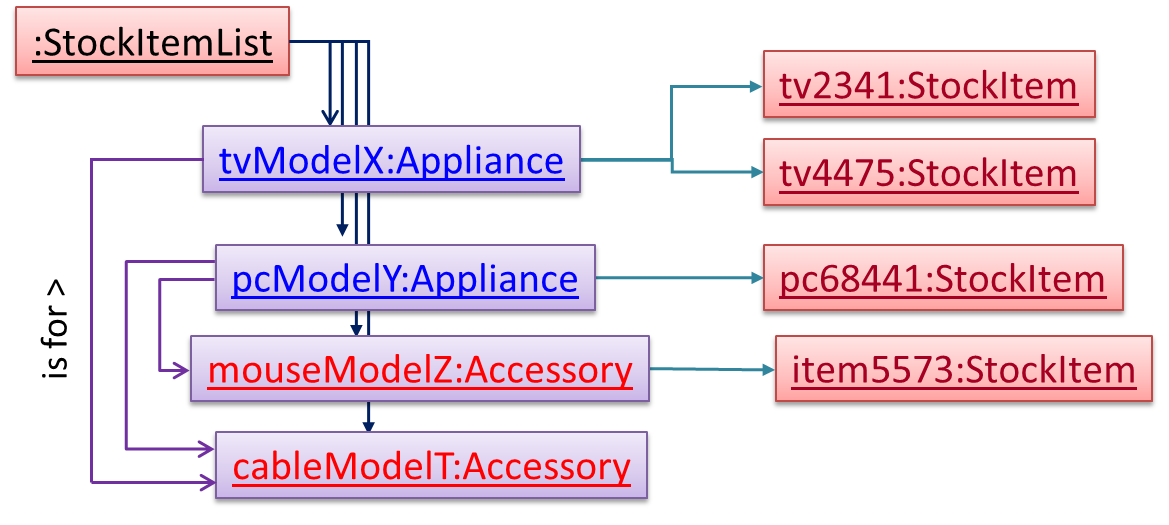
Next, apply the façade pattern to shield the SIS internals from the UI.
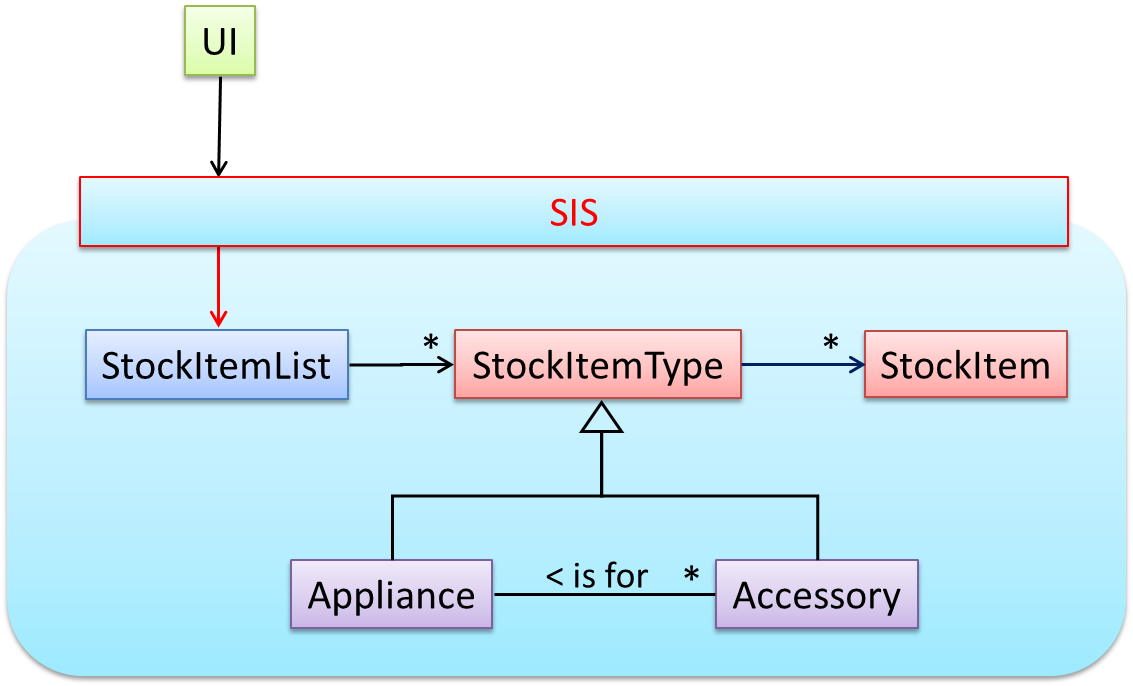
As UI consists of multiple views, the MVC pattern is applied here.
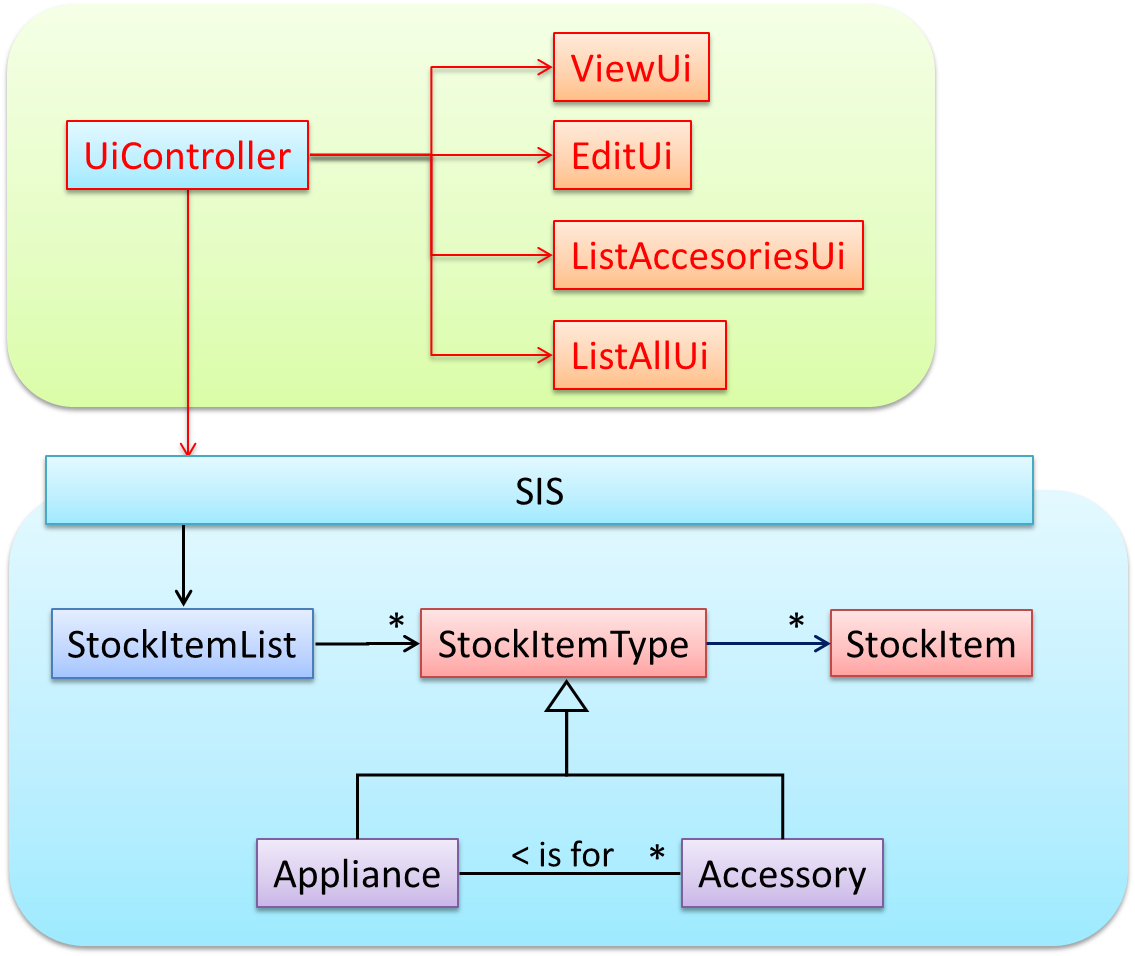
Some views need to be updated when the data change; apply the Observer pattern here.
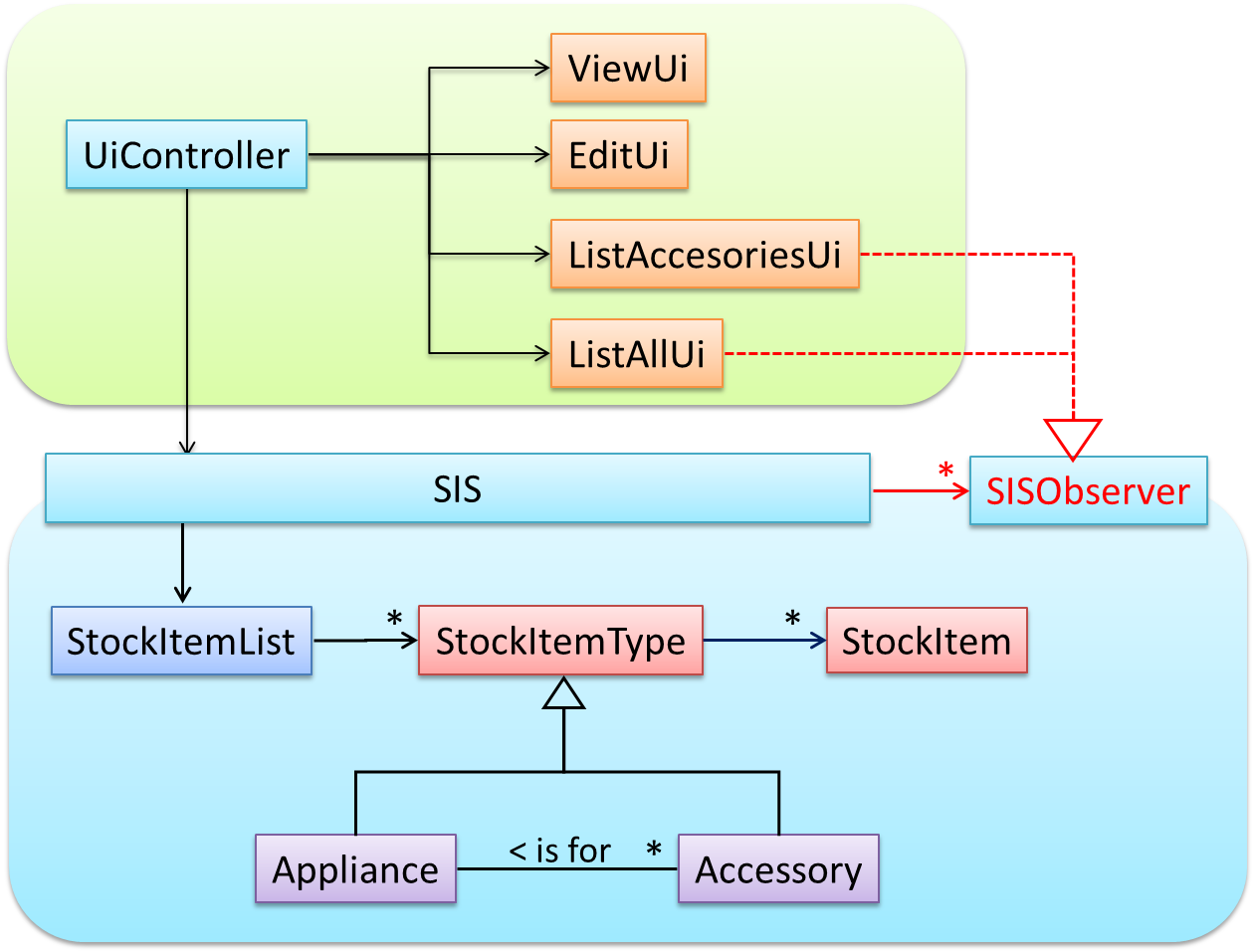
In addition, the Singleton pattern can be applied to the façade class.
Evidence:
Give an example of combining patterns.
W11.2b Can explain pros and cons of design patterns
Design → Design Patterns →
Design pattern provides a high-level vocabulary to talk about design.
Someone can say 'apply Observer pattern here' instead of having to describe the mechanics of the solution in detail.
Knowing more patterns is a way to become more ‘experienced’. Aim to learn at least the context and the problem of patterns so that when you encounter those problems you know where to look for a solution.
Some patterns are domain-specific e.g. patterns for distributed applications, some are created in-house e.g. patterns in the company/project and some can be self-created e.g. from past experience.
Be careful not to overuse patterns. Do not throw patterns at a problem at every opportunity. Patterns come with overhead such as adding more classes or increasing the levels of abstraction. Use them only when they are needed. Before applying a pattern, make sure that:
- there is substantial improvement in the design, not just superficial.
- the associated tradeoffs are carefully considered. There are times when a design pattern is not appropriate (or an overkill).
Evidence:
Take an example patterns in the project and explain its benefits and costs.
W11.2c Can differentiate between design patterns and principles
Design → Design Patterns →
W11.2d Can explain how patterns exist beyond software design domain
Design → Design Patterns →
The notion of capturing design ideas as "patterns" is usually attributed to Christopher Alexander. He is a building architect noted for his theories about design. His book Timeless way of building talks about "design patterns" for constructing buildings.
Here is a sample pattern from that book:
When a room has a window with a view, the window becomes a focal point: people are attracted to the window and want to look through it. The furniture in the room creates a second focal point: everyone is attracted toward whatever point the furniture aims them at (usually the center of the room or a TV). This makes people feel uncomfortable. They want to look out the window, and toward the other focus at the same time. If you rearrange the furniture, so that its focal point becomes the window, then everyone will suddenly notice that the room is much more “comfortable”
Apparently, patterns and anti-patterns are found in the field of building architecture. This is because they are general concepts applicable to any domain, not just software design. In software engineering, there are many general types of patterns: Analysis patterns, Design patterns, Testing patterns, Architectural patterns, Project management patterns, and so on.
In fact, the abstraction occurrence pattern is more of an analysis pattern than a design pattern, while MVC is more of an architectural pattern.
New patterns can be created too. If a common problem needs to be solved frequently that leads to a non-obvious and better solution, it can be formulated as a pattern so that it can be reused by others. However, don’t reinvent the wheel; the pattern might already exist.
Here are some common elements of a design pattern: Name, Context, Problem, Solution, Anti-patterns (optional), Consequences (optional), other useful information (optional).
Using similar elements, describe a pattern that is not a design pattern. It must be a pattern you have noticed, not a pattern already documented by others. You may also give a pattern not related to software.
Some examples:
- A pattern for testing textual UIs.
- A pattern for striking a good bargain at a mall such as Sim-Lim Square.
Evidence:
Give example patterns from other domains.
W11.3 Can explain some UML models
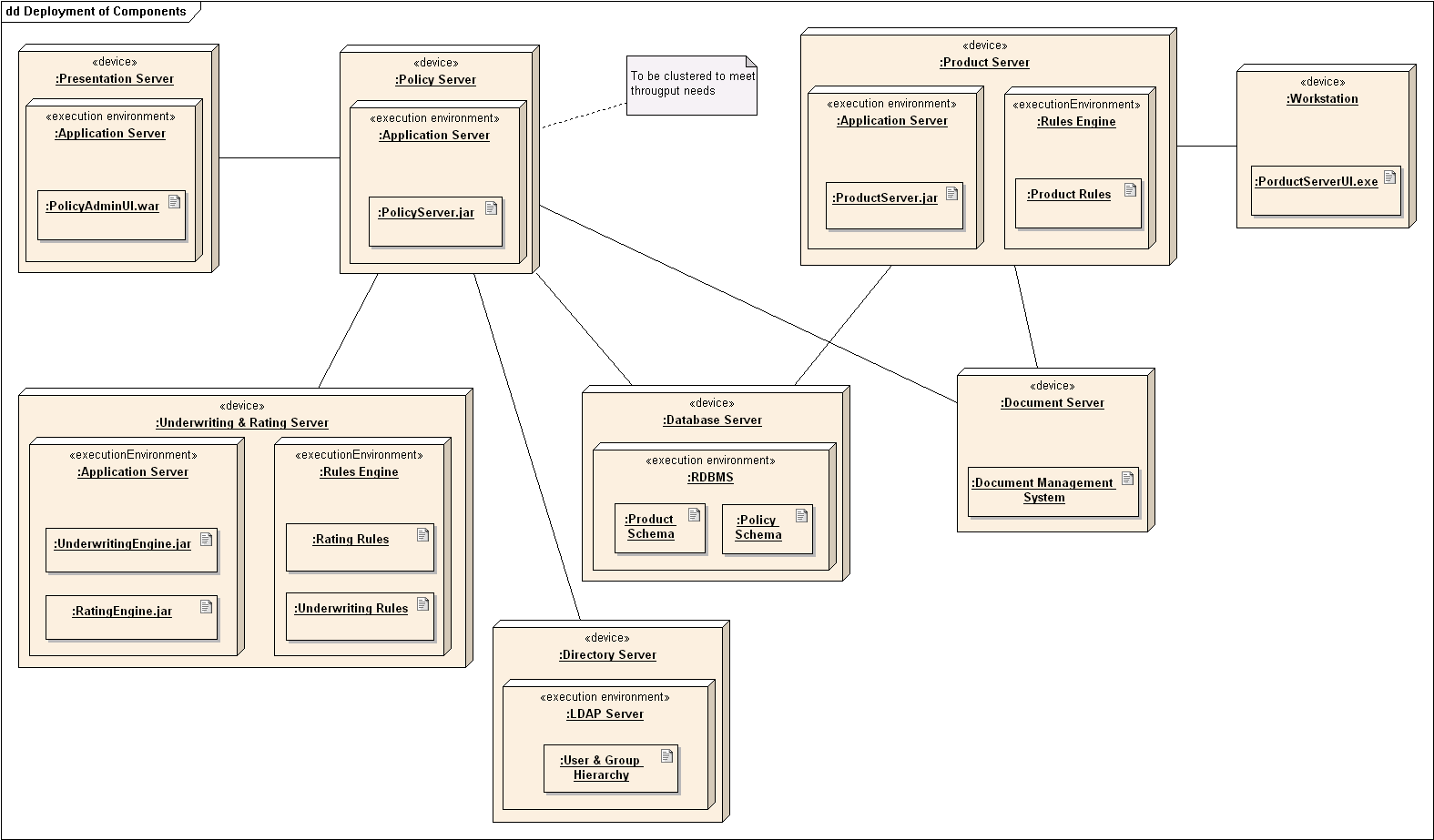
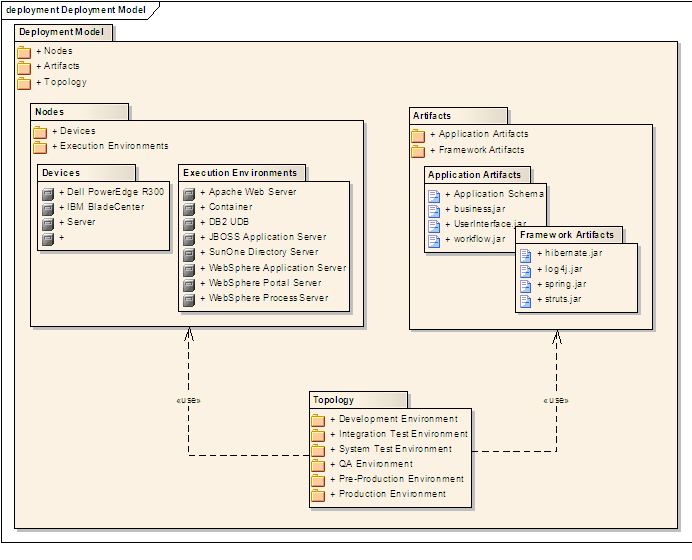
W11.3a Can explain deployment diagrams
Design → Modelling → Modelling Structure
A deployment diagram shows a system's physical layout, revealing which pieces of software run on which pieces of hardware.
An example deployment diagram:
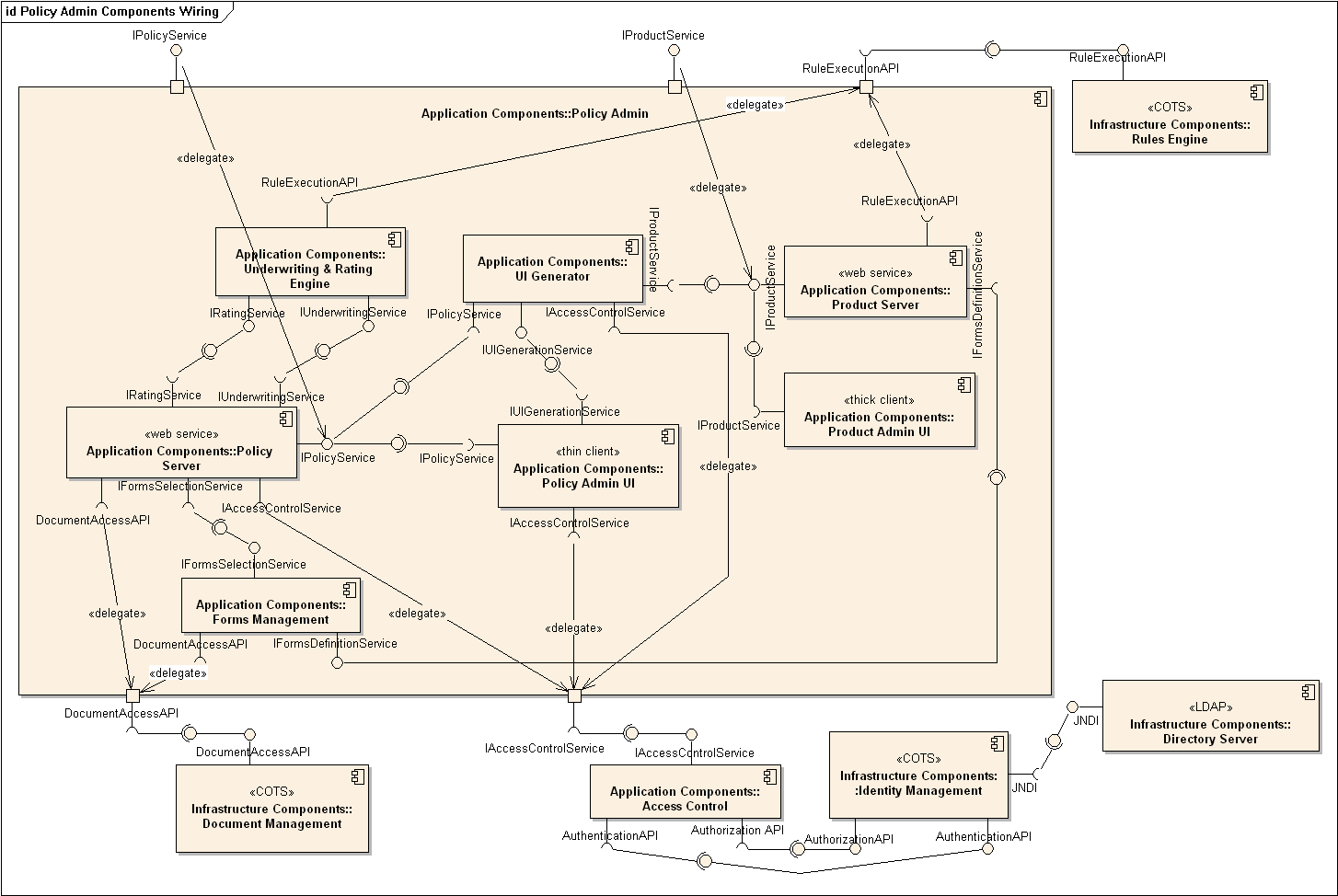
W11.3b Can explain component diagrams
Design → Modelling → Modelling Structure
A component diagram is used to show how a system is divided into components and how they are connected to each other through interfaces.
An example component diagram:
W11.3c Can explain package diagrams
Design → Modelling → Modelling Structure
A package diagram shows packages and their dependencies. A package is a grouping construct for grouping UML elements (classes, use cases, etc.).
Here is an example package diagram:
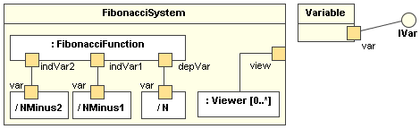
W11.3d Can explain composite structure diagrams
Design → Modelling → Modelling Structure
A composite structure diagram hierarchically decomposes a class into its internal structure.
Here is an example composite structure diagram:
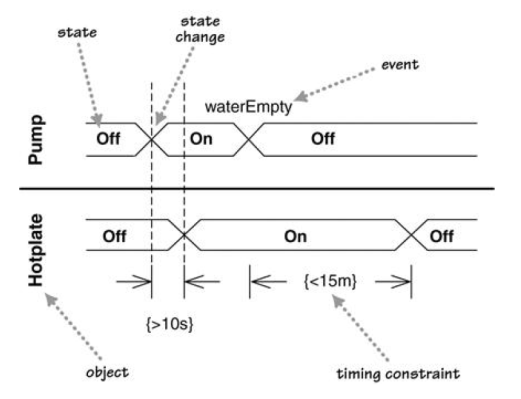
W11.3e Can explain timing diagrams
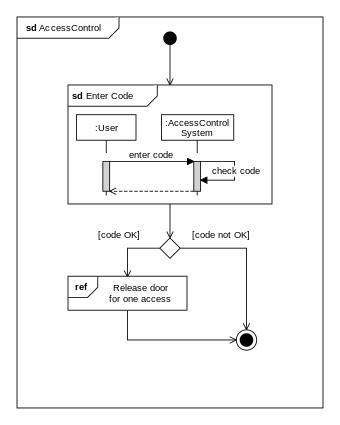
W11.3f Can explain interaction overview diagrams
Design → Modelling → Modelling Behaviors
An Interaction overview diagrams is a combination of activity diagrams and sequence diagrams.
An example:
W11.3g Can explain communication diagrams
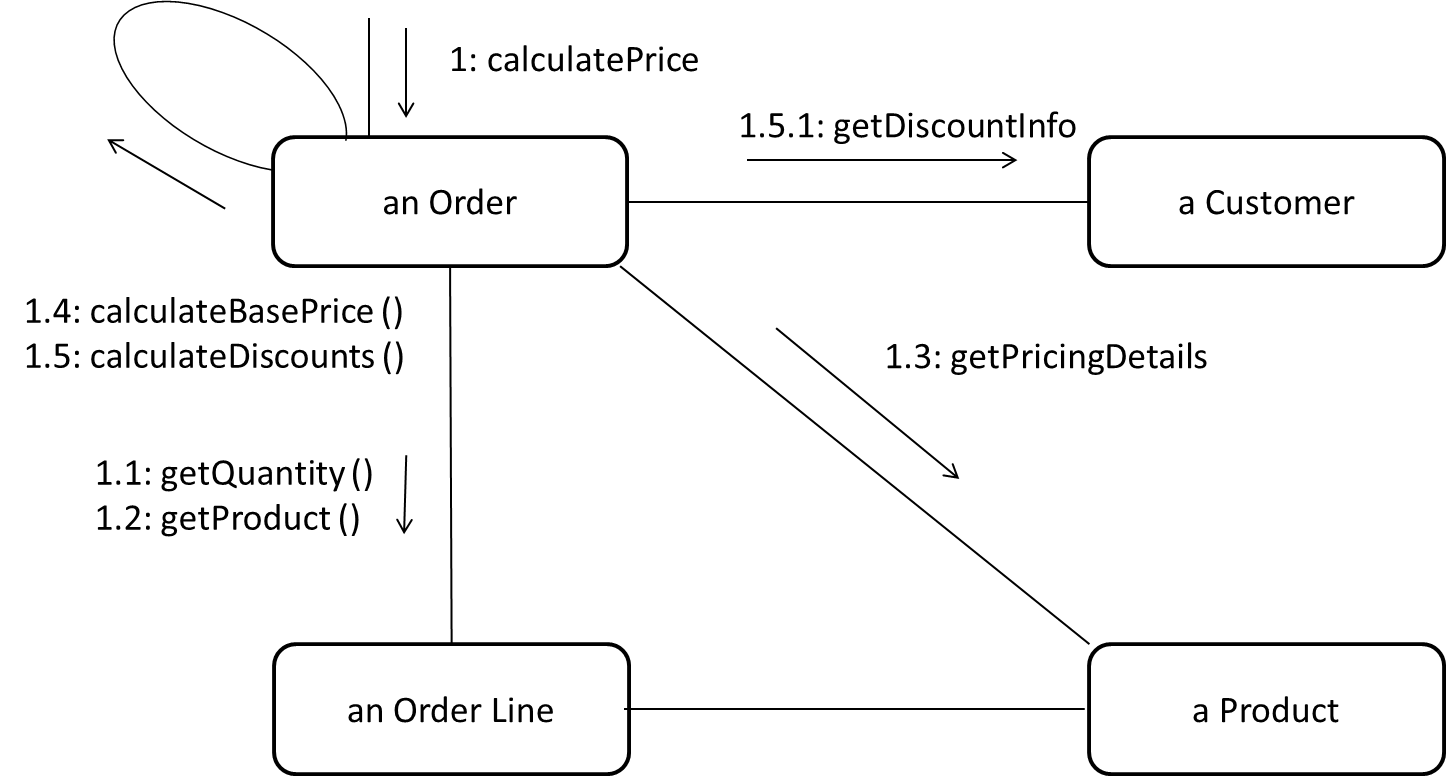
W11.3h Can explain state machine diagrams
Design → Modelling → Modelling Behaviors
A State Machine Diagram models state-dependent behavior.
Consider how a CD player responds when the “eject CD” button is pushed:
- If the CD tray is already open, it does nothing.
- If the CD tray is already in the process of opening (opened half-way), it continues to open the CD tray.
- If the CD tray is closed and the CD is being played, it stops playing and opens the CD tray.
- If the CD tray is closed and CD is not being played, it simply opens the CD tray.
- If the CD tray is already in the process of closing (closed half-way), it waits until the CD tray is fully closed and opens it immediately afterwards.
What this means is that the CD player’s response to pushing the “eject CD” button depends on what it was doing at the time of the event. More generally, the CD player’s response to the event received depends on its internal state. Such a behavior is called a state-dependent behavior.
Often, state-dependent behavior displayed by an object in a system is simple enough that it needs no extra attention; such a behavior can be as simple as a conditional behavior like if x>y, then x=x-y.
Occasionally, objects may exhibit state-dependent behavior that is complex enough such that it needs to be captured into a separate model. Such state-dependent behavior can be modelled using UML state machine diagrams (SMD for short, sometimes also called ‘state charts’, ‘state diagrams’ or ‘state machines’).
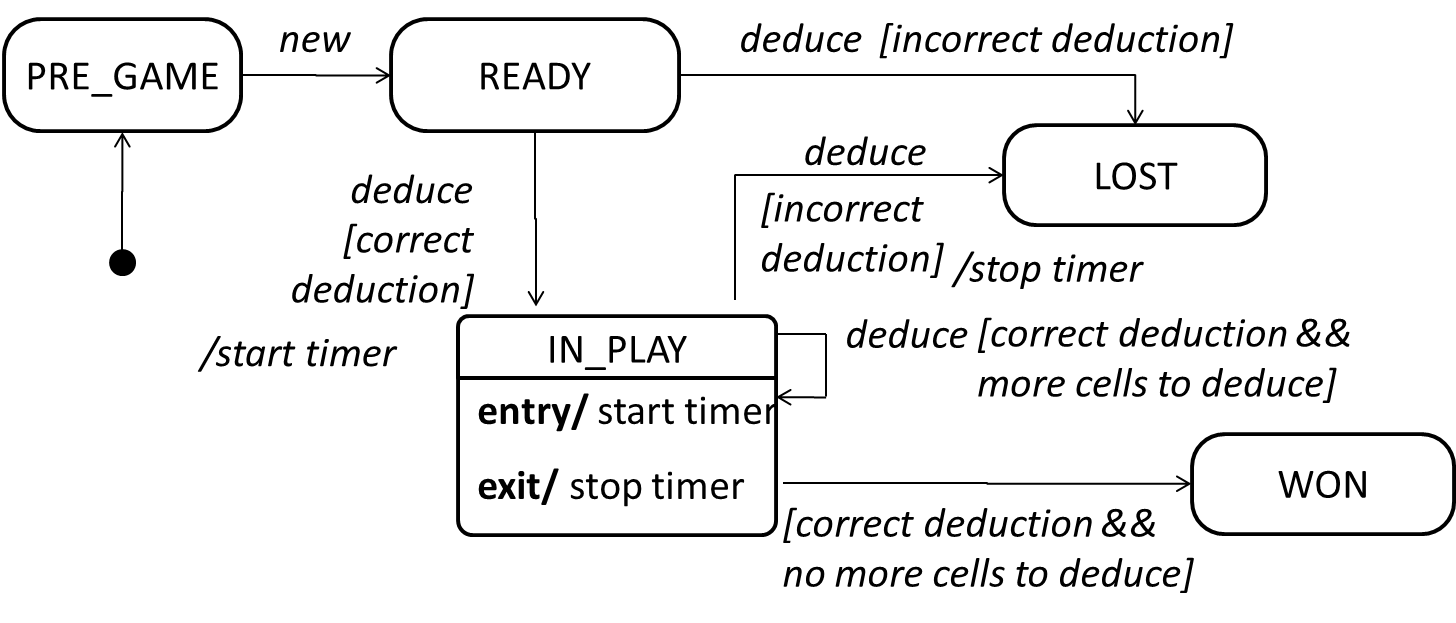
An SMD views the life-cycle of an object as consisting of a finite number of states where each state displays a unique behavior pattern. An SMD captures information such as the states an object can be in, during its lifetime, and how the object responds to various events while in each state and how the object transits from one state to another. In contrast to sequence diagrams that capture object behavior one scenario at a time, SMDs capture the object’s behavior over its full life cycle.
An SMD for the Minesweeper game.
Quality Assurance
W11.4 Can apply heuristics to combine multiple test inputs
W11.4a Can explain the need for strategies to combine test inputs
Quality Assurance → Test Case Design → Combining Test Inputs →
An SUT can take multiple inputs. You can select values for each input (using equivalence partitioning, boundary value analysis, or some other technique).
an SUT that takes multiple inputs and some values chosen as values for each input:
- Method to test:
calculateGrade(participation, projectGrade, isAbsent, examScore) - Values to test:
Input valid values to test invalid values to test participation 0, 1, 19, 20 21, 22 projectGrade A, B, C, D, F isAbsent true, false examScore 0, 1, 69, 70, 71, 72
Testing all possible combinations is effective but not efficient. If you test all possible combinations for the above example, you need to test 6x5x2x6=360 cases. Doing so has a higher chance of discovering bugs (i.e. effective) but the number of test cases can be too high (i.e. not efficient). Therefore, we need smarter ways to combine test inputs that are both effective and efficient.
W11.4b Can explain some basic test input combination strategies
Quality Assurance → Test Case Design → Combining Test Inputs →
Given below are some basic strategies for generating a set of test cases by combining multiple test input combination strategies.
Let's assume the SUT has the following three inputs and you have selected the given values for testing:
SUT: foo(p1 char, p2 int, p3 boolean)
Values to test:
| Input | Values |
|---|---|
| p1 | a, b, c |
| p2 | 1, 2, 3 |
| p3 | T, F |
The all combinations strategy generates test cases for each unique combination of test inputs.
the strategy generates 3x3x2=18 test cases
| Test Case | p1 | p2 | p3 |
|---|---|---|---|
| 1 | a | 1 | T |
| 2 | a | 1 | F |
| 3 | a | 2 | T |
| ... | ... | ... | ... |
| 18 | c | 3 | F |
The at least once strategy includes each test input at least once.
this strategy generates 3 test cases.
| Test Case | p1 | p2 | p3 |
|---|---|---|---|
| 1 | a | 1 | T |
| 2 | b | 2 | F |
| 3 | c | 3 | VV/IV |
VV/IV = Any Valid Value / Any Invalid Value
The all pairs strategy creates test cases so that for any given pair of inputs, all combinations between them are tested. It is based on the observations that a bug is rarely the result of more than two interacting factors. The resulting number of test cases is lower than the all combinations strategy, but higher than the at least once approach.
this strategy generates 9 test cases:
Let's first consider inputs p1 and p2:
| Input | Values |
|---|---|
| p1 | a, b, c |
| p2 | 1, 2, 3 |
These values can generate
Next, let's consider p1 and p3.
| Input | Values |
|---|---|
| p1 | a, b, c |
| p3 | T, F |
These values can generate
Similarly, inputs p2 and p3 generates another 6 combinations.
The 9 test cases given below covers all those 9+6+6 combinations.
| Test Case | p1 | p2 | p3 |
|---|---|---|---|
| 1 | a | 1 | T |
| 2 | a | 2 | T |
| 3 | a | 3 | F |
| 4 | b | 1 | F |
| 5 | b | 2 | T |
| 6 | b | 3 | F |
| 7 | c | 1 | T |
| 8 | c | 2 | F |
| 9 | c | 3 | T |
A variation of this strategy is to test all pairs of inputs but only for inputs that could influence each other.
Testing all pairs between p1 and p3 only while ensuring all p3 values are tested at least once
| Test Case | p1 | p2 | p3 |
|---|---|---|---|
| 1 | a | 1 | T |
| 2 | a | 2 | F |
| 3 | b | 3 | T |
| 4 | b | VV/IV | F |
| 5 | c | VV/IV | T |
| 6 | c | VV/IV | F |
The random strategy generates test cases using one of the other strategies and then pick a subset randomly (presumably because the original set of test cases is too big).
There are other strategies that can be used too.
W11.4c Can apply heuristic ‘each valid input at least once in a positive test case’
Quality Assurance → Test Case Design → Combining Test Inputs →
Consider the following scenario.
SUT: printLabel(fruitName String, unitPrice int)
Selected values for fruitName (invalid values are underlined ):
| Values | Explanation |
|---|---|
| Apple | Label format is round |
| Banana | Label format is oval |
| Cherry | Label format is square |
| Dog | Not a valid fruit |
Selected values for unitPrice:
| Values | Explanation |
|---|---|
| 1 | Only one digit |
| 20 | Two digits |
| 0 | Invalid because 0 is not a valid price |
| -1 | Invalid because negative prices are not allowed |
Suppose these are the test cases being considered.
| Case | fruitName | unitPrice | Expected |
|---|---|---|---|
| 1 | Apple | 1 | Print label |
| 2 | Banana | 20 | Print label |
| 3 | Cherry | 0 | Error message “invalid price” |
| 4 | Dog | -1 | Error message “invalid fruit" |
It looks like the test cases were created using the at least once strategy. After running these tests can we confirm that square-format label printing is done correctly?
- Answer: No.
- Reason:
Cherry-- the only input that can produce a square-format label -- is in a negative test case which produces an error message instead of a label. If there is a bug in the code that prints labels in square-format, these tests cases will not trigger that bug.
In this case a useful heuristic to apply is each valid input must appear at least once in a positive test case. Cherry is a valid test input and we must ensure that it appears at least once in a positive test case. Here are the updated test cases after applying that heuristic.
| Case | fruitName | unitPrice | Expected |
|---|---|---|---|
| 1 | Apple | 1 | Print round label |
| 2 | Banana | 20 | Print oval label |
| 2.1 | Cherry | VV | Print square label |
| 3 | VV | 0 | Error message “invalid price” |
| 4 | Dog | -1 | Error message “invalid fruit" |
VV/IV = Any Invalid or Valid Value VV=Any Valid Value
W11.4d Can apply heuristic ‘no more than one invalid input in a test case’
Quality Assurance → Test Case Design → Combining Test Inputs →
Consider the
| Case | fruitName | unitPrice | Expected |
|---|---|---|---|
| 1 | Apple | 1 | Print round label |
| 2 | Banana | 20 | Print oval label |
| 2.1 | Cherry | VV | Print square label |
| 3 | VV | 0 | Error message “invalid price” |
| 4 | Dog | -1 | Error message “invalid fruit" |
VV/IV = Any Invalid or Valid Value VV=Any Valid Value
After running these test cases can you be sure that the error message “invalid price” is shown for negative prices?
- Answer: No.
- Reason:
-1-- the only input that is a negative price -– is in a test case that produces the error message “invalid fruit”.
In this case a useful heuristic to apply is no more than one invalid input in a test case. After applying that, we get the following test cases.
| Case | fruitName | unitPrice | Expected |
|---|---|---|---|
| 1 | Apple | 1 | Print round label |
| 2 | Banana | 20 | Print oval label |
| 2.1 | Cherry | VV | Print square label |
| 3 | VV | 0 | Error message “invalid price” |
| 4 | VV | -1 | Error message “invalid price" |
| 4.1 | Dog | VV | Error message “invalid fruit" |
VV/IV = Any Invalid or Valid Value VV=Any Valid Value
Applying the heuristics covered so far, we can determine the precise number of test cases required to test any given SUT effectively.
False
Explanation: These heuristics are, well, heuristics only. They will help you to make better decisions about test case design. However, they are speculative in nature (especially, when testing in black-box fashion) and cannot give you precise number of test cases.
W11.4e Can apply multiple test input combination techniques together
Quality Assurance → Test Case Design → Combining Test Inputs →
Consider the calculateGrade scenario given below:
- SUT :
calculateGrade(participation, projectGrade, isAbsent, examScore) - Values to test: invalid values are underlined
- participation: 0, 1, 19, 20, 21, 22
- projectGrade: A, B, C, D, F
- isAbsent: true, false
- examScore: 0, 1, 69, 70, 71, 72
To get the first cut of test cases, let’s apply the at least once strategy.
Test cases for calculateGrade V1
| Case No. | participation | projectGrade | isAbsent | examScore | Expected |
|---|---|---|---|---|---|
| 1 | 0 | A | true | 0 | ... |
| 2 | 1 | B | false | 1 | ... |
| 3 | 19 | C | VV/IV | 69 | ... |
| 4 | 20 | D | VV/IV | 70 | ... |
| 5 | 21 | F | VV/IV | 71 | Err Msg |
| 6 | 22 | VV/IV | VV/IV | 72 | Err Msg |
VV/IV = Any Valid or Invalid Value, Err Msg = Error Message
Next, let’s apply the each valid input at least once in a positive test case heuristic. Test case 5 has a valid value for projectGrade=F that doesn't appear in any other positive test case. Let's replace test case 5 with 5.1 and 5.2 to rectify that.
Test cases for calculateGrade V2
| Case No. | participation | projectGrade | isAbsent | examScore | Expected |
|---|---|---|---|---|---|
| 1 | 0 | A | true | 0 | ... |
| 2 | 1 | B | false | 1 | ... |
| 3 | 19 | C | VV | 69 | ... |
| 4 | 20 | D | VV | 70 | ... |
| 5.1 | VV | F | VV | VV | ... |
| 5.2 | 21 | VV/IV | VV/IV | 71 | Err Msg |
| 6 | 22 | VV/IV | VV/IV | 72 | Err Msg |
VV = Any Valid Value VV/IV = Any Valid or Invalid Value
Next, we apply the no more than one invalid input in a test case heuristic. Test cases 5.2 and 6 don't follow that heuristic. Let's rectify the situation as follows:
Test cases for calculateGrade V3
| Case No. | participation | projectGrade | isAbsent | examScore | Expected |
|---|---|---|---|---|---|
| 1 | 0 | A | true | 0 | ... |
| 2 | 1 | B | false | 1 | ... |
| 3 | 19 | C | VV | 69 | ... |
| 4 | 20 | D | VV | 70 | ... |
| 5.1 | VV | F | VV | VV | ... |
| 5.2 | 21 | VV | VV | VV | Err Msg |
| 5.3 | 22 | VV | VV | VV | Err Msg |
| 6.1 | VV | VV | VV | 71 | Err Msg |
| 6.2 | VV | VV | VV | 72 | Err Msg |
Next, let us assume that there is a dependency between the inputs examScore and isAbsent such that an absent student can only have examScore=0. To cater for the hidden invalid case arising from this, we can add a new test case where isAbsent=true and examScore!=0. In addition, test cases 3-6.2 should have isAbsent=false so that the input remains valid.
Test cases for calculateGrade V4
| Case No. | participation | projectGrade | isAbsent | examScore | Expected |
|---|---|---|---|---|---|
| 1 | 0 | A | true | 0 | ... |
| 2 | 1 | B | false | 1 | ... |
| 3 | 19 | C | false | 69 | ... |
| 4 | 20 | D | false | 70 | ... |
| 5.1 | VV | F | false | VV | ... |
| 5.2 | 21 | VV | false | VV | Err Msg |
| 5.3 | 22 | VV | false | VV | Err Msg |
| 6.1 | VV | VV | false | 71 | Err Msg |
| 6.2 | VV | VV | false | 72 | Err Msg |
| 7 | VV | VV | true | !=0 | Err Msg |
Which of these contradict the heuristics recommended when creating test cases with multiple inputs?
(a) inputs.
Explanation: If you test all invalid test inputs together, you will not know if each one of the invalid inputs are handled correctly by the SUT. This is because most SUTs return an error message upon encountering the first invalid input.
Apply heuristics for combining multiple test inputs to improve the E&E of the following test cases, assuming all 6 values in the table need to be tested. underlines indicate invalid values. Point out where the heuristics are contradicted and how to improve the test cases.
SUT: consume(food, drink)
| Test case | food | drink |
|---|---|---|
| TC1 | bread | water |
| TC2 | rice | lava |
| TC3 | rock | acid |
Evidence:
Apply the heuristics to design test cases for a simple method that takes two parameters.
Project Management
W11.5 Can explain types of SDLC process models
W11.5a Can explain SDLC process models
Project Management → SDLC Process Models → Introduction →
Software development goes through different stages such as requirements, analysis, design, implementation and testing. These stages are collectively known as the software development life cycle (SDLC). There are several approaches, known as software development life cycle models (also called software process models) that describe different ways to go through the SDLC. Each process model prescribes a "roadmap" for the software developers to manage the development effort. The roadmap describes the aims of the development stage(s), the artifacts or outcome of each stage as well as the workflow i.e. the relationship between stages.
W11.5b Can explain sequential process models
Project Management → SDLC Process Models → Introduction →
The sequential model, also called the waterfall model, models software development as a linear process, in which the project is seen as progressing steadily in one direction through the development stages. The name waterfall stems from how the model is drawn to look like a waterfall (see below).
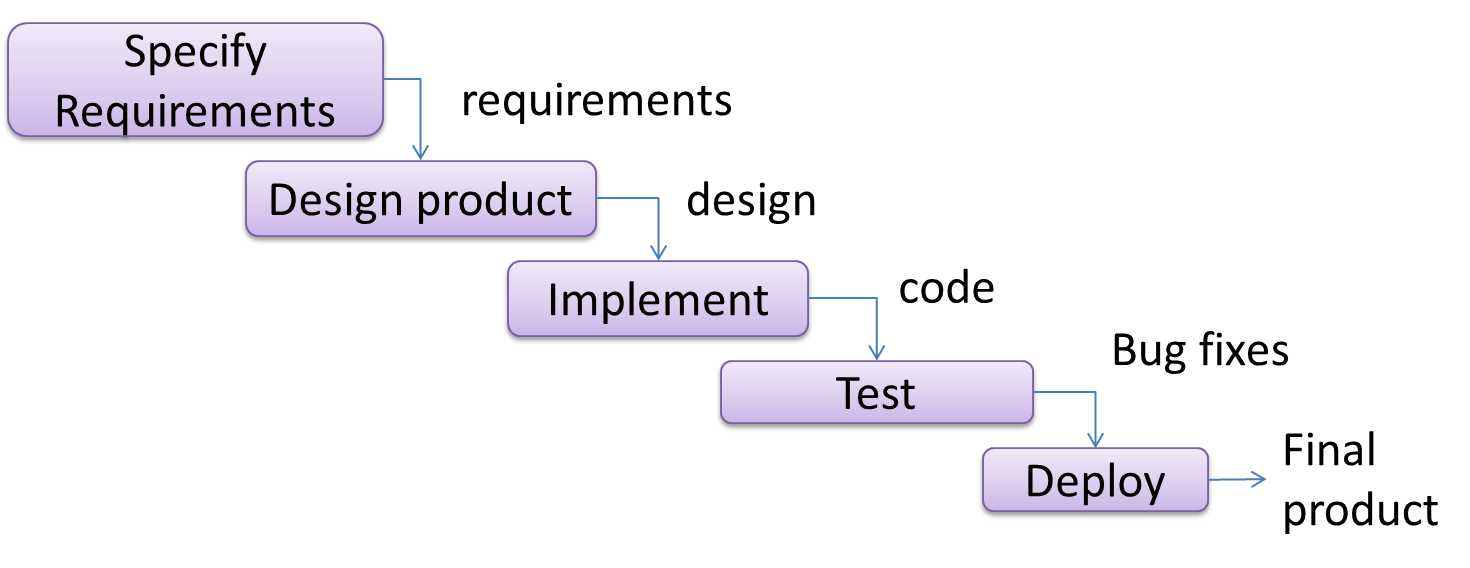
When one stage of the process is completed, it should produce some artifacts to be used in the next stage. For example, upon completion of the requirement stage a comprehensive list of requirements is produced that will see no further modifications. A strict application of the sequential model would require each stage to be completed before starting the next.
This could be a useful model when the problem statement that is well-understood and stable. In such cases, using the sequential model should result in a timely and systematic development effort, provided that all goes well. As each stage has a well-defined outcome, the progress of the project can be tracked with a relative ease.
The major problem with this model is that requirements of a real-world project are rarely well-understood at the beginning and keep changing over time. One reason for this is that users are generally not aware of how a software application can be used without prior experience in using a similar application.
Evidence:
Relate this concept to how you are doing the project.
W11.5c Can explain iterative process models
Project Management → SDLC Process Models → Introduction →
The iterative model (sometimes called iterative and incremental) advocates having several iterations of SDLC. Each of the iterations could potentially go through all the development stages, from requirement gathering to testing & deployment. Roughly, it appears to be similar to several cycles of the sequential model.
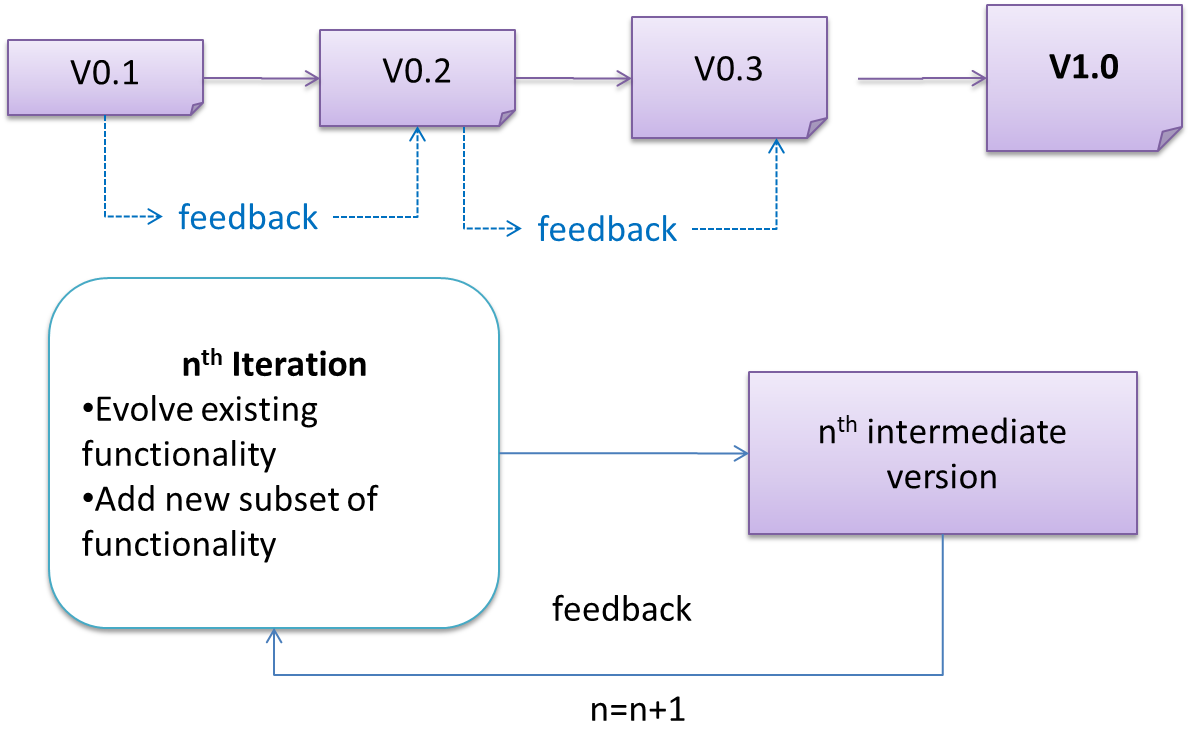
In this model, each of the iterations produces a new version of the product. Feedback on the version can then be fed to the next iteration. Taking the Minesweeper game as an example, the iterative model will deliver a fully playable version from the early iterations. However, the first iteration will have primitive functionality, for example, a clumsy text based UI, fixed board size, limited randomization etc. These functionalities will then be improved in later releases.
The iterative model can take a breadth-first or a depth-first approach to iteration planning.
- breadth-first: an iteration evolves all major components in parallel.
- depth-first: an iteration focuses on fleshing out only some components.
Most project use a mixture of breadth-first and depth-first iterations. Hence, the common phrase ‘an iterative and incremental process’.
Evidence:
Relate this concept to how you are doing the project.
W11.5d Can explain agile process models
Project Management → SDLC Process Models → Introduction →
In 2001, a group of prominent software engineering practitioners met and brainstormed for an alternative to documentation-driven, heavyweight software development processes that were used in most large projects at the time. This resulted in something called the agile manifesto (a vision statement of what they were looking to do).
We are uncovering better ways of developing software by doing it and helping others do it.
Through this work we have come to value:
- Individuals and interactions over processes and tools
- Working software over comprehensive documentation
- Customer collaboration over contract negotiation
- Responding to change over following a plan
That is, while there is value in the items on the right, we value the items on the left more.
Extract from the Agile Manifesto
Subsequently, some of the signatories of the manifesto went on to create process models that try to follow it. These processes are collectively called agile processes. Some of the key features of agile approaches are:
- Requirements are prioritized based on the needs of the user, are clarified regularly (at times almost on a daily basis) with the entire project team, and are factored into the development schedule as appropriate.
- Instead of doing a very elaborate and detailed design and a project plan for the whole project, the team works based on a rough project plan and a high level design that evolves as the project goes on.
- Strong emphasis on complete transparency and responsibility sharing among the team members. The team is responsible together for the delivery of the product. Team members are accountable, and regularly and openly share progress with each other and with the user.
There are a number of agile processes in the development world today. eXtreme Programming (XP) and Scrum are two of the well-known ones.
Choose the correct statements about agile processes.
- a. They value working software over comprehensive documentation.
- b. They value responding to change over following a plan.
- c. They may not be suitable for some type of projects.
- d. XP and Scrum are agile processes.
(a)(b)(c)(d)
Evidence:
Relate this concept to how you are doing the project.
W11.6 Can explain some popular SDLC process models
W11.6a Can explain scrum
Project Management → SDLC Process Models →
This description of Scrum was adapted from Wikipedia [retrieved on 18/10/2011], emphasis added:
Scrum is a process skeleton that contains sets of practices and predefined roles. The main roles in Scrum are:
- The Scrum Master, who maintains the processes (typically in lieu of a project manager)
- The Product Owner, who represents the stakeholders and the business
- The Team, a cross-functional group who do the actual analysis, design, implementation, testing, etc.
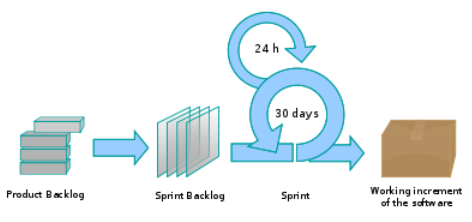
A Scrum project is divided into iterations called Sprints. A sprint is the basic unit of development in Scrum. Sprints tend to last between one week and one month, and are a timeboxed (i.e. restricted to a specific duration) effort of a constant length.
Each sprint is preceded by a planning meeting, where the tasks for the sprint are identified and an estimated commitment for the sprint goal is made, and followed by a review or retrospective meeting, where the progress is reviewed and lessons for the next sprint are identified.
During each sprint, the team creates a potentially deliverable product increment (for example, working and tested software). The set of features that go into a sprint come from the product backlog, which is a prioritized set of high level requirements of work to be done. Which backlog items go into the sprint is determined during the sprint planning meeting. During this meeting, the Product Owner informs the team of the items in the product backlog that he or she wants completed. The team then determines how much of this they can commit to complete during the next sprint, and records this in the sprint backlog. During a sprint, no one is allowed to change the sprint backlog, which means that the requirements are frozen for that sprint. Development is timeboxed such that the sprint must end on time; if requirements are not completed for any reason they are left out and returned to the product backlog. After a sprint is completed, the team demonstrates the use of the software.
Scrum enables the creation of self-organizing teams by encouraging co-location of all team members, and verbal communication between all team members and disciplines in the project.
A key principle of Scrum is its recognition that during a project the customers can change their minds about what they want and need (often called requirements churn), and that unpredicted challenges cannot be easily addressed in a traditional predictive or planned manner. As such, Scrum adopts an empirical approach—accepting that the problem cannot be fully understood or defined, focusing instead on maximizing the team’s ability to deliver quickly and respond to emerging requirements.
Daily Scrum is another key scrum practice. The description below was adapted from https://www.mountaingoatsoftware.com (emphasis added):
In Scrum, on each day of a sprint, the team holds a daily scrum meeting called the "daily scrum.” Meetings are typically held in the same location and at the same time each day. Ideally, a daily scrum meeting is held in the morning, as it helps set the context for the coming day's work. These scrum meetings are strictly time-boxed to 15 minutes. This keeps the discussion brisk but relevant.
...
During the daily scrum, each team member answers the following three questions:
- What did you do yesterday?
- What will you do today?
- Are there any impediments in your way?
...
The daily scrum meeting is not used as a problem-solving or issue resolution meeting. Issues that are raised are taken offline and usually dealt with by the relevant subgroup immediately after the meeting.
(This is not an endorsement of the product mentioned in the video)
Evidence:
Relate this model and some of its practices to the project. e.g. Are you doing something similar? Will it help if you adopt those practices? If they are not applicable, why?
W11.6b Can explain XP
Project Management → SDLC Process Models →
The following description was adapted from the XP home page, emphasis added:
Extreme Programming (XP) stresses customer satisfaction. Instead of delivering everything you could possibly want on some date far in the future, this process delivers the software you need as you need it.
XP aims to empower developers to confidently respond to changing customer requirements, even late in the life cycle.
XP emphasizes teamwork. Managers, customers, and developers are all equal partners in a collaborative team. XP implements a simple, yet effective environment enabling teams to become highly productive. The team self-organizes around the problem to solve it as efficiently as possible.
XP aims to improve a software project in five essential ways: communication, simplicity, feedback, respect, and courage. Extreme Programmers constantly communicate with their customers and fellow programmers. They keep their design simple and clean. They get feedback by testing their software starting on day one. Every small success deepens their respect for the unique contributions of each and every team member. With this foundation, Extreme Programmers are able to courageously respond to changing requirements and technology.
XP has a set of simple rules. XP is a lot like a jig saw puzzle with many small pieces. Individually the pieces make no sense, but when combined together a complete picture can be seen. This flow chart shows how Extreme Programming's rules work together.
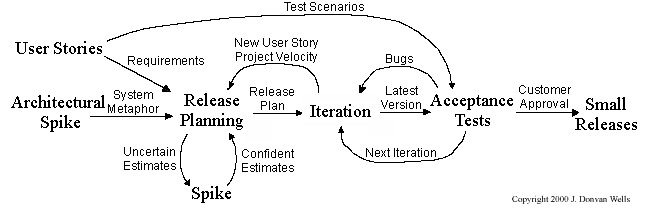
Pair programming, CRC cards, project velocity, and standup meetings are some interesting topics related to XP. Refer to extremeprogramming.org to find out more about XP.
Evidence:
Relate this model and some of its practices to the project. e.g. Are you doing something similar? Will it help if you adopt those practices? If they are not applicable, why?
W11.6c Can explain the Unified Process
Project Management → SDLC Process Models →
The unified process is developed by the Three Amigos - Ivar Jacobson, Grady Booch and James Rumbaugh (the creators of UML).
The unified process consists of four phases: inception, elaboration, construction and transition. The main purpose of each phase can be summarized as follows:
| Phase | Activities | Typical Artifacts |
|---|---|---|
| Inception |
|
|
| Elaboration |
|
|
| Construction |
|
|
| Transition |
|
|
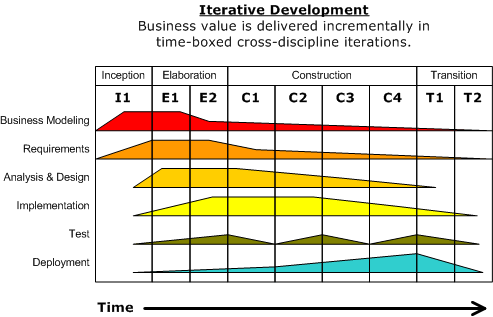
Given above is a visualization of a project done using the Unified process (source: Wikipedia). As the diagram shows, a phase can consist of several iterations. Each vertical column (labeled “I1” “E1”, “E2”, “C1”, etc.) represents a single iteration. Each of the iterations consists of a set of ‘workflows’ such as ‘Business modeling’, ‘Requirements’, ‘Analysis & Design’ etc. The shaded region indicates the amount of resource and effort spent on a particular workflow in a particular iteration.
Unified process is a flexible and customizable process model framework rather than a single fixed process. For example, the number of iterations in each phase, definition of workflows, and the intensity of a given workflow in a given iteration can be adjusted according to the nature of the project. Take the Construction Phase, to develop a simple system, one or two iterations would be sufficient. For a more complicated system, multiple iterations will be more helpful. Therefore, the diagram above simply records a particular application of the UP rather than prescribe how the UP is to be applied. However, this record can be refined and reused for similar future projects.
Choose the correct statements about the unified process.
- a. It was conceived by the three amigos who also created UML.
- b. The Unified process requires the use of UML.
- c. The Unified process is actually a process framework rather than a fixed process.
- d. The Unified process can be iterative and incremental
(a)(b)(c)(d)
Explanation: Although UP was created by the same three amigos who created UML, the UP does not require UML.
Evidence:
Relate this model and some of its practices to the project. e.g. Are you doing something similar? Will it help if you adopt those practices? If they are not applicable, why?
W11.6d Can explain CMMI
Project Management → SDLC Process Models →
CMMI (Capability Maturity Model Integration) is a process improvement approach defined by Software Engineering Institute at Carnegie Melon University. CMMI provides organizations with the essential elements of effective processes, which will improve their performance. -- adapted from http://www.sei.cmu.edu/cmmi/
CMMI defines five maturity levels for a process and provides criteria to determine if the process of an organization is at a certain maturity level. The diagram below [taken from Wikipedia] gives an overview of the five levels.
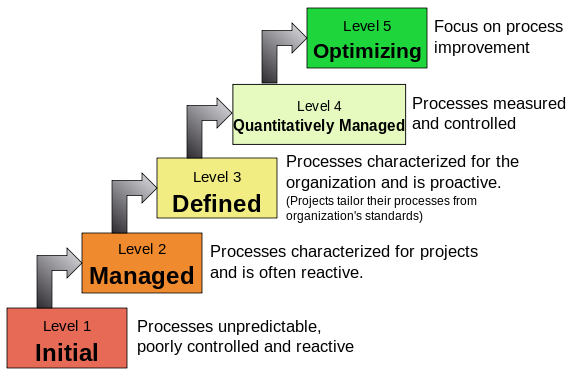
W11.6e Can explain process models at a higher level
Project Management → SDLC Process Models →
This section has some exercise that cover multiple topics related to SDLC process models.
Discuss how sequential approach and the iterative approach can affect the following aspects of a project.
a) Quality of the final product.
b) Risk of overshooting the deadline.
c) Total project cost.
d) Customer satisfaction.
e) Monitoring the project progress.
f) Suitability for a school project
a) Quality of the final product:
- Iterative: Frequent reworking can deteriorate the design. Frequent refactoring should be used to prevent this. Frequent customer feedback can help to improve the quality (i.e. quality as seen by the customer).
- Sequential: Final quality depends on the quality of each phase. Any quality problem in any phase could result in a low quality product.
b) Risk of overshooting the deadline.
- Iterative: Less risk. If the last iteration got delayed, we can always deliver the previous version. However, this does not guarantee that all features promised at the beginning will be delivered on the deadline.
- Sequential: High risk. Any delay in any phase can result in overshooting the deadline with nothing to deliver.
c) Total project cost.
- Iterative: We can always stop before the project budget is exceeded. However, this does not guarantee that all features promised at the beginning will be delivered under the estimated cost. (The sequential model requires us to carry on even if the budget is exceeded because there is no intermediate version to fall back on).
Iterative reworking of existing artifacts could add to the cost. However, this is “cheaper” than finding at the end that we built the wrong product.
d) Customer satisfaction
- Iterative: Customer gets many opportunities to guide the product in the direction he wants. Customer gets to change requirements even in the middle of the product. Both these can increase the probability of customer satisfaction.
- Sequential: Customer satisfaction is guaranteed only if the product was delivered as promised and if the initial requirements proved to be accurate. However, the customer is not required to do the extra work of giving frequent feedback during the project.
e) Monitoring project progress
- Iterative: Hard to measure progress against a plan, as the plan itself keeps changing.
- Sequential: Easier to measure progress against the plan, although this does not ensure eventual success.
f) Suitability for a school project:
Reasons to use iterative:
- Requirements are not fixed.
- Overshooting the deadline is not an option.
- Gives a chance to learn lessons from one iteration and apply them in the next.
Sequential:
- Can save time because we minimize rework.
Find out more about the following three topics and give at least three arguments for and three arguments against each.
(a) Agile processes
(b) Pair programming
(c) Test-driven development
(a) Arguments in favor of agile processes:
- More focus on customer satisfaction.
- Less chance of building the wrong product (because of frequent customer feedback).
- Less resource wasted on bureaucracy, over-documenting, contract negotiations.
Arguments against agile processes (not necessarily true):
- It is ‘just hacking’. Not very systematic. No discipline.
- It is hard to know in advance the exact final product.
- It does not give enough attention to documentation.
- Lack of management control (gives too much freedom to developers)
(b) Arguments in favor of pair programming:
- It could produce better quality code.
- It is good to have more than one person know about any piece of code.
- It is a way to learn from each other.
- It can be used to train new programmers.
- Better discipline and better time management (e.g. less likely to play Farmville while working).
- Better morale due to more interactions with co-workers.
Arguments against pair programming:
- Increase in total man hours required
- Personality clashes between pair-members
- Workspaces need to be adapted to suit two developers working at one computer.
- If pairs are rotated, one needs to know more parts of the system than in solo programming
(c) Arguments in favor of TDD:
- Testing will not be neglected due to time pressure (because it is done first).
- Forces the developer to think about what the component should be before jumping into implementing it.
- Optimizes programmer effort (i.e. if all tests pass, there is no need to add any more functionality).
- Forces us to automate all tests.
Arguments against TDD (not necessarily true):
- Since tests can be seen as ‘executable specifications’, programmers tend to neglect others forms of documentation.
- Promotes ‘trial-and-error’ coding instead of making programmers think through their algorithms (i.e. ‘just keep hacking until all tests pass’).
- Gives a false sense of security. (what if you forgot to test certain scenarios?)
Not intuitive. Some programmer might resist adopting TDD.
The sequential model and the waterfall model are the two most basic process models.
False
Explanation: The sequential model and the waterfall model are the same thing. The second basic model is the iterative model.
Choose the correct statements about the sequential and iterative process models.
- a. The sequential model organizes the project based on activities.
- b. The iterative and incremental model organizes the project based on functionality.
- c. The iterative model can be breadth-first or depth-first.
- d. The iterative model is always better than the sequential model.
- e. Compared to the sequential model, the iterative model is better at adapting to changing requirements.
(a)(b)(c)(d)(e)
Explanation: Both models have pros and cons. There is no definitive ‘better’ choice between the two. However, the iterative model works better in typical software projects than a purely sequential approach.
In general, which has a higher risk of overshooting a deadline?
(b)
Explanation: An iterative process can meet a deadline better than a sequential process. If the last iteration got delayed, we can always deliver the previous version. However, this does not guarantee that all features promised at the beginning will be delivered on the deadline.
🅿️ Project
W11.7 Can release a product incrementally
Covered by:
Tutorial 11
A. One member do a quick demo of your v1.3 using the jar file (preferably a different member from previous weeks):
B. Whole team: do this question together, using the whiteboard
Apply heuristics for combining multiple test inputs to improve the E&E of the following test cases, assuming all 6 values in the table need to be tested. underlines indicate invalid values. Point out where the heuristics are contradicted and how to improve the test cases.
SUT: consume(food, drink)
| Test case | food | drink |
|---|---|---|
| TC1 | bread | water |
| TC2 | rice | lava |
| TC3 | rock | acid |
C. Divide these questions among team members and get ready to answer them.
- Distinguish between sequential and iterative processes. Which one are we using in the project?
- Distinguish between breadth-first and depth-first iterative processes using your project as an example.
- Describe how agile process models differ from traditional process models.
- When do you use MVC pattern? Do we have MVC in AB4?
- When do you use the Observer pattern? Do we have the Observer pattern in AB4?
D. Divide XP and Scrum between the two teams for the following activity, if there is enough time left.
-
Each team use the Web to find about 5 distinguishing features of the process model.
- Some interesting SCRUM concepts: Product backlog, scrum board, story points, burndown charts, scrum master, product owner
- XP rules are described at http://www.extremeprogramming.org/rules.html
-
Relate those features to your project. i.e. are they applicable? are you doing something similar?
W11.1a Can explain the Model View Controller (MVC) design pattern
Design → Design Patterns → MVC Pattern →
Context
Most applications support storage/retrieval of information, displaying of information to the user (often via multiple UIs having different formats), and changing stored information based on external inputs.
Problem
The high coupling that can result from the interlinked nature of the features described above.
Solution
Decouple data, presentation, and control logic of an application by separating them into three different components: Model, View and Controller.
- View: Displays data, interacts with the user, and pulls data from the model if necessary.
- Controller: Detects UI events such as mouse clicks, button pushes and takes follow up action. Updates/changes the model/view when necessary.
- Model: Stores and maintains data. Updates views if necessary.
The relationship between the components can be observed in the diagram below. Typically, the UI is the combination of view and controller.
Given below is a concrete example of MVC applied to a student management system. In this scenario, the user is retrieving data of one student.
In the diagram above, when the user clicks on a button using the UI, the ‘click’ event is caught and handled by the UiController. The ref frame indicates that the interactions within that frame have been extracted out to another separate sequence diagram.
Note that in a simple UI where there’s only one view, Controller and View can be combined as one class.
There are many variations of the MVC model used in different domains. For example, the one used in a desktop GUI could be different from the one used in a Web application.
Evidence:
Explain relevance of the pattern to the project.
W11.1b Can explain the Observer design pattern
Design → Design Patterns → Observer Pattern →
Context
An object (possibly, more than one) is interested to get notified when a change happens to another object. That is, some objects want to ‘observe’ another object.
Consider this scenario from the a student management system where the user is adding a new student to the system.
Now, assume the system has two additional views used in parallel by different users:
StudentListUi: that accesses a list of students andStudentStatsUi: that generates statistics of current students.
When a student is added to the database using NewStudentUi shown above, both StudentListUi and StudentStatsUi should get updated automatically, as shown below.
However, the StudentList object has no knowledge about StudentListUi and StudentStatsUi (note the direction of the navigability) and has no way to inform those objects. This is an example of the type of problem addressed by the Observer pattern.
Problem
The ‘observed’ object does not want to be coupled to objects that are ‘observing’ it.
Solution
Force the communication through an interface known to both parties.
Here is the Observer pattern applied to the student management system.
During the initialization of the system,
-
First, create the relevant objects.
StudentList studentList = new StudentList(); StudentListUi listUi = new StudentListUi(); StudentStatusUi statusUi = new StudentStatsUi(); -
Next, the two UIs indicate to the
StudentListthat they are interested in being updated wheneverStudentListchanges. This is also known as ‘subscribing for updates’.studentList.addUi(listUi); studentList.addUi(statusUi); -
Within the
addUioperation ofStudentList, all Observer objects subscribers are added to an internal data structure calledobserverList.//StudentList class public void addUi(Observer o) { observerList.add(o); }
Now, whenever the data in StudentList changes (e.g. when a new student is added to the StudentList),
-
All interested observers are updated by calling the
notifyUIsoperation.//StudentList class public void notifyUIs() { //for each observer in the list for(Observer o: observerList){ o.update(); } } -
UIs can then pull data from the
StudentListwhenever theupdateoperation is called.//StudentListUI class public void update() { //refresh UI by pulling data from StudentList }Note that
StudentListis unaware of the exact nature of the two UIs but still manages to communicate with them via an intermediary.
Here is the generic description of the observer pattern:
<<Observer>>is an interface: any class that implements it can observe an<<Observable>>. Any number of<<Observer>>objects can observe (i.e. listen to changes of) the<<Observable>>object.- The
<<Observable>>maintains a list of<<Observer>>objects.addObserver(Observer)operation adds a new<<Observer>>to the list of<<Observer>>s. - Whenever there is a change in the
<<Observable>>, thenotifyObservers()operation is called that will call theupdate()operation of all<<Observer>>sin the list.
In a GUI application, how is the Controller notified when the “save” button is clicked? UI frameworks such as JavaFX has inbuilt support for the Observer pattern.
Explain how polymorphism is used in the Observer pattern.
With respect to the general form of the Observer pattern given above, when the Observable object invokes the notifyObservers() method, it is treating all ConcreteObserver objects as a general type called Observer and calling the update() method of each of them. However, the update() method of each ConcreteObserver could potentially show different behavior based on its actual type. That is, update() method shows polymorphic behavior.
In the example given below, the notifyUIs operation can result in StudentListUi and StudentStatsUi changing their views in two different ways.
The Observer pattern can be used when we want one object to initiate an activity in another object without having a direct dependency from the first object to the second object.
True
Explanation: Yes. For example, when applying the Observer pattern to an MVC structure, Views can get notified and update themselves about a change to the Model without the Model having to depend on the Views.
Evidence:
Explain relevance of the pattern to the project.
W11.1c Can recognize some of the GoF design patterns
Design → Design Patterns →
The most famous source of design patterns is the "Gang of Four" (GoF) book which contains 23 design patterns divided into three categories:
- Creational: About object creation. They separate the operation of an application from how its objects are created.
- Abstract Factory, Builder, Factory Method, Prototype, Singleton
- Structural: About the composition of objects into larger structures while catering for future extension in structure.
- Adapter, Bridge, Composite, Decorator, Façade, Flyweight, Proxy
- Behavioral: Defining how objects interact and how responsibility is distributed among them.
- Chain of Responsibility, Command, Interpreter, Template Method, Iterator, Mediator, Memento, Observer, State, Strategy, Visitor
Evidence:
Name a few GoF patterns not covered in the module.
W11.2a Can combine multiple patterns to fit a context
Design → Design Patterns →
Design patterns are usually embedded in a larger design and sometimes applied in combination with other design patterns.
Let us look at a case study that shows how design patterns are used in the design of a class structure for a Stock Inventory System (SIS) for a shop. The shop sells appliances, and accessories for the appliances. SIS simply stores information about each item in the store.
Use Cases:
- Create a new item
- View information about an item
- Modify information about an item
- View all available accessories for a given appliance
- List all items in the store
SIS can be accessed using multiple terminals. Shop assistants use their own terminals to access SIS, while the shop manager’s terminal continuously displays a list of all items in store. In the future, it is expected that suppliers of items use their own applications to connect to SIS to get real-time information about current stock status. User authentication is not required for the current version, but may be required in the future.
A step by step explanation of the design is given below. Note that this is one out of many possible designs. Design patterns are also applied where appropriate.
A StockItem can be an Appliance or an Accessory.
To track that each Accessory is associated with the correct Appliance, consider the following alternative class structures.
The third one seems more appropriate (the second one is suitable if accessories can have accessories). Next, consider between keeping a list of Appliances, and a list of StockItems. Which is more appropriate?
The latter seems more suitable because it can handle both appliances and accessories the same way. Next, an abstraction occurrence pattern is applied to keep track of StockItems.
Note the inclusion of navigabilities. Here’s a sample object diagram based on the class model created thus far.
Next, apply the façade pattern to shield the SIS internals from the UI.
As UI consists of multiple views, the MVC pattern is applied here.
Some views need to be updated when the data change; apply the Observer pattern here.
In addition, the Singleton pattern can be applied to the façade class.
Evidence:
Give an example of combining patterns.
W11.2b Can explain pros and cons of design patterns
Design → Design Patterns →
Design pattern provides a high-level vocabulary to talk about design.
Someone can say 'apply Observer pattern here' instead of having to describe the mechanics of the solution in detail.
Knowing more patterns is a way to become more ‘experienced’. Aim to learn at least the context and the problem of patterns so that when you encounter those problems you know where to look for a solution.
Some patterns are domain-specific e.g. patterns for distributed applications, some are created in-house e.g. patterns in the company/project and some can be self-created e.g. from past experience.
Be careful not to overuse patterns. Do not throw patterns at a problem at every opportunity. Patterns come with overhead such as adding more classes or increasing the levels of abstraction. Use them only when they are needed. Before applying a pattern, make sure that:
- there is substantial improvement in the design, not just superficial.
- the associated tradeoffs are carefully considered. There are times when a design pattern is not appropriate (or an overkill).
Evidence:
Take an example patterns in the project and explain its benefits and costs.
W11.2d Can explain how patterns exist beyond software design domain
Design → Design Patterns →
The notion of capturing design ideas as "patterns" is usually attributed to Christopher Alexander. He is a building architect noted for his theories about design. His book Timeless way of building talks about "design patterns" for constructing buildings.
Here is a sample pattern from that book:
When a room has a window with a view, the window becomes a focal point: people are attracted to the window and want to look through it. The furniture in the room creates a second focal point: everyone is attracted toward whatever point the furniture aims them at (usually the center of the room or a TV). This makes people feel uncomfortable. They want to look out the window, and toward the other focus at the same time. If you rearrange the furniture, so that its focal point becomes the window, then everyone will suddenly notice that the room is much more “comfortable”
Apparently, patterns and anti-patterns are found in the field of building architecture. This is because they are general concepts applicable to any domain, not just software design. In software engineering, there are many general types of patterns: Analysis patterns, Design patterns, Testing patterns, Architectural patterns, Project management patterns, and so on.
In fact, the abstraction occurrence pattern is more of an analysis pattern than a design pattern, while MVC is more of an architectural pattern.
New patterns can be created too. If a common problem needs to be solved frequently that leads to a non-obvious and better solution, it can be formulated as a pattern so that it can be reused by others. However, don’t reinvent the wheel; the pattern might already exist.
Here are some common elements of a design pattern: Name, Context, Problem, Solution, Anti-patterns (optional), Consequences (optional), other useful information (optional).
Using similar elements, describe a pattern that is not a design pattern. It must be a pattern you have noticed, not a pattern already documented by others. You may also give a pattern not related to software.
Some examples:
- A pattern for testing textual UIs.
- A pattern for striking a good bargain at a mall such as Sim-Lim Square.
Evidence:
Give example patterns from other domains.
W11.4e Can apply multiple test input combination techniques together
Quality Assurance → Test Case Design → Combining Test Inputs →
Consider the calculateGrade scenario given below:
- SUT :
calculateGrade(participation, projectGrade, isAbsent, examScore) - Values to test: invalid values are underlined
- participation: 0, 1, 19, 20, 21, 22
- projectGrade: A, B, C, D, F
- isAbsent: true, false
- examScore: 0, 1, 69, 70, 71, 72
To get the first cut of test cases, let’s apply the at least once strategy.
Test cases for calculateGrade V1
| Case No. | participation | projectGrade | isAbsent | examScore | Expected |
|---|---|---|---|---|---|
| 1 | 0 | A | true | 0 | ... |
| 2 | 1 | B | false | 1 | ... |
| 3 | 19 | C | VV/IV | 69 | ... |
| 4 | 20 | D | VV/IV | 70 | ... |
| 5 | 21 | F | VV/IV | 71 | Err Msg |
| 6 | 22 | VV/IV | VV/IV | 72 | Err Msg |
VV/IV = Any Valid or Invalid Value, Err Msg = Error Message
Next, let’s apply the each valid input at least once in a positive test case heuristic. Test case 5 has a valid value for projectGrade=F that doesn't appear in any other positive test case. Let's replace test case 5 with 5.1 and 5.2 to rectify that.
Test cases for calculateGrade V2
| Case No. | participation | projectGrade | isAbsent | examScore | Expected |
|---|---|---|---|---|---|
| 1 | 0 | A | true | 0 | ... |
| 2 | 1 | B | false | 1 | ... |
| 3 | 19 | C | VV | 69 | ... |
| 4 | 20 | D | VV | 70 | ... |
| 5.1 | VV | F | VV | VV | ... |
| 5.2 | 21 | VV/IV | VV/IV | 71 | Err Msg |
| 6 | 22 | VV/IV | VV/IV | 72 | Err Msg |
VV = Any Valid Value VV/IV = Any Valid or Invalid Value
Next, we apply the no more than one invalid input in a test case heuristic. Test cases 5.2 and 6 don't follow that heuristic. Let's rectify the situation as follows:
Test cases for calculateGrade V3
| Case No. | participation | projectGrade | isAbsent | examScore | Expected |
|---|---|---|---|---|---|
| 1 | 0 | A | true | 0 | ... |
| 2 | 1 | B | false | 1 | ... |
| 3 | 19 | C | VV | 69 | ... |
| 4 | 20 | D | VV | 70 | ... |
| 5.1 | VV | F | VV | VV | ... |
| 5.2 | 21 | VV | VV | VV | Err Msg |
| 5.3 | 22 | VV | VV | VV | Err Msg |
| 6.1 | VV | VV | VV | 71 | Err Msg |
| 6.2 | VV | VV | VV | 72 | Err Msg |
Next, let us assume that there is a dependency between the inputs examScore and isAbsent such that an absent student can only have examScore=0. To cater for the hidden invalid case arising from this, we can add a new test case where isAbsent=true and examScore!=0. In addition, test cases 3-6.2 should have isAbsent=false so that the input remains valid.
Test cases for calculateGrade V4
| Case No. | participation | projectGrade | isAbsent | examScore | Expected |
|---|---|---|---|---|---|
| 1 | 0 | A | true | 0 | ... |
| 2 | 1 | B | false | 1 | ... |
| 3 | 19 | C | false | 69 | ... |
| 4 | 20 | D | false | 70 | ... |
| 5.1 | VV | F | false | VV | ... |
| 5.2 | 21 | VV | false | VV | Err Msg |
| 5.3 | 22 | VV | false | VV | Err Msg |
| 6.1 | VV | VV | false | 71 | Err Msg |
| 6.2 | VV | VV | false | 72 | Err Msg |
| 7 | VV | VV | true | !=0 | Err Msg |
Which of these contradict the heuristics recommended when creating test cases with multiple inputs?
(a) inputs.
Explanation: If you test all invalid test inputs together, you will not know if each one of the invalid inputs are handled correctly by the SUT. This is because most SUTs return an error message upon encountering the first invalid input.
Apply heuristics for combining multiple test inputs to improve the E&E of the following test cases, assuming all 6 values in the table need to be tested. underlines indicate invalid values. Point out where the heuristics are contradicted and how to improve the test cases.
SUT: consume(food, drink)
| Test case | food | drink |
|---|---|---|
| TC1 | bread | water |
| TC2 | rice | lava |
| TC3 | rock | acid |
Evidence:
Apply the heuristics to design test cases for a simple method that takes two parameters.
W11.5b Can explain sequential process models
Project Management → SDLC Process Models → Introduction →
The sequential model, also called the waterfall model, models software development as a linear process, in which the project is seen as progressing steadily in one direction through the development stages. The name waterfall stems from how the model is drawn to look like a waterfall (see below).
When one stage of the process is completed, it should produce some artifacts to be used in the next stage. For example, upon completion of the requirement stage a comprehensive list of requirements is produced that will see no further modifications. A strict application of the sequential model would require each stage to be completed before starting the next.
This could be a useful model when the problem statement that is well-understood and stable. In such cases, using the sequential model should result in a timely and systematic development effort, provided that all goes well. As each stage has a well-defined outcome, the progress of the project can be tracked with a relative ease.
The major problem with this model is that requirements of a real-world project are rarely well-understood at the beginning and keep changing over time. One reason for this is that users are generally not aware of how a software application can be used without prior experience in using a similar application.
Evidence:
Relate this concept to how you are doing the project.
W11.5c Can explain iterative process models
Project Management → SDLC Process Models → Introduction →
The iterative model (sometimes called iterative and incremental) advocates having several iterations of SDLC. Each of the iterations could potentially go through all the development stages, from requirement gathering to testing & deployment. Roughly, it appears to be similar to several cycles of the sequential model.
In this model, each of the iterations produces a new version of the product. Feedback on the version can then be fed to the next iteration. Taking the Minesweeper game as an example, the iterative model will deliver a fully playable version from the early iterations. However, the first iteration will have primitive functionality, for example, a clumsy text based UI, fixed board size, limited randomization etc. These functionalities will then be improved in later releases.
The iterative model can take a breadth-first or a depth-first approach to iteration planning.
- breadth-first: an iteration evolves all major components in parallel.
- depth-first: an iteration focuses on fleshing out only some components.
Most project use a mixture of breadth-first and depth-first iterations. Hence, the common phrase ‘an iterative and incremental process’.
Evidence:
Relate this concept to how you are doing the project.
W11.5d Can explain agile process models
Project Management → SDLC Process Models → Introduction →
In 2001, a group of prominent software engineering practitioners met and brainstormed for an alternative to documentation-driven, heavyweight software development processes that were used in most large projects at the time. This resulted in something called the agile manifesto (a vision statement of what they were looking to do).
We are uncovering better ways of developing software by doing it and helping others do it.
Through this work we have come to value:
- Individuals and interactions over processes and tools
- Working software over comprehensive documentation
- Customer collaboration over contract negotiation
- Responding to change over following a plan
That is, while there is value in the items on the right, we value the items on the left more.
Extract from the Agile Manifesto
Subsequently, some of the signatories of the manifesto went on to create process models that try to follow it. These processes are collectively called agile processes. Some of the key features of agile approaches are:
- Requirements are prioritized based on the needs of the user, are clarified regularly (at times almost on a daily basis) with the entire project team, and are factored into the development schedule as appropriate.
- Instead of doing a very elaborate and detailed design and a project plan for the whole project, the team works based on a rough project plan and a high level design that evolves as the project goes on.
- Strong emphasis on complete transparency and responsibility sharing among the team members. The team is responsible together for the delivery of the product. Team members are accountable, and regularly and openly share progress with each other and with the user.
There are a number of agile processes in the development world today. eXtreme Programming (XP) and Scrum are two of the well-known ones.
Choose the correct statements about agile processes.
- a. They value working software over comprehensive documentation.
- b. They value responding to change over following a plan.
- c. They may not be suitable for some type of projects.
- d. XP and Scrum are agile processes.
(a)(b)(c)(d)
Evidence:
Relate this concept to how you are doing the project.
W11.6a Can explain scrum
Project Management → SDLC Process Models →
This description of Scrum was adapted from Wikipedia [retrieved on 18/10/2011], emphasis added:
Scrum is a process skeleton that contains sets of practices and predefined roles. The main roles in Scrum are:
- The Scrum Master, who maintains the processes (typically in lieu of a project manager)
- The Product Owner, who represents the stakeholders and the business
- The Team, a cross-functional group who do the actual analysis, design, implementation, testing, etc.
A Scrum project is divided into iterations called Sprints. A sprint is the basic unit of development in Scrum. Sprints tend to last between one week and one month, and are a timeboxed (i.e. restricted to a specific duration) effort of a constant length.
Each sprint is preceded by a planning meeting, where the tasks for the sprint are identified and an estimated commitment for the sprint goal is made, and followed by a review or retrospective meeting, where the progress is reviewed and lessons for the next sprint are identified.
During each sprint, the team creates a potentially deliverable product increment (for example, working and tested software). The set of features that go into a sprint come from the product backlog, which is a prioritized set of high level requirements of work to be done. Which backlog items go into the sprint is determined during the sprint planning meeting. During this meeting, the Product Owner informs the team of the items in the product backlog that he or she wants completed. The team then determines how much of this they can commit to complete during the next sprint, and records this in the sprint backlog. During a sprint, no one is allowed to change the sprint backlog, which means that the requirements are frozen for that sprint. Development is timeboxed such that the sprint must end on time; if requirements are not completed for any reason they are left out and returned to the product backlog. After a sprint is completed, the team demonstrates the use of the software.
Scrum enables the creation of self-organizing teams by encouraging co-location of all team members, and verbal communication between all team members and disciplines in the project.
A key principle of Scrum is its recognition that during a project the customers can change their minds about what they want and need (often called requirements churn), and that unpredicted challenges cannot be easily addressed in a traditional predictive or planned manner. As such, Scrum adopts an empirical approach—accepting that the problem cannot be fully understood or defined, focusing instead on maximizing the team’s ability to deliver quickly and respond to emerging requirements.
Daily Scrum is another key scrum practice. The description below was adapted from https://www.mountaingoatsoftware.com (emphasis added):
In Scrum, on each day of a sprint, the team holds a daily scrum meeting called the "daily scrum.” Meetings are typically held in the same location and at the same time each day. Ideally, a daily scrum meeting is held in the morning, as it helps set the context for the coming day's work. These scrum meetings are strictly time-boxed to 15 minutes. This keeps the discussion brisk but relevant.
...
During the daily scrum, each team member answers the following three questions:
- What did you do yesterday?
- What will you do today?
- Are there any impediments in your way?
...
The daily scrum meeting is not used as a problem-solving or issue resolution meeting. Issues that are raised are taken offline and usually dealt with by the relevant subgroup immediately after the meeting.
(This is not an endorsement of the product mentioned in the video)
Evidence:
Relate this model and some of its practices to the project. e.g. Are you doing something similar? Will it help if you adopt those practices? If they are not applicable, why?
W11.6b Can explain XP
Project Management → SDLC Process Models →
The following description was adapted from the XP home page, emphasis added:
Extreme Programming (XP) stresses customer satisfaction. Instead of delivering everything you could possibly want on some date far in the future, this process delivers the software you need as you need it.
XP aims to empower developers to confidently respond to changing customer requirements, even late in the life cycle.
XP emphasizes teamwork. Managers, customers, and developers are all equal partners in a collaborative team. XP implements a simple, yet effective environment enabling teams to become highly productive. The team self-organizes around the problem to solve it as efficiently as possible.
XP aims to improve a software project in five essential ways: communication, simplicity, feedback, respect, and courage. Extreme Programmers constantly communicate with their customers and fellow programmers. They keep their design simple and clean. They get feedback by testing their software starting on day one. Every small success deepens their respect for the unique contributions of each and every team member. With this foundation, Extreme Programmers are able to courageously respond to changing requirements and technology.
XP has a set of simple rules. XP is a lot like a jig saw puzzle with many small pieces. Individually the pieces make no sense, but when combined together a complete picture can be seen. This flow chart shows how Extreme Programming's rules work together.
Pair programming, CRC cards, project velocity, and standup meetings are some interesting topics related to XP. Refer to extremeprogramming.org to find out more about XP.
Evidence:
Relate this model and some of its practices to the project. e.g. Are you doing something similar? Will it help if you adopt those practices? If they are not applicable, why?
W11.6c Can explain the Unified Process
Project Management → SDLC Process Models →
The unified process is developed by the Three Amigos - Ivar Jacobson, Grady Booch and James Rumbaugh (the creators of UML).
The unified process consists of four phases: inception, elaboration, construction and transition. The main purpose of each phase can be summarized as follows:
| Phase | Activities | Typical Artifacts |
|---|---|---|
| Inception |
|
|
| Elaboration |
|
|
| Construction |
|
|
| Transition |
|
|
Given above is a visualization of a project done using the Unified process (source: Wikipedia). As the diagram shows, a phase can consist of several iterations. Each vertical column (labeled “I1” “E1”, “E2”, “C1”, etc.) represents a single iteration. Each of the iterations consists of a set of ‘workflows’ such as ‘Business modeling’, ‘Requirements’, ‘Analysis & Design’ etc. The shaded region indicates the amount of resource and effort spent on a particular workflow in a particular iteration.
Unified process is a flexible and customizable process model framework rather than a single fixed process. For example, the number of iterations in each phase, definition of workflows, and the intensity of a given workflow in a given iteration can be adjusted according to the nature of the project. Take the Construction Phase, to develop a simple system, one or two iterations would be sufficient. For a more complicated system, multiple iterations will be more helpful. Therefore, the diagram above simply records a particular application of the UP rather than prescribe how the UP is to be applied. However, this record can be refined and reused for similar future projects.
Choose the correct statements about the unified process.
- a. It was conceived by the three amigos who also created UML.
- b. The Unified process requires the use of UML.
- c. The Unified process is actually a process framework rather than a fixed process.
- d. The Unified process can be iterative and incremental
(a)(b)(c)(d)
Explanation: Although UP was created by the same three amigos who created UML, the UP does not require UML.
Evidence:
Relate this model and some of its practices to the project. e.g. Are you doing something similar? Will it help if you adopt those practices? If they are not applicable, why?
W11.7 Can release a product incrementally
Covered by: