Week 3 [Aug 27]
Todo
Admin info to read:
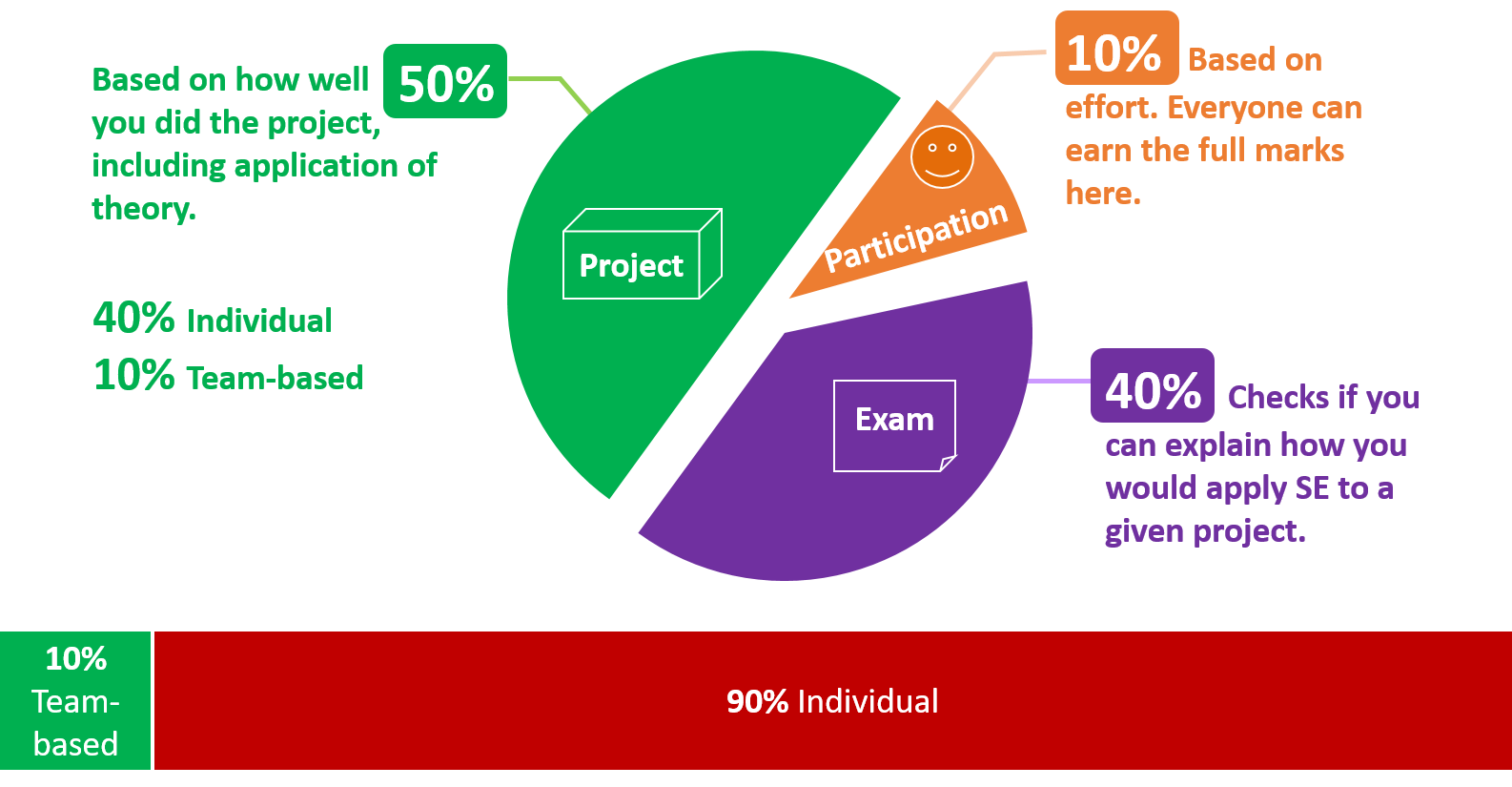
Note that project grading is not competitive (not bell curved). CS2103T projects will be assessed separately from CS2103 projects. This is to account for the perceived difference in workload. Given below is the marking scheme.
Total: 50 marks ( 40 individual marks + 10 team marks)
Evaluates: How well do your features fit together to form a cohesive product (not how many features or how big the features are)?
Based on: user guide and the product demo. The quality of the demo will be factored in as well.
💡 Feature that fit well with the other features will earn more marks.
Evaluates:
A. Code quality/quantity:
How good your implementation is, in terms of the quality and the quantity of the code you have written yourself.
Based on: an inspection of the parts of the code you claim as written by you.
-
Ensure your code has at least some evidence of these (see here for more info)
- logging
- exceptions
- assertions
- defensive coding
-
Ensure there are no coding standard violations e.g. all boolean variables/methods sounds like booleans. Checkstyle can prevent only some coding standard violations; others need to be checked manually.
-
Ensure SLAP is applied at a reasonable level. Long methods or deeply-nested code are symptoms of low-SLAP may be counted against your code quality.
-
Reduce code duplications i.e. if there multiple blocks of code that vary only in minor ways, try to extract out similarities into one place, especially in test code.
-
In addition, try to apply as many of the
code quality guidelines covered in the module as much as you can.
Can explain the importance of code quality
Always code as if the person who ends up maintaining your code will be a violent psychopath who knows where you live. -- Martin Golding
Can explain the importance of readability
Programs should be written and polished until they acquire publication quality. --Niklaus Wirth
Among various dimensions of code quality, such as run-time efficiency, security, and robustness, one of the most important is understandability. This is because in any non-trivial software project, code needs to be read, understood, and modified by other developers later on. Even if we do not intend to pass the code to someone else, code quality is still important because we all become 'strangers' to our own code someday.
The two code samples given below achieve the same functionality, but one is easier to read.
|
Bad |
|
Good |
|
Bad |
|
Good |
Can improve code quality using technique: avoid long methods
Be wary when a method is longer than the computer screen, and take corrective action when it goes beyond 30 LOC (lines of code). The bigger the haystack, the harder it is to find a needle.
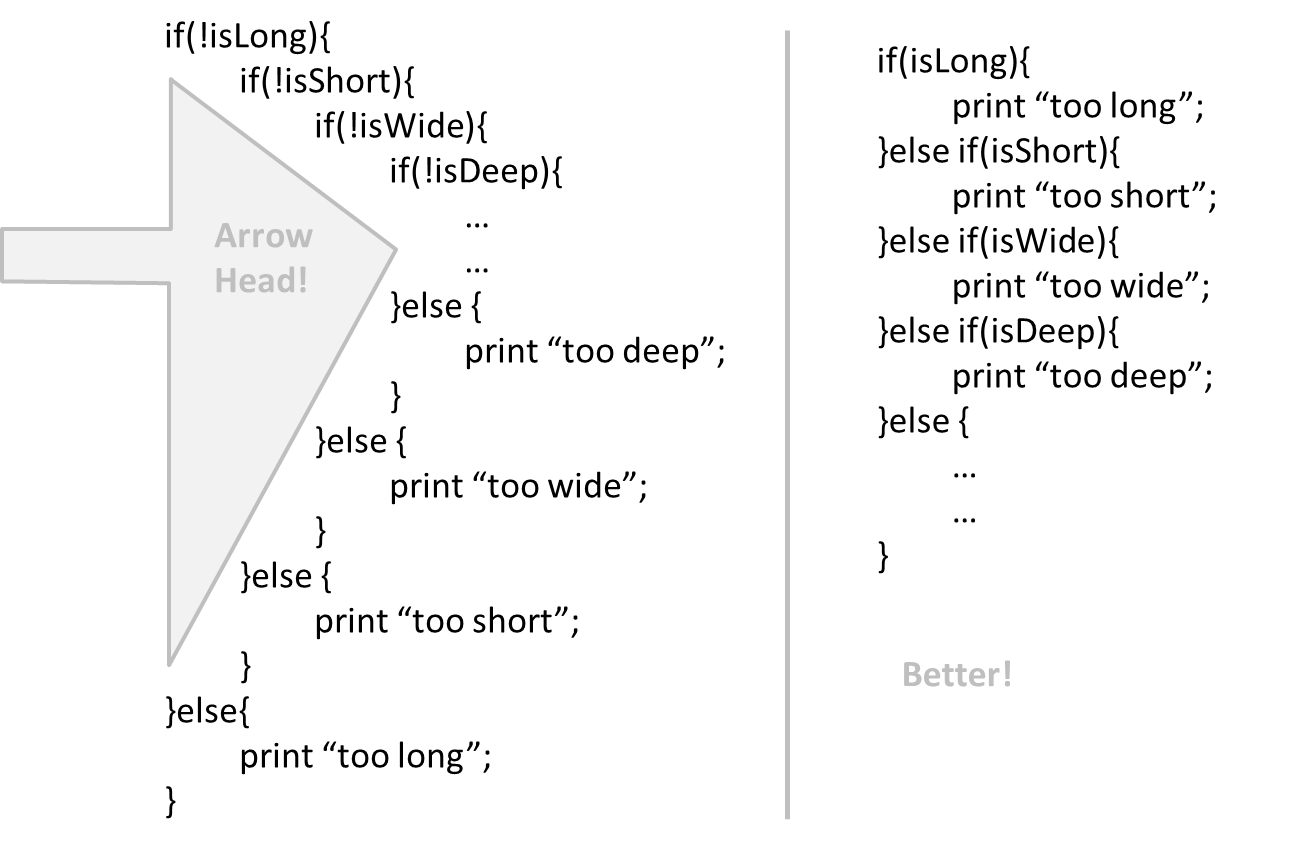
Can improve code quality using technique: avoid deep nesting
If you need more than 3 levels of indentation, you're screwed anyway, and should fix your program. --Linux 1.3.53 CodingStyle
In particular, avoid arrowhead style code.
Example:
Can improve code quality using technique: avoid complicated expressions
Avoid complicated expressions, especially those having many negations and nested parentheses. If you must evaluate complicated expressions, have it done in steps (i.e. calculate some intermediate values first and use them to calculate the final value).
Example:
Bad
return ((length < MAX_LENGTH) || (previousSize != length)) && (typeCode == URGENT);
Good
boolean isWithinSizeLimit = length < MAX_LENGTH;
boolean isSameSize = previousSize != length;
boolean isValidCode = isWithinSizeLimit || isSameSize;
boolean isUrgent = typeCode == URGENT;
return isValidCode && isUrgent;
Example:
Bad
return ((length < MAX_LENGTH) or (previous_size != length)) and (type_code == URGENT)
Good
is_within_size_limit = length < MAX_LENGTH
is_same_size = previous_size != length
is_valid_code = is_within_size_limit or is_same_size
is_urgent = type_code == URGENT
return is_valid_code and is_urgent
The competent programmer is fully aware of the strictly limited size of his own skull; therefore he approaches the programming task in full humility, and among other things he avoids clever tricks like the plague. -- Edsger Dijkstra
Can improve code quality using technique: avoid magic numbers
When the code has a number that does not explain the meaning of the number, we call that a magic number (as in “the number appears as if by magic”). Using a
Example:
|
Bad |
|
Good |
Note: Python does not have a way to make a variable a constant. However, you can use a normal variable with an ALL_CAPS name to simulate a constant.
|
Bad |
|
Good |
Similarly, we can have ‘magic’ values of other data types.
Bad
"Error 1432" // A magic string!
Can improve code quality using technique: make the code obvious
Make the code as explicit as possible, even if the language syntax allows them to be implicit. Here are some examples:
- [
Java] Use explicit type conversion instead of implicit type conversion. - [
Java,Python] Use parentheses/braces to show grouping even when they can be skipped. - [
Java,Python] Useenumerations when a certain variable can take only a small number of finite values. For example, instead of declaring the variable 'state' as an integer and using values 0,1,2 to denote the states 'starting', 'enabled', and 'disabled' respectively, declare 'state' as typeSystemStateand define an enumerationSystemStatethat has values'STARTING','ENABLED', and'DISABLED'.
Can improve code quality using technique: structure code logically
Lay out the code so that it adheres to the logical structure. The code should read like a story. Just like we use section breaks, chapters and paragraphs to organize a story, use classes, methods, indentation and line spacing in your code to group related segments of the code. For example, you can use blank lines to group related statements together. Sometimes, the correctness of your code does not depend on the order in which you perform certain intermediary steps. Nevertheless, this order may affect the clarity of the story you are trying to tell. Choose the order that makes the story most readable.
Can improve code quality using technique: do not 'trip up' reader
Avoid things that would make the reader go ‘huh?’, such as,
- unused parameters in the method signature
- similar things look different
- different things that look similar
- multiple statements in the same line
- data flow anomalies such as, pre-assigning values to variables and modifying it without any use of the pre-assigned value
Can improve code quality using technique: practice kissing
As the old adage goes, "keep it simple, stupid” (KISS). Do not try to write ‘clever’ code. For example, do not dismiss the brute-force yet simple solution in favor of a complicated one because of some ‘supposed benefits’ such as 'better reusability' unless you have a strong justification.
Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it. --Brian W. Kernighan
Programs must be written for people to read, and only incidentally for machines to execute. --Abelson and Sussman
Can improve code quality using technique: avoid premature optimizations
Optimizing code prematurely has several drawbacks:
- We may not know which parts are the real performance bottlenecks. This is especially the case when the code undergoes transformations (e.g. compiling, minifying, transpiling, etc.) before it becomes an executable. Ideally, you should use a profiler tool to identify the actual bottlenecks of the code first, and optimize only those parts.
- Optimizing can complicate the code, affecting correctness and understandability
- Hand-optimized code can be harder for the compiler to optimize (the simpler the code, the easier for the compiler to optimize it). In many cases a compiler can do a better job of optimizing the runtime code if you don't get in the way by trying to hand-optimize the source code.
A popular saying in the industry is make it work, make it right, make it fast which means in most cases getting the code to perform correctly should take priority over optimizing it. If the code doesn't work correctly, it has no value on matter how fast/efficient it it.
Premature optimization is the root of all evil in programming. --Donald Knuth
Note that there are cases where optimizing takes priority over other things e.g. when writing code for resource-constrained environments. This guideline simply a caution that you should optimize only when it is really needed.
Can improve code quality using technique: SLAP hard
Avoid varying the level of
Example:
Bad
readData();
salary = basic*rise+1000;
tax = (taxable?salary*0.07:0);
displayResult();
Good
readData();
processData();
displayResult();
Design → Design Fundamentals → Abstraction →
Abstraction is a technique for dealing with complexity. It works by establishing a level of complexity we are interested in, and suppressing the more complex details below that level.
The guiding principle of abstraction is that only details that are relevant to the current perspective or the task at hand needs to be considered. As most programs are written to solve complex problems involving large amounts of intricate details, it is impossible to deal with all these details at the same time. That is where abstraction can help.
Ignoring lower level data items and thinking in terms of bigger entities is called data abstraction.
Within a certain software component, we might deal with a user data type, while ignoring the details contained in the user data item such as name, and date of birth. These details have been ‘abstracted away’ as they do not affect the task of that software component.
Control abstraction abstracts away details of the actual control flow to focus on tasks at a simplified level.
print(“Hello”) is an abstraction of the actual output mechanism within the computer.
Abstraction can be applied repeatedly to obtain progressively higher levels of abstractions.
An example of different levels of data abstraction: a File is a data item that is at a higher level than an array and an array is at a higher level than a bit.
An example of different levels of control abstraction: execute(Game) is at a higher level than print(Char) which is at a higher than an Assembly language instruction MOV.
Abstraction is a general concept that is not limited to just data or control abstractions.
Some more general examples of abstraction:
- An OOP class is an abstraction over related data and behaviors.
- An architecture is a higher-level abstraction of the design of a software.
- Models (e.g., UML models) are abstractions of some aspect of reality.
Can improve code quality using technique: make the happy path prominent
The happy path (i.e. the execution path taken when everything goes well) should be clear and prominent in your code. Restructure the code to make the happy path unindented as much as possible. It is the ‘unusual’ cases that should be indented. Someone reading the code should not get distracted by alternative paths taken when error conditions happen. One technique that could help in this regard is the use of guard clauses.
Example:
Bad
if (!isUnusualCase) { //detecting an unusual condition
if (!isErrorCase) {
start(); //main path
process();
cleanup();
exit();
} else {
handleError();
}
} else {
handleUnusualCase(); //handling that unusual condition
}
In the code above,
- Unusual condition detection is separated from their handling.
- Main path is nested deeply.
Good
if (isUnusualCase) { //Guard Clause
handleUnusualCase();
return;
}
if (isErrorCase) { //Guard Clause
handleError();
return;
}
start();
process();
cleanup();
exit();
In contrast, the above code
- deals with unusual conditions as soon as they are detected so that the reader doesn't have to remember them for long.
- keeps the main path un-indented.
Can explain the need for following a standard
One essential way to improve code quality is to follow a consistent style. That is why software engineers follow a strict coding standard (aka style guide).
The aim of a coding standard is to make the entire code base look like it was written by one person. A coding standard is usually specific to a programming language and specifies guidelines such as the location of opening and closing braces, indentation styles and naming styles (e.g. whether to use Hungarian style, Pascal casing, Camel casing, etc.). It is important that the whole team/company use the same coding standard and that standard is not generally inconsistent with typical industry practices. If a company's coding standards is very different from what is used typically in the industry, new recruits will take longer to get used to the company's coding style.
💡 IDEs can help to enforce some parts of a coding standard e.g. indentation rules.
What is the recommended approach regarding coding standards?
c
What is the aim of using a coding standard? How does it help?
Can follow simple mechanical style rules
Learn basic guidelines of the Java coding standard (by OSS-Generic)
Sample coding standard: PEP 8 Python Style Guide -- by Python.org
Consider the code given below:
import java.util.*;
public class Task {
public static final String descriptionPrefix = "description: ";
private String description;
private boolean important;
List<String> pastDescription = new ArrayList<>(); // a list of past descriptions
public Task(String d) {
this.description = d;
if (!d.isEmpty())
this.important = true;
}
public String getAsXML() { return "<task>"+description+"</task>"; }
/**
* Print the description as a string.
*/
public void printingDescription(){ System.out.println(this); }
@Override
public String toString() { return descriptionPrefix + description; }
}
In what ways the code violate the basic guidelines (i.e., those marked with one ⭐️) of the OSS-Generic Java Coding Standard given here?
Here are three:
descriptionPrefixis a constant and should be namedDESCRIPTION_PREFIX- method name
printingDescription()should be named asprintDescription() - boolean variable
importantshould be named to sound boolean e.g.,isImportant
There are many more.
Can follow intermediate style rules
Go through the provided Java coding standard and learn the intermediate style rules.
According to the given Java coding standard, which one of these is not a good name?
b
Explanation: checkWeight is an action. Naming variables as actions makes the code harder to follow. isWeightValid may be a better name.
Repeat the exercise in the panel below but also find violations of intermediate level guidelines.
Consider the code given below:
import java.util.*;
public class Task {
public static final String descriptionPrefix = "description: ";
private String description;
private boolean important;
List<String> pastDescription = new ArrayList<>(); // a list of past descriptions
public Task(String d) {
this.description = d;
if (!d.isEmpty())
this.important = true;
}
public String getAsXML() { return "<task>"+description+"</task>"; }
/**
* Print the description as a string.
*/
public void printingDescription(){ System.out.println(this); }
@Override
public String toString() { return descriptionPrefix + description; }
}
In what ways the code violate the basic guidelines (i.e., those marked with one ⭐️) of the OSS-Generic Java Coding Standard given here?
Here are three:
descriptionPrefixis a constant and should be namedDESCRIPTION_PREFIX- method name
printingDescription()should be named asprintDescription() - boolean variable
importantshould be named to sound boolean e.g.,isImportant
There are many more.
Here's one you are more likely to miss:
* Print the description as a string.→* Prints the description as a string.
There are more.
Can explain the need for good names in code
Proper naming improves the readability. It also reduces bugs caused by ambiguities regarding the intent of a variable or a method.
There are only two hard things in Computer Science: cache invalidation and naming things. -- Phil Karlton
Can improve code quality using technique: use nouns for things and verbs for actions
Every system is built from a domain-specific language designed by the programmers to describe that system. Functions are the verbs of that language, and classes are the nouns. ― Robert C. Martin, Clean Code: A Handbook of Agile Software Craftsmanship
Use nouns for classes/variables and verbs for methods/functions.
Examples:
| Name for a | Bad | Good |
|---|---|---|
| Class | CheckLimit |
LimitChecker |
| method | result() |
calculate() |
Distinguish clearly between single-valued and multivalued variables.
Examples:
Good
Person student;
ArrayList<Person> students;
Good
student = Person('Jim')
students = [Person('Jim'), Person('Alice')]
Can improve code quality using technique: use standard words
Use correct spelling in names. Avoid 'texting-style' spelling. Avoid foreign language words, slang, and names that are only meaningful within specific contexts/times e.g. terms from private jokes, a TV show currently popular in your country
Can improve code quality using technique: use name to explain
A name is not just for differentiation; it should explain the named entity to the reader accurately and at a sufficient level of detail.
Examples:
| Bad | Good |
|---|---|
processInput() (what 'process'?) |
removeWhiteSpaceFromInput() |
flag |
isValidInput |
temp |
If the name has multiple words, they should be in a sensible order.
Examples:
| Bad | Good |
|---|---|
bySizeOrder() |
orderBySize() |
Imagine going to the doctor's and saying "My eye1 is swollen"! Don’t use numbers or case to distinguish names.
Examples:
| Bad | Bad | Good |
|---|---|---|
value1, value2 |
value, Value |
originalValue, finalValue |
Can improve code quality using technique: not too long, not too short
While it is preferable not to have lengthy names, names that are 'too short' are even worse. If you must abbreviate or use acronyms, do it consistently. Explain their full meaning at an obvious location.
Can improve code quality using technique: avoid misleading names
Related things should be named similarly, while unrelated things should NOT.
Example: Consider these variables
colorBlack: hex value for color blackcolorWhite: hex value for color whitecolorBlue: number of times blue is usedhexForRed: : hex value for color red
This is misleading because colorBlue is named similar to colorWhite and colorBlack but has a different purpose while hexForRed is named differently but has very similar purpose to the first two variables. The following is better:
hexForBlackhexForWhitehexForRedblueColorCount
Avoid misleading or ambiguous names (e.g. those with multiple meanings), similar sounding names, hard-to-pronounce ones (e.g. avoid ambiguities like "is that a lowercase L, capital I or number 1?", or "is that number 0 or letter O?"), almost similar names.
Examples:
| Bad | Good | Reason |
|---|---|---|
phase0 |
phaseZero |
Is that zero or letter O? |
rwrLgtDirn |
rowerLegitDirection |
Hard to pronounce |
right left wrong |
rightDirection leftDirection wrongResponse |
right is for 'correct' or 'opposite of 'left'? |
redBooks readBooks |
redColorBooks booksRead |
red and read (past tense) sounds the same |
FiletMignon |
egg |
If the requirement is just a name of a food, egg is a much easier to type/say choice than FiletMignon |
Can explain the need for avoiding error-prone shortcuts
It is safer to use language constructs in the way they are meant to be used, even if the language allows shortcuts. Some such coding practices are common sources of bugs. Know them and avoid them.
Can improve code quality using technique: use the default branch
Always include a default branch in case statements.
Furthermore, use it for the intended default action and not just to execute the last option. If there is no default action, you can use the 'default' branch to detect errors (i.e. if execution reached the default branch, throw an exception). This also applies to the final else of an if-else construct. That is, the final else should mean 'everything else', and not the final option. Do not use else when an if condition can be explicitly specified, unless there is absolutely no other possibility.
Bad
if (red) print "red";
else print "blue";
Good
if (red) print "red";
else if (blue) print "blue";
else error("incorrect input");
Can improve code quality using technique: don't recycle variables or parameters
- Use one variable for one purpose. Do not reuse a variable for a different purpose other than its intended one, just because the data type is the same.
- Do not reuse formal parameters as local variables inside the method.
Bad
double computeRectangleArea(double length, double width) {
length = length * width;
return length;
}
Good
double computeRectangleArea(double length, double width) {
double area;
area = length * width;
return area;
}
Can improve code quality using technique: avoid empty catch blocks
Never write an empty catch statement. At least give a comment to explain why the catch block is left empty.
Can improve code quality using technique: delete dead code
We all feel reluctant to delete code we have painstakingly written, even if we have no use for that code any more ("I spent a lot of time writing that code; what if we need it again?"). Consider all code as baggage you have to carry; get rid of unused code the moment it becomes redundant. If you need that code again, simply recover it from the revision control tool you are using. Deleting code you wrote previously is a sign that you are improving.
Can improve code quality using technique: minimise scope of variables
Minimize global variables. Global variables may be the most convenient way to pass information around, but they do create implicit links between code segments that use the global variable. Avoid them as much as possible.
Define variables in the least possible scope. For example, if the variable is used only within the if block of the conditional statement, it should be declared inside that if block.
The most powerful technique for minimizing the scope of a local variable is to declare it where it is first used. -- Effective Java, by Joshua Bloch
Resources:
Can improve code quality using technique: minimise code duplication
Code duplication, especially when you copy-paste-modify code, often indicates a poor quality implementation. While it may not be possible to have zero duplication, always think twice before duplicating code; most often there is a better alternative.
This guideline is closely related to the
Supplmentary → Principles →
DRY (Don't Repeat Yourself) Principle: Every piece of knowledge must have a single, unambiguous, authoritative representation within a system The Pragmatic Programmer, by Andy Hunt and Dave Thomas
This principle guards against duplication of information.
The functionality implemented twice is a violation of the DRY principle even if the two implementations are different.
The value a system-wide timeout being defined in multiple places is a violation of DRY.
Can explain the need for commenting minimally but sufficiently
Good code is its own best documentation. As you’re about to add a comment, ask yourself, ‘How can I improve the code so that this comment isn’t needed?’ Improve the code and then document it to make it even clearer. --Steve McConnell, Author of Clean Code
Some think commenting heavily increases the 'code quality'. This is not so. Avoid writing comments to explain bad code. Improve the code to make it self-explanatory.
Can improve code quality using technique: do not repeat the obvious
If the code is self-explanatory, refrain from repeating the description in a comment just for the sake of 'good documentation'.
Bad
// increment x
x++;
//trim the input
trimInput();
Can improve code quality using technique: write to the reader
Do not write comments as if they are private notes to self. Instead, write them well enough to be understood by another programmer. One type of comments that is almost always useful is the header comment that you write for a class or an operation to explain its purpose.
Examples:
Bad Reason: this comment will only make sense to the person who wrote it
// a quick trim function used to fix bug I detected overnight
void trimInput(){
....
}
Good
/** Trims the input of leading and trailing spaces */
void trimInput(){
....
}
Bad Reason: this comment will only make sense to the person who wrote it
# a quick trim function used to fix bug I detected overnight
def trim_input():
...
Good
def trim_input():
"""Trim the input of leading and trailing spaces"""
...
Can improve code quality using technique: explain what and why, not how
Comments should explain what and why aspect of the code, rather than the how aspect.
What : The specification of what the code supposed to do. The reader can compare such comments to the implementation to verify if the implementation is correct
Example: This method is possibly buggy because the implementation does not seem to match the comment. In this case the comment could help the reader to detect the bug.
/** Removes all spaces from the {@code input} */
void compact(String input){
input.trim();
}
Why : The rationale for the current implementation.
Example: Without this comment, the reader will not know the reason for calling this method.
// Remove spaces to comply with IE23.5 formatting rules
compact(input);
How : The explanation for how the code works. This should already be apparent from the code, if the code is self-explanatory. Adding comments to explain the same thing is redundant.
Example:
Bad Reason: Comment explains how the code works.
// return true if both left end and right end are correct or the size has not incremented
return (left && right) || (input.size() == size);
Good Reason: Code refactored to be self-explanatory. Comment no longer needed.
boolean isSameSize = (input.size() == size) ;
return (isLeftEndCorrect && isRightEndCorrect) || isSameSize;
null
B. Depth and completeness of your feature
Evaluates: How good is your Quality Assurance?
Based on: 1. your test code 2. our own manual testing 3. your performance in the v1.4 Practical Exam, 4. bugs found during PE.
Relevant: [
Objectives:
- Evaluate your manual testing skills, product evaluation skills, effort estimation skills
- Peer-evaluate your product design , implementation effort , documentation quality
When, where: Week 13 lecture
Grading:
- Your performance in the practical exam will be considered for your final grade (under the QA category and under Implementation category, about 10 marks in total).
- You will be graded based on your effectiveness as a tester (e.g., the percentage of the bugs you found, the nature of the bugs you found) and how far off your evaluation/estimates are from the evaluator consensus. Explanation: we understand that you have limited expertise in this area; hence, we penalize only if your inputs don't seem to be based on a sincere effort to test/evaluate.
- The bugs found in your product by others will affect your v1.4 marks. You will be given a chance to reject false-positive bug reports.
Preparation:
-
Ensure that you can access the relevant issue tracker given below:
-- for PE Dry Run (at v1.3): nus-cs2103-AY1819S1/pe-dry-run
-- for PE (at v1.4): nus-cs2103-AY1819S1/pe (will open only near the actual PE)- These are private repos!. If you cannot access the relevant repo, you may not have accepted the invitation to join the GitHub org used by the module. Go to https://github.com/orgs/nus-cs2103-AY1819S1/invitation to accept the invitation.
- If you cannot find the invitation, post in our forum.
-
Ensure you have access to a computer that is able to run module projects e.g. has the right Java version.
-
Have a good screen grab tool with annotation features so that you can quickly take a screenshot of a bug, annotate it, and post in the issue tracker.
- 💡 You can use Ctrl+V to paste a picture from the clipboard into a text box in GitHub issue tracker.
-
Charge your computer before coming to the PE session. The testing venue may not have enough charging points.
During:
- Take note of your team to test. It will be given to you by the teaching team (distributed via IVLE gradebook).
- Download from IVLE all files submitted by the team (i.e. jar file, User Guide, Developer Guide, and Project Portfolio Pages) into an empty folder.
- [~40 minutes] Test the product and report bugs as described below:
Testing instructions for PE and PE Dry Run
-
What to test:
- PE Dry Run (at v1.3):
- Test the product based on the User Guide (the UG is most likely accessible using the
helpcommand). - Do system testing first i.e., does the product work as specified by the documentation?. If there is time left, you can do acceptance testing as well i.e., does the product solve the problem it claims to solve?.
- Test the product based on the User Guide (the UG is most likely accessible using the
- PE (at v1.4):
- Test based on the Developer Guide (Appendix named Instructions for Manual Testing) and the User Guide. The testing instructions in the Developer Guide can provide you some guidance but if you follow those instructions strictly, you are unlikely to find many bugs. You can deviate from the instructions to probe areas that are more likely to have bugs.
- Do system testing only i.e., verify actual behavior against documented behavior. Do not do acceptance testing.
- PE Dry Run (at v1.3):
-
What not to test:
- Omit features that are driven by GUI inputs (e.g. buttons, menus, etc.) Reason: Only CLI-driven features can earn credit, as per given project constraints. Some features might have both a GUI-driven and CLI-driven ways to invoke them, in which case test only the CLI-driven way of invoking it.
- Omit feature that existed in AB-4.
-
These are considered bugs:
- Behavior differs from the User Guide
- A legitimate user behavior is not handled e.g. incorrect commands, extra parameters
- Behavior is not specified and differs from normal expectations e.g. error message does not match the error
- Problems in the User Guide e.g., missing/incorrect info
-
Where to report bugs: Post bug in the following issue trackers (not in the team's repo):
- PE Dry Run (at v1.3): nus-cs2103-AY1819S1/pe-dry-run.
- PE (at v1.4): nus-cs2103-AY1819S1/pe.
-
Bug report format:
- Post bugs as you find them (i.e., do not wait to post all bugs at the end) because the issue tracker will close exactly at the end of the allocated time.
- Do not use team ID in bug reports. Reason: to prevent others copying your bug reports
- Each bug should be a separate issue.
- Write good quality bug reports; poor quality or incorrect bug reports will not earn credit.
- Use a descriptive title.
- Give a good description of the bug with steps to reproduce and screenshots.
- Assign a severity to the bug report. Bug report without a priority label are considered
severity.Low(lower severity bugs earn lower credit):
Bug Severity labels:
severity.Low: A flaw that is unlikely to affect normal operations of the product. Appears only in very rare situations and causes a minor inconvenience only.severity.Medium: A flaw that causes occasional inconvenience to some users but they can continue to use the product.severity.High: A flaw that affects most users and causes major problems for users. i.e., makes the product almost unusable for most users.
-
About posting suggestions:
- PE Dry Run (at v1.3): You can also post suggestions on how to improve the product. 💡 Be diplomatic when reporting bugs or suggesting improvements. For example, instead of criticising the current behavior, simply suggest alternatives to consider.
- PE (at v1.4): Do not post suggestions.
-
If the product doesn't work at all: If the product fails catastrophically e.g., cannot even launch, you can test the fallback team allocated to you. But in this case you must inform us immediately after the session so that we can send your bug reports to the correct team.
-
[~50 minutes] Evaluate the following aspects. Note down your evaluation in a hard copy (as a backup). Submit via TEAMMATES.
-
A. Cohesiveness of product features []: Do the features fit together and match the stated target user and the value proposition?
unable to judge: You are unable to judge this aspect for some reason.low: One of these- target user is too general i.e. wider than AB4
- target user and/or value proposition not clear from the user guide
- features don't seem to fit together for the most part
medium: Some features fit together but some don't.high: All features fit together but the features are not very high value to the target user.excellent: The target user is clearly defined (not too general) and almost all new features are of high-value to the target user. i.e. the product is very attractive to the target user.
-
B. Quality of user docs []: Evaluate based on the parts of the user guide written by the person, as reproduced in the project portfolio. Evaluate from an end-user perspective.
unable to judge: Less than 1 page worth of UG content written by the student.low: Hard to understand, often inaccurate or missing important information.medium: Needs some effort to understand; some information is missing.high: Mostly easy to follow. Only a few areas need improvements.excellent: Easy to follow and accurate. Just enough information, visuals, examples etc. (not too much either). Understandable to the target end user.
-
C. Quality of developer docs []: Evaluate based on the developer docs cited/reproduced in the respective project portfolio page. Evaluate from the perspective of a new developer trying to understand how the features are implemented.
unable to judge: One of these- less than 0.5 pages worth of content.
- other problems in the document e.g. looks like included wrong content.
low: One of these- Very small amount of content (i.e., 0.5 - 1 page).
- Hardly any use to the reader (i.e., content doesn't make much sense or redundant).
- Uses ad-hoc diagrams where UML diagrams could have been used instead.
- Multiple notation errors in UML diagrams.
medium: Some diagrams, some descriptions, but does not help the reader that much e.g. overly complicated diagrams.high: Enough diagrams (at lest two kinds of UML diagrams used) and enough descriptions (about 2 pages worth) but explanations are not always easy to follow.excellent: Easy to follow. Just enough information (not too much). Minimum repetition of content/diagrams. Good use of diagrams to complement text descriptions. Easy to understand diagrams with just enough details rather than very complicated diagrams that are hard to understand.
-
D. Depth of feature []: Evaluate the feature done by the student for difficulty, depth, and completeness. Note: examples given below assume that AB4 did not have the commands
edit,undo, andredo.unable to judge: You are unable to judge this aspect for some reason.low: An easy feature e.g. make the existing find command case insensitive.medium: Moderately difficult feature, barely acceptable implementation e.g. an edit command that requires the user to type all fields, even the ones that are not being edited.high: One of the below- A moderately difficult feature but fully implemented e.g. an edit command that allows editing any field.
- A difficult feature with a reasonable implementation but some aspects are not covered undo/redo command that only allows a single undo/redo.
excellent: A difficult feature, all reasonable aspects are fully implemented undo/redo command that allows multiple undo/redo.
-
E. Amount of work []: Evaluate the amount of work, on a scale of 0 to 30.
- Consider this PR (
historycommand) as 5 units of effort which means this PR (undo/redocommand) is about 15 points of effort. Given that 30 points matches an effort twice as that needed for theundo/redofeature (which was given as an example of anAgrade project), we expect most students to be have efforts lower than 20. - Consider the main feature only. Exclude GUI inputs, but consider GUI outputs of the feature. Count all implementation/testing/documentation work as mentioned in that person's PPP. Also look at the actual code written by the person. We understand that it is not possible to know exactly which part of the code is for the main feature; make a best-guess judgement call based on the available info.
- Do not give a high value just to be nice. If your estimate is wildly inaccurate, it means you are unable to estimate the effort required to implement a feature in a project that you are supposed to know well at this point. You will lose marks if that is the case.
- Consider this PR (
-
Processing PE Bug Reports:
There will be a review period for you to respond to the bug reports you received.
Duration: The review period will start around 1 day after the PE (exact time to be announced) and will last until the following Wednesday midnight. However, you are recommended to finish this task ASAP, to minimize cutting into your exam preparation work.
Bug reviewing is recommended to be done as a team as some of the decisions need team consensus.
Instructions for Reviewing Bug Reports
-
First, don't freak out if there are lot of bug reports. Many can be duplicates and some can be false positives. In any case, we anticipate that all of these products will have some bugs and our penalty for bugs is not harsh. Furthermore, it depends on the severity of the bug. Some bug may not even be penalized.
-
Do not edit the subject or the description. Do not close bug reports. Your response (if any) should be added as a comment.
-
If the bug is reported multiple times, mark all copies EXCEPT one as duplicates using the
duplicatetag (if the duplicates have different severity levels, you should keep the one with the highest severity). In addition, use this technique to indicate which issue they are duplicates of. Duplicates can be omitted from processing steps given below. -
If a bug seems to be for a different product (i.e. wrongly assigned to your team), let us know (email prof).
-
Decide if it is a real bug and apply ONLY one of these labels.
Response Labels:
response.Accepted: You accept it as a bug.response.Rejected: What tester treated as a bug is in fact the expected behavior. The penalty for rejecting a bug using an unjustifiable explanation is higher than the penalty if the same bug was accepted. You can reject bugs that you inherited from AB4.response.CannotReproduce: You are unable to reproduce the behavior reported in the bug after multiple tries.response.IssueUnclear: The issue description is not clear.
- If applicable, decide the type of bug. Bugs without
type-are consideredtype-FunctionalityBugby default (which are liable to a heavier penalty):
Bug Type Labels:
type-FunctionalityBug: the bug is a flaw in how the product works.type-DocumentationBug: the bug is in the documentation.
- If you disagree with the original severity assigned to the bug, you may change it to the correct level, in which case add a comment justifying the change. All such changes will be double-checked by the teaching team and unreasonable lowering of severity will be penalized extra.:
Bug Severity labels:
severity.Low: A flaw that is unlikely to affect normal operations of the product. Appears only in very rare situations and causes a minor inconvenience only.severity.Medium: A flaw that causes occasional inconvenience to some users but they can continue to use the product.severity.High: A flaw that affects most users and causes major problems for users. i.e., makes the product almost unusable for most users.
-
Decide who should fix the bug. Use the
Assigneesfield to assign the issue to that person(s). There is no need to actually fix the bug though. It's simply an indication/acceptance of responsibility. If there is no assignee, we will distribute the penalty for that bug (if any) among all team members. -
Add an explanatory comment explaining your choice of labels and assignees.
- There is no requirement for a minimum coverage level. Note that in a production environment you are often required to have at least 90% of the code covered by tests. In this project, it can be less. The less coverage you have, the higher the risk of regression bugs, which will cost marks if not fixed before the final submission.
- You must write some tests so that we can evaluate your ability to write tests.
- How much of each type of testing should you do? We expect you to decide. You learned different types of testing and what they try to achieve. Based on that, you should decide how much of each type is required. Similarly, you can decide to what extent you want to automate tests, depending on the benefits and the effort required.
- Applying
TDD is optional. If you plan to test something, it is better to apply TDD because TDD ensures that you write functional code in a testable way. If you do it the normal way, you often find that it is hard to test the functional code because the code has low testability.
Evaluates: How good are the sections you wrote for the user guide and the developer guide?
Based on: the relevant sections of your project portfolio. Criteria considered:
- Explanation should be clear and written to match the audience.
- Good use of visuals to complement text.
- Use of correct UML notations (where applicable)
A. Process:
Evaluates: How well you did in project management related aspects of the project, as an individual and as a team
Based on: Supervisor observations of project milestones and GitHub data.
Milestones need to be reached the midnight before of the tutorial for it to be counted as achieved. To get a good grade for this aspect, achieve at least 60% of the recommended milestone progress.
Other criteria:
- Good use of GitHub milestones
- Good use of GitHub release mechanism
- Good version control, based on the repo
- Reasonable attempt to use the forking workflow
- Good task definition, assignment and tracking, based on the issue tracker
- Good use of buffers (opposite: everything at the last minute)
- Project done iteratively and incrementally (opposite: doing most of the work in one big burst)
B. Team-based tasks:
Evaluates: how much you contributed to common team-based tasks
Based on: peer evaluations and tutor observations
Relevant: [
Here is a non-exhaustive list of team-tasks:
- Necessary general code enhancements e.g.,
- Work related to renaming the product
- Work related to changing the product icon
- Morphing the product into a different product
- Setting up the GitHub, Travis, AppVeyor, etc.
- Maintaining the issue tracker
- Release management
- Updating user/developer docs that are not specific to a feature e.g. documenting the target user profile
- Incorporating more useful tools/libraries/frameworks into the product or the project workflow (e.g. automate more aspects of the project workflow using a GitHub plugin)
Policy on following instructions
When working with others, especially in a large class such as CS2103/T, it is very important that you adhere to standards, policies, and instructions imposed on everyone. Not doing so creates unnecessary headaches for everyone and puts your work attitude in a negative light. That is why we penalize repeated violations of instructions. On the other hand we do understand that humans are liable to make mistakes. That is why we only penalize repeated or frequent mistakes.
We use the TEAMMATES online peer evaluation system to conduct several rounds of peer-evaluations. All peer evaluations will be taken into account when determining your participation marks. The system also allows you to give anonymous feedback to your teammates.
Extra Requirements: [considered for participation marks]
- Submitting peer evaluations is compulsory. If you routinely miss submitting peer evaluations, you can lose participation marks.
- 💡 TEAMMATES normally allows students to access it without using Google login. In this module, we encourage (but not require) you to login to TEAMMATES using your Google account and complete your profile with a
suitable profile photo . Reason: CS2103/T is a big class. This profile helps us to remember you better, even after the module is over.
-
The purpose of the profile photo is for the teaching team to identify you. Therefore, you should choose a recent individual photo showing your face clearly (i.e., not too small) -- somewhat similar to a passport photo. Some examples can be seen in the 'Teaching team' page. Given below are some examples of good and bad profile photos.

-
If you are uncomfortable posting your photo due to security reasons, you can post a lower resolution image so that it is hard for someone to misuse that image for fraudulent purposes. If you are concerned about privacy, you can request permission to omit your photo from the page by writing to prof.
Peer evaluation criteria: professional conduct
- Professional Communication :
- Communicates sufficiently and professionally. e.g. Does not use offensive language or excessive slang in project communications.
- Responds to communication from team members in a timely manner (e.g. within 24 hours).
- Punctuality: Does not cause others to waste time or slow down project progress by frequent tardiness.
- Dependability: Promises what can be done, and delivers what was promised.
- Effort: Puts in sufficient effort to, and tries their best to keep up with the module/project pace. Seeks help from others when necessary.
- Quality: Does not deliver work products that seem to be below the student's competence level i.e. tries their best to make the work product as high quality as possible within her competency level.
- Meticulousness:
- Rarely overlooks submission requirements.
- Rarely misses compulsory module activities such as pre-module survey.
- Teamwork: How willing are you to act as part of a team, contribute to team-level tasks, adhere to team decisions, etc.
Peer evaluation criteria: competency
- Technical Competency: Able to gain competency in all the required tools and techniques.
- Mentoring skills: Helps others when possible. Able to mentor others well.
- Communication skills: Able to communicate (written and spoken) well. Takes initiative in discussions.
Giving constructive feedback to others is a valuable skill for software engineers. It is also an intended learning outcome of this module. Half-hearted/trivial feedback will not earn participation marks.
Here are some things to keep in mind:
- Assume you are giving feedback to a colleague, not a friend. Keep the tone of your feedback reasonably professional. Do not use offensive language or slang.
- The feedback should be honest and consistent. Giving positive qualitative feedback (e.g.
Thanks for all the hard work!and negative ratings (e.g.Equal share - 40%) to the same team member is not being honest. - State your expectations early. All too often students give positive/neutral feedback early (hoping that the team member will improve later) and trash the team member in the final evaluation (because the he/she did not improve as expected). However, this could be confusing to the recipient. It is better to give negative feedback early so that the team member gets a clear signal that he/she needs to improve.
Relevant: [
10 marks allocated for participation can be earned in the following ways (there are 30+ available marks to choose from):
-
Good peer ratings - Criteria for professional conduct (1 mark for each criterion, max 7)
- Competency criteria (2 marks for each, max 6)
- Quizzes
- In-lecture quizzes (1 each, max 10 marks)
Post-lecture quizzes (0.5 each, max 5 marks)
- Module admin tasks done on time and as instructed
- Peer evaluations (1 marks each, max 3)
- Pre-module survey (1 marks)
- Enhanced AB1-AB3 (2 mark each, max 6 marks)
Relevant: [
Peer evaluation criteria: professional conduct
- Professional Communication :
- Communicates sufficiently and professionally. e.g. Does not use offensive language or excessive slang in project communications.
- Responds to communication from team members in a timely manner (e.g. within 24 hours).
- Punctuality: Does not cause others to waste time or slow down project progress by frequent tardiness.
- Dependability: Promises what can be done, and delivers what was promised.
- Effort: Puts in sufficient effort to, and tries their best to keep up with the module/project pace. Seeks help from others when necessary.
- Quality: Does not deliver work products that seem to be below the student's competence level i.e. tries their best to make the work product as high quality as possible within her competency level.
- Meticulousness:
- Rarely overlooks submission requirements.
- Rarely misses compulsory module activities such as pre-module survey.
- Teamwork: How willing are you to act as part of a team, contribute to team-level tasks, adhere to team decisions, etc.
Peer evaluation criteria: competency
- Technical Competency: Able to gain competency in all the required tools and techniques.
- Mentoring skills: Helps others when possible. Able to mentor others well.
- Communication skills: Able to communicate (written and spoken) well. Takes initiative in discussions.
Relevant: [
There is no midterm.
The final exam has two parts:
- Part 1: MCQ questions (1 hour, 20 marks)
- Part 2: Essay questions (1 hour, 20 marks)
Both papers will be given to you at the start but you need to answer Part 1 first (i.e. MCQ paper). It will be collected 1 hour after the exam start time (even if arrived late for the exam). You are free to start part 2 early if you finish Part 1 early.
Final Exam: Part 1 (MCQ)
Each MCQ question gives you a statement to evaluate.
An example statement
Testing is a Q&A activity
Unless stated otherwise, the meaning of answer options are
A: Agree. If the question has multiple statements, agree with all of them.
B: Disagree. If the question has multiple statements, disagree with at least one of them
C, D, E: Not used
Number of questions: 100
Note that you have slightly more than ½ minute for each question, which means you need to go through the questions fairly quickly.
Given the fast pace required by the paper, to be fair to all students, you will not be allowed to clarify doubts about questions (in Part 1) by talking to invigilators.
- If a question is not clear, you can circle the question number in the question paper and write your doubt in the question paper, near that question.
- If your doubt is justified (e.g. there is a typo in the question) or if many students found the question to be unclear, the examiner may decide to omit that question from grading.
Questions in Part 1 are confidential. You are not allowed to reveal Part 1 content to anyone after the exam. All pages of the assessment paper are to be returned at the end of the exam.
You will be given OCR forms (i.e., bubble sheets) to indicate your answers for Part 1. As each OCR form can accommodate only 50 answers, you will be given 2 OCR forms. Indicate your student number in both OCR forms.
To save space, we use the following notation in MCQ question. [x | y | z] means ‘x and z, but not y’
SE is [boring | useful | fun] means SE is not boring AND SE is useful AND SE is fun.
Consider the following statement:
- IDEs can help with [writing | debugging | testing] code.
The correct response for it is Disagree because IDEs can help with all three of the given options, not just writing and testing.
Some questions will use underlines or highlighting to draw your attention to a specific part of the question. That is because those parts are highly relevant to the answer and we don’t want you to miss the relevance of that part.
Consider the statement below:
Technique ABC can be used to generate more test cases.
The word can is underlined because the decision you need to make is whether the ABC can or cannot be used to generate more test cases; the decision is not whether ABC can be used to generate more or better test cases.
Markers such as the one given below appears at left margin of the paper to indicate where the question corresponds to a new column in the OCR form. E.g. questions 11, 21, 31, etc. (a column has 10 questions). Such markers can help you to detect if you missed a question in the previous 10 questions. You can safely ignore those markers if you are not interested in making use of that additional hint.
Some questions have tags e.g., the question below has a tag JAVA. These tags provide additional context about the question. In the example below, the tag indicates that the code given in the question is Java code.

The exam paper is open-book: you may bring any printed or written materials to the exam in hard copy format. However, given the fast pace required by Part 1, you will not have time left to refer notes during that part of the exam.
💡 Mark the OCR form as you go, rather than planning to transfer your answers to the OCR form near the end. Reason: Given there are 100 questions, it will be hard to estimate how much time you need to mass-transfer all answers to OCR forms.
💡 Write the answer in the exam paper as well when marking it in the OCR form. Reason: It will reduce the chance of missing a question. Furthermore, in case you missed a question, it will help you correct the OCR form quickly.
💡 We have tried to avoid deliberately misleading/tricky questions. If a question seems to take a very long time to figure out, you are probably over-thinking it.
You will be given a practice exam paper to familiarize yourself with this slightly unusual exam format.
Final Exam: Part 2 (Essay)
Unlike in part 1, you can ask invigilators for clarifications if you found a question to be unclear in part 2.
Yes, you may use pencils when answering part 2.
Relevant: [
Note that project grading is not competitive (not bell curved). CS2103T projects will be assessed separately from CS2103 projects. This is to account for the perceived difference in workload. Given below is the marking scheme.
Total: 50 marks ( 40 individual marks + 10 team marks)
Evaluates: How well do your features fit together to form a cohesive product (not how many features or how big the features are)?
Based on: user guide and the product demo. The quality of the demo will be factored in as well.
💡 Feature that fit well with the other features will earn more marks.
Evaluates:
A. Code quality/quantity:
How good your implementation is, in terms of the quality and the quantity of the code you have written yourself.
Based on: an inspection of the parts of the code you claim as written by you.
-
Ensure your code has at least some evidence of these (see here for more info)
- logging
- exceptions
- assertions
- defensive coding
-
Ensure there are no coding standard violations e.g. all boolean variables/methods sounds like booleans. Checkstyle can prevent only some coding standard violations; others need to be checked manually.
-
Ensure SLAP is applied at a reasonable level. Long methods or deeply-nested code are symptoms of low-SLAP may be counted against your code quality.
-
Reduce code duplications i.e. if there multiple blocks of code that vary only in minor ways, try to extract out similarities into one place, especially in test code.
-
In addition, try to apply as many of the
code quality guidelines covered in the module as much as you can.
Can explain the importance of code quality
Always code as if the person who ends up maintaining your code will be a violent psychopath who knows where you live. -- Martin Golding
Can explain the importance of readability
Programs should be written and polished until they acquire publication quality. --Niklaus Wirth
Among various dimensions of code quality, such as run-time efficiency, security, and robustness, one of the most important is understandability. This is because in any non-trivial software project, code needs to be read, understood, and modified by other developers later on. Even if we do not intend to pass the code to someone else, code quality is still important because we all become 'strangers' to our own code someday.
The two code samples given below achieve the same functionality, but one is easier to read.
|
Bad |
|
Good |
|
Bad |
|
Good |
Can improve code quality using technique: avoid long methods
Be wary when a method is longer than the computer screen, and take corrective action when it goes beyond 30 LOC (lines of code). The bigger the haystack, the harder it is to find a needle.
Can improve code quality using technique: avoid deep nesting
If you need more than 3 levels of indentation, you're screwed anyway, and should fix your program. --Linux 1.3.53 CodingStyle
In particular, avoid arrowhead style code.
Example:
Can improve code quality using technique: avoid complicated expressions
Avoid complicated expressions, especially those having many negations and nested parentheses. If you must evaluate complicated expressions, have it done in steps (i.e. calculate some intermediate values first and use them to calculate the final value).
Example:
Bad
return ((length < MAX_LENGTH) || (previousSize != length)) && (typeCode == URGENT);
Good
boolean isWithinSizeLimit = length < MAX_LENGTH;
boolean isSameSize = previousSize != length;
boolean isValidCode = isWithinSizeLimit || isSameSize;
boolean isUrgent = typeCode == URGENT;
return isValidCode && isUrgent;
Example:
Bad
return ((length < MAX_LENGTH) or (previous_size != length)) and (type_code == URGENT)
Good
is_within_size_limit = length < MAX_LENGTH
is_same_size = previous_size != length
is_valid_code = is_within_size_limit or is_same_size
is_urgent = type_code == URGENT
return is_valid_code and is_urgent
The competent programmer is fully aware of the strictly limited size of his own skull; therefore he approaches the programming task in full humility, and among other things he avoids clever tricks like the plague. -- Edsger Dijkstra
Can improve code quality using technique: avoid magic numbers
When the code has a number that does not explain the meaning of the number, we call that a magic number (as in “the number appears as if by magic”). Using a
Example:
|
Bad |
|
Good |
Note: Python does not have a way to make a variable a constant. However, you can use a normal variable with an ALL_CAPS name to simulate a constant.
|
Bad |
|
Good |
Similarly, we can have ‘magic’ values of other data types.
Bad
"Error 1432" // A magic string!
Can improve code quality using technique: make the code obvious
Make the code as explicit as possible, even if the language syntax allows them to be implicit. Here are some examples:
- [
Java] Use explicit type conversion instead of implicit type conversion. - [
Java,Python] Use parentheses/braces to show grouping even when they can be skipped. - [
Java,Python] Useenumerations when a certain variable can take only a small number of finite values. For example, instead of declaring the variable 'state' as an integer and using values 0,1,2 to denote the states 'starting', 'enabled', and 'disabled' respectively, declare 'state' as typeSystemStateand define an enumerationSystemStatethat has values'STARTING','ENABLED', and'DISABLED'.
Can improve code quality using technique: structure code logically
Lay out the code so that it adheres to the logical structure. The code should read like a story. Just like we use section breaks, chapters and paragraphs to organize a story, use classes, methods, indentation and line spacing in your code to group related segments of the code. For example, you can use blank lines to group related statements together. Sometimes, the correctness of your code does not depend on the order in which you perform certain intermediary steps. Nevertheless, this order may affect the clarity of the story you are trying to tell. Choose the order that makes the story most readable.
Can improve code quality using technique: do not 'trip up' reader
Avoid things that would make the reader go ‘huh?’, such as,
- unused parameters in the method signature
- similar things look different
- different things that look similar
- multiple statements in the same line
- data flow anomalies such as, pre-assigning values to variables and modifying it without any use of the pre-assigned value
Can improve code quality using technique: practice kissing
As the old adage goes, "keep it simple, stupid” (KISS). Do not try to write ‘clever’ code. For example, do not dismiss the brute-force yet simple solution in favor of a complicated one because of some ‘supposed benefits’ such as 'better reusability' unless you have a strong justification.
Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it. --Brian W. Kernighan
Programs must be written for people to read, and only incidentally for machines to execute. --Abelson and Sussman
Can improve code quality using technique: avoid premature optimizations
Optimizing code prematurely has several drawbacks:
- We may not know which parts are the real performance bottlenecks. This is especially the case when the code undergoes transformations (e.g. compiling, minifying, transpiling, etc.) before it becomes an executable. Ideally, you should use a profiler tool to identify the actual bottlenecks of the code first, and optimize only those parts.
- Optimizing can complicate the code, affecting correctness and understandability
- Hand-optimized code can be harder for the compiler to optimize (the simpler the code, the easier for the compiler to optimize it). In many cases a compiler can do a better job of optimizing the runtime code if you don't get in the way by trying to hand-optimize the source code.
A popular saying in the industry is make it work, make it right, make it fast which means in most cases getting the code to perform correctly should take priority over optimizing it. If the code doesn't work correctly, it has no value on matter how fast/efficient it it.
Premature optimization is the root of all evil in programming. --Donald Knuth
Note that there are cases where optimizing takes priority over other things e.g. when writing code for resource-constrained environments. This guideline simply a caution that you should optimize only when it is really needed.
Can improve code quality using technique: SLAP hard
Avoid varying the level of
Example:
Bad
readData();
salary = basic*rise+1000;
tax = (taxable?salary*0.07:0);
displayResult();
Good
readData();
processData();
displayResult();
Design → Design Fundamentals → Abstraction →
Abstraction is a technique for dealing with complexity. It works by establishing a level of complexity we are interested in, and suppressing the more complex details below that level.
The guiding principle of abstraction is that only details that are relevant to the current perspective or the task at hand needs to be considered. As most programs are written to solve complex problems involving large amounts of intricate details, it is impossible to deal with all these details at the same time. That is where abstraction can help.
Ignoring lower level data items and thinking in terms of bigger entities is called data abstraction.
Within a certain software component, we might deal with a user data type, while ignoring the details contained in the user data item such as name, and date of birth. These details have been ‘abstracted away’ as they do not affect the task of that software component.
Control abstraction abstracts away details of the actual control flow to focus on tasks at a simplified level.
print(“Hello”) is an abstraction of the actual output mechanism within the computer.
Abstraction can be applied repeatedly to obtain progressively higher levels of abstractions.
An example of different levels of data abstraction: a File is a data item that is at a higher level than an array and an array is at a higher level than a bit.
An example of different levels of control abstraction: execute(Game) is at a higher level than print(Char) which is at a higher than an Assembly language instruction MOV.
Abstraction is a general concept that is not limited to just data or control abstractions.
Some more general examples of abstraction:
- An OOP class is an abstraction over related data and behaviors.
- An architecture is a higher-level abstraction of the design of a software.
- Models (e.g., UML models) are abstractions of some aspect of reality.
Can improve code quality using technique: make the happy path prominent
The happy path (i.e. the execution path taken when everything goes well) should be clear and prominent in your code. Restructure the code to make the happy path unindented as much as possible. It is the ‘unusual’ cases that should be indented. Someone reading the code should not get distracted by alternative paths taken when error conditions happen. One technique that could help in this regard is the use of guard clauses.
Example:
Bad
if (!isUnusualCase) { //detecting an unusual condition
if (!isErrorCase) {
start(); //main path
process();
cleanup();
exit();
} else {
handleError();
}
} else {
handleUnusualCase(); //handling that unusual condition
}
In the code above,
- Unusual condition detection is separated from their handling.
- Main path is nested deeply.
Good
if (isUnusualCase) { //Guard Clause
handleUnusualCase();
return;
}
if (isErrorCase) { //Guard Clause
handleError();
return;
}
start();
process();
cleanup();
exit();
In contrast, the above code
- deals with unusual conditions as soon as they are detected so that the reader doesn't have to remember them for long.
- keeps the main path un-indented.
Can explain the need for following a standard
One essential way to improve code quality is to follow a consistent style. That is why software engineers follow a strict coding standard (aka style guide).
The aim of a coding standard is to make the entire code base look like it was written by one person. A coding standard is usually specific to a programming language and specifies guidelines such as the location of opening and closing braces, indentation styles and naming styles (e.g. whether to use Hungarian style, Pascal casing, Camel casing, etc.). It is important that the whole team/company use the same coding standard and that standard is not generally inconsistent with typical industry practices. If a company's coding standards is very different from what is used typically in the industry, new recruits will take longer to get used to the company's coding style.
💡 IDEs can help to enforce some parts of a coding standard e.g. indentation rules.
What is the recommended approach regarding coding standards?
c
What is the aim of using a coding standard? How does it help?
Can follow simple mechanical style rules
Learn basic guidelines of the Java coding standard (by OSS-Generic)
Sample coding standard: PEP 8 Python Style Guide -- by Python.org
Consider the code given below:
import java.util.*;
public class Task {
public static final String descriptionPrefix = "description: ";
private String description;
private boolean important;
List<String> pastDescription = new ArrayList<>(); // a list of past descriptions
public Task(String d) {
this.description = d;
if (!d.isEmpty())
this.important = true;
}
public String getAsXML() { return "<task>"+description+"</task>"; }
/**
* Print the description as a string.
*/
public void printingDescription(){ System.out.println(this); }
@Override
public String toString() { return descriptionPrefix + description; }
}
In what ways the code violate the basic guidelines (i.e., those marked with one ⭐️) of the OSS-Generic Java Coding Standard given here?
Here are three:
descriptionPrefixis a constant and should be namedDESCRIPTION_PREFIX- method name
printingDescription()should be named asprintDescription() - boolean variable
importantshould be named to sound boolean e.g.,isImportant
There are many more.
Can follow intermediate style rules
Go through the provided Java coding standard and learn the intermediate style rules.
According to the given Java coding standard, which one of these is not a good name?
b
Explanation: checkWeight is an action. Naming variables as actions makes the code harder to follow. isWeightValid may be a better name.
Repeat the exercise in the panel below but also find violations of intermediate level guidelines.
Consider the code given below:
import java.util.*;
public class Task {
public static final String descriptionPrefix = "description: ";
private String description;
private boolean important;
List<String> pastDescription = new ArrayList<>(); // a list of past descriptions
public Task(String d) {
this.description = d;
if (!d.isEmpty())
this.important = true;
}
public String getAsXML() { return "<task>"+description+"</task>"; }
/**
* Print the description as a string.
*/
public void printingDescription(){ System.out.println(this); }
@Override
public String toString() { return descriptionPrefix + description; }
}
In what ways the code violate the basic guidelines (i.e., those marked with one ⭐️) of the OSS-Generic Java Coding Standard given here?
Here are three:
descriptionPrefixis a constant and should be namedDESCRIPTION_PREFIX- method name
printingDescription()should be named asprintDescription() - boolean variable
importantshould be named to sound boolean e.g.,isImportant
There are many more.
Here's one you are more likely to miss:
* Print the description as a string.→* Prints the description as a string.
There are more.
Can explain the need for good names in code
Proper naming improves the readability. It also reduces bugs caused by ambiguities regarding the intent of a variable or a method.
There are only two hard things in Computer Science: cache invalidation and naming things. -- Phil Karlton
Can improve code quality using technique: use nouns for things and verbs for actions
Every system is built from a domain-specific language designed by the programmers to describe that system. Functions are the verbs of that language, and classes are the nouns. ― Robert C. Martin, Clean Code: A Handbook of Agile Software Craftsmanship
Use nouns for classes/variables and verbs for methods/functions.
Examples:
| Name for a | Bad | Good |
|---|---|---|
| Class | CheckLimit |
LimitChecker |
| method | result() |
calculate() |
Distinguish clearly between single-valued and multivalued variables.
Examples:
Good
Person student;
ArrayList<Person> students;
Good
student = Person('Jim')
students = [Person('Jim'), Person('Alice')]
Can improve code quality using technique: use standard words
Use correct spelling in names. Avoid 'texting-style' spelling. Avoid foreign language words, slang, and names that are only meaningful within specific contexts/times e.g. terms from private jokes, a TV show currently popular in your country
Can improve code quality using technique: use name to explain
A name is not just for differentiation; it should explain the named entity to the reader accurately and at a sufficient level of detail.
Examples:
| Bad | Good |
|---|---|
processInput() (what 'process'?) |
removeWhiteSpaceFromInput() |
flag |
isValidInput |
temp |
If the name has multiple words, they should be in a sensible order.
Examples:
| Bad | Good |
|---|---|
bySizeOrder() |
orderBySize() |
Imagine going to the doctor's and saying "My eye1 is swollen"! Don’t use numbers or case to distinguish names.
Examples:
| Bad | Bad | Good |
|---|---|---|
value1, value2 |
value, Value |
originalValue, finalValue |
Can improve code quality using technique: not too long, not too short
While it is preferable not to have lengthy names, names that are 'too short' are even worse. If you must abbreviate or use acronyms, do it consistently. Explain their full meaning at an obvious location.
Can improve code quality using technique: avoid misleading names
Related things should be named similarly, while unrelated things should NOT.
Example: Consider these variables
colorBlack: hex value for color blackcolorWhite: hex value for color whitecolorBlue: number of times blue is usedhexForRed: : hex value for color red
This is misleading because colorBlue is named similar to colorWhite and colorBlack but has a different purpose while hexForRed is named differently but has very similar purpose to the first two variables. The following is better:
hexForBlackhexForWhitehexForRedblueColorCount
Avoid misleading or ambiguous names (e.g. those with multiple meanings), similar sounding names, hard-to-pronounce ones (e.g. avoid ambiguities like "is that a lowercase L, capital I or number 1?", or "is that number 0 or letter O?"), almost similar names.
Examples:
| Bad | Good | Reason |
|---|---|---|
phase0 |
phaseZero |
Is that zero or letter O? |
rwrLgtDirn |
rowerLegitDirection |
Hard to pronounce |
right left wrong |
rightDirection leftDirection wrongResponse |
right is for 'correct' or 'opposite of 'left'? |
redBooks readBooks |
redColorBooks booksRead |
red and read (past tense) sounds the same |
FiletMignon |
egg |
If the requirement is just a name of a food, egg is a much easier to type/say choice than FiletMignon |
Can explain the need for avoiding error-prone shortcuts
It is safer to use language constructs in the way they are meant to be used, even if the language allows shortcuts. Some such coding practices are common sources of bugs. Know them and avoid them.
Can improve code quality using technique: use the default branch
Always include a default branch in case statements.
Furthermore, use it for the intended default action and not just to execute the last option. If there is no default action, you can use the 'default' branch to detect errors (i.e. if execution reached the default branch, throw an exception). This also applies to the final else of an if-else construct. That is, the final else should mean 'everything else', and not the final option. Do not use else when an if condition can be explicitly specified, unless there is absolutely no other possibility.
Bad
if (red) print "red";
else print "blue";
Good
if (red) print "red";
else if (blue) print "blue";
else error("incorrect input");
Can improve code quality using technique: don't recycle variables or parameters
- Use one variable for one purpose. Do not reuse a variable for a different purpose other than its intended one, just because the data type is the same.
- Do not reuse formal parameters as local variables inside the method.
Bad
double computeRectangleArea(double length, double width) {
length = length * width;
return length;
}
Good
double computeRectangleArea(double length, double width) {
double area;
area = length * width;
return area;
}
Can improve code quality using technique: avoid empty catch blocks
Never write an empty catch statement. At least give a comment to explain why the catch block is left empty.
Can improve code quality using technique: delete dead code
We all feel reluctant to delete code we have painstakingly written, even if we have no use for that code any more ("I spent a lot of time writing that code; what if we need it again?"). Consider all code as baggage you have to carry; get rid of unused code the moment it becomes redundant. If you need that code again, simply recover it from the revision control tool you are using. Deleting code you wrote previously is a sign that you are improving.
Can improve code quality using technique: minimise scope of variables
Minimize global variables. Global variables may be the most convenient way to pass information around, but they do create implicit links between code segments that use the global variable. Avoid them as much as possible.
Define variables in the least possible scope. For example, if the variable is used only within the if block of the conditional statement, it should be declared inside that if block.
The most powerful technique for minimizing the scope of a local variable is to declare it where it is first used. -- Effective Java, by Joshua Bloch
Resources:
Can improve code quality using technique: minimise code duplication
Code duplication, especially when you copy-paste-modify code, often indicates a poor quality implementation. While it may not be possible to have zero duplication, always think twice before duplicating code; most often there is a better alternative.
This guideline is closely related to the
Supplmentary → Principles →
DRY (Don't Repeat Yourself) Principle: Every piece of knowledge must have a single, unambiguous, authoritative representation within a system The Pragmatic Programmer, by Andy Hunt and Dave Thomas
This principle guards against duplication of information.
The functionality implemented twice is a violation of the DRY principle even if the two implementations are different.
The value a system-wide timeout being defined in multiple places is a violation of DRY.
Can explain the need for commenting minimally but sufficiently
Good code is its own best documentation. As you’re about to add a comment, ask yourself, ‘How can I improve the code so that this comment isn’t needed?’ Improve the code and then document it to make it even clearer. --Steve McConnell, Author of Clean Code
Some think commenting heavily increases the 'code quality'. This is not so. Avoid writing comments to explain bad code. Improve the code to make it self-explanatory.
Can improve code quality using technique: do not repeat the obvious
If the code is self-explanatory, refrain from repeating the description in a comment just for the sake of 'good documentation'.
Bad
// increment x
x++;
//trim the input
trimInput();
Can improve code quality using technique: write to the reader
Do not write comments as if they are private notes to self. Instead, write them well enough to be understood by another programmer. One type of comments that is almost always useful is the header comment that you write for a class or an operation to explain its purpose.
Examples:
Bad Reason: this comment will only make sense to the person who wrote it
// a quick trim function used to fix bug I detected overnight
void trimInput(){
....
}
Good
/** Trims the input of leading and trailing spaces */
void trimInput(){
....
}
Bad Reason: this comment will only make sense to the person who wrote it
# a quick trim function used to fix bug I detected overnight
def trim_input():
...
Good
def trim_input():
"""Trim the input of leading and trailing spaces"""
...
Can improve code quality using technique: explain what and why, not how
Comments should explain what and why aspect of the code, rather than the how aspect.
What : The specification of what the code supposed to do. The reader can compare such comments to the implementation to verify if the implementation is correct
Example: This method is possibly buggy because the implementation does not seem to match the comment. In this case the comment could help the reader to detect the bug.
/** Removes all spaces from the {@code input} */
void compact(String input){
input.trim();
}
Why : The rationale for the current implementation.
Example: Without this comment, the reader will not know the reason for calling this method.
// Remove spaces to comply with IE23.5 formatting rules
compact(input);
How : The explanation for how the code works. This should already be apparent from the code, if the code is self-explanatory. Adding comments to explain the same thing is redundant.
Example:
Bad Reason: Comment explains how the code works.
// return true if both left end and right end are correct or the size has not incremented
return (left && right) || (input.size() == size);
Good Reason: Code refactored to be self-explanatory. Comment no longer needed.
boolean isSameSize = (input.size() == size) ;
return (isLeftEndCorrect && isRightEndCorrect) || isSameSize;
null
B. Depth and completeness of your feature
Evaluates: How good is your Quality Assurance?
Based on: 1. your test code 2. our own manual testing 3. your performance in the v1.4 Practical Exam, 4. bugs found during PE.
Relevant: [
Objectives:
- Evaluate your manual testing skills, product evaluation skills, effort estimation skills
- Peer-evaluate your product design , implementation effort , documentation quality
When, where: Week 13 lecture
Grading:
- Your performance in the practical exam will be considered for your final grade (under the QA category and under Implementation category, about 10 marks in total).
- You will be graded based on your effectiveness as a tester (e.g., the percentage of the bugs you found, the nature of the bugs you found) and how far off your evaluation/estimates are from the evaluator consensus. Explanation: we understand that you have limited expertise in this area; hence, we penalize only if your inputs don't seem to be based on a sincere effort to test/evaluate.
- The bugs found in your product by others will affect your v1.4 marks. You will be given a chance to reject false-positive bug reports.
Preparation:
-
Ensure that you can access the relevant issue tracker given below:
-- for PE Dry Run (at v1.3): nus-cs2103-AY1819S1/pe-dry-run
-- for PE (at v1.4): nus-cs2103-AY1819S1/pe (will open only near the actual PE)- These are private repos!. If you cannot access the relevant repo, you may not have accepted the invitation to join the GitHub org used by the module. Go to https://github.com/orgs/nus-cs2103-AY1819S1/invitation to accept the invitation.
- If you cannot find the invitation, post in our forum.
-
Ensure you have access to a computer that is able to run module projects e.g. has the right Java version.
-
Have a good screen grab tool with annotation features so that you can quickly take a screenshot of a bug, annotate it, and post in the issue tracker.
- 💡 You can use Ctrl+V to paste a picture from the clipboard into a text box in GitHub issue tracker.
-
Charge your computer before coming to the PE session. The testing venue may not have enough charging points.
During:
- Take note of your team to test. It will be given to you by the teaching team (distributed via IVLE gradebook).
- Download from IVLE all files submitted by the team (i.e. jar file, User Guide, Developer Guide, and Project Portfolio Pages) into an empty folder.
- [~40 minutes] Test the product and report bugs as described below:
Testing instructions for PE and PE Dry Run
-
What to test:
- PE Dry Run (at v1.3):
- Test the product based on the User Guide (the UG is most likely accessible using the
helpcommand). - Do system testing first i.e., does the product work as specified by the documentation?. If there is time left, you can do acceptance testing as well i.e., does the product solve the problem it claims to solve?.
- Test the product based on the User Guide (the UG is most likely accessible using the
- PE (at v1.4):
- Test based on the Developer Guide (Appendix named Instructions for Manual Testing) and the User Guide. The testing instructions in the Developer Guide can provide you some guidance but if you follow those instructions strictly, you are unlikely to find many bugs. You can deviate from the instructions to probe areas that are more likely to have bugs.
- Do system testing only i.e., verify actual behavior against documented behavior. Do not do acceptance testing.
- PE Dry Run (at v1.3):
-
What not to test:
- Omit features that are driven by GUI inputs (e.g. buttons, menus, etc.) Reason: Only CLI-driven features can earn credit, as per given project constraints. Some features might have both a GUI-driven and CLI-driven ways to invoke them, in which case test only the CLI-driven way of invoking it.
- Omit feature that existed in AB-4.
-
These are considered bugs:
- Behavior differs from the User Guide
- A legitimate user behavior is not handled e.g. incorrect commands, extra parameters
- Behavior is not specified and differs from normal expectations e.g. error message does not match the error
- Problems in the User Guide e.g., missing/incorrect info
-
Where to report bugs: Post bug in the following issue trackers (not in the team's repo):
- PE Dry Run (at v1.3): nus-cs2103-AY1819S1/pe-dry-run.
- PE (at v1.4): nus-cs2103-AY1819S1/pe.
-
Bug report format:
- Post bugs as you find them (i.e., do not wait to post all bugs at the end) because the issue tracker will close exactly at the end of the allocated time.
- Do not use team ID in bug reports. Reason: to prevent others copying your bug reports
- Each bug should be a separate issue.
- Write good quality bug reports; poor quality or incorrect bug reports will not earn credit.
- Use a descriptive title.
- Give a good description of the bug with steps to reproduce and screenshots.
- Assign a severity to the bug report. Bug report without a priority label are considered
severity.Low(lower severity bugs earn lower credit):
Bug Severity labels:
severity.Low: A flaw that is unlikely to affect normal operations of the product. Appears only in very rare situations and causes a minor inconvenience only.severity.Medium: A flaw that causes occasional inconvenience to some users but they can continue to use the product.severity.High: A flaw that affects most users and causes major problems for users. i.e., makes the product almost unusable for most users.
-
About posting suggestions:
- PE Dry Run (at v1.3): You can also post suggestions on how to improve the product. 💡 Be diplomatic when reporting bugs or suggesting improvements. For example, instead of criticising the current behavior, simply suggest alternatives to consider.
- PE (at v1.4): Do not post suggestions.
-
If the product doesn't work at all: If the product fails catastrophically e.g., cannot even launch, you can test the fallback team allocated to you. But in this case you must inform us immediately after the session so that we can send your bug reports to the correct team.
-
[~50 minutes] Evaluate the following aspects. Note down your evaluation in a hard copy (as a backup). Submit via TEAMMATES.
-
A. Cohesiveness of product features []: Do the features fit together and match the stated target user and the value proposition?
unable to judge: You are unable to judge this aspect for some reason.low: One of these- target user is too general i.e. wider than AB4
- target user and/or value proposition not clear from the user guide
- features don't seem to fit together for the most part
medium: Some features fit together but some don't.high: All features fit together but the features are not very high value to the target user.excellent: The target user is clearly defined (not too general) and almost all new features are of high-value to the target user. i.e. the product is very attractive to the target user.
-
B. Quality of user docs []: Evaluate based on the parts of the user guide written by the person, as reproduced in the project portfolio. Evaluate from an end-user perspective.
unable to judge: Less than 1 page worth of UG content written by the student.low: Hard to understand, often inaccurate or missing important information.medium: Needs some effort to understand; some information is missing.high: Mostly easy to follow. Only a few areas need improvements.excellent: Easy to follow and accurate. Just enough information, visuals, examples etc. (not too much either). Understandable to the target end user.
-
C. Quality of developer docs []: Evaluate based on the developer docs cited/reproduced in the respective project portfolio page. Evaluate from the perspective of a new developer trying to understand how the features are implemented.
unable to judge: One of these- less than 0.5 pages worth of content.
- other problems in the document e.g. looks like included wrong content.
low: One of these- Very small amount of content (i.e., 0.5 - 1 page).
- Hardly any use to the reader (i.e., content doesn't make much sense or redundant).
- Uses ad-hoc diagrams where UML diagrams could have been used instead.
- Multiple notation errors in UML diagrams.
medium: Some diagrams, some descriptions, but does not help the reader that much e.g. overly complicated diagrams.high: Enough diagrams (at lest two kinds of UML diagrams used) and enough descriptions (about 2 pages worth) but explanations are not always easy to follow.excellent: Easy to follow. Just enough information (not too much). Minimum repetition of content/diagrams. Good use of diagrams to complement text descriptions. Easy to understand diagrams with just enough details rather than very complicated diagrams that are hard to understand.
-
D. Depth of feature []: Evaluate the feature done by the student for difficulty, depth, and completeness. Note: examples given below assume that AB4 did not have the commands
edit,undo, andredo.unable to judge: You are unable to judge this aspect for some reason.low: An easy feature e.g. make the existing find command case insensitive.medium: Moderately difficult feature, barely acceptable implementation e.g. an edit command that requires the user to type all fields, even the ones that are not being edited.high: One of the below- A moderately difficult feature but fully implemented e.g. an edit command that allows editing any field.
- A difficult feature with a reasonable implementation but some aspects are not covered undo/redo command that only allows a single undo/redo.
excellent: A difficult feature, all reasonable aspects are fully implemented undo/redo command that allows multiple undo/redo.
-
E. Amount of work []: Evaluate the amount of work, on a scale of 0 to 30.
- Consider this PR (
historycommand) as 5 units of effort which means this PR (undo/redocommand) is about 15 points of effort. Given that 30 points matches an effort twice as that needed for theundo/redofeature (which was given as an example of anAgrade project), we expect most students to be have efforts lower than 20. - Consider the main feature only. Exclude GUI inputs, but consider GUI outputs of the feature. Count all implementation/testing/documentation work as mentioned in that person's PPP. Also look at the actual code written by the person. We understand that it is not possible to know exactly which part of the code is for the main feature; make a best-guess judgement call based on the available info.
- Do not give a high value just to be nice. If your estimate is wildly inaccurate, it means you are unable to estimate the effort required to implement a feature in a project that you are supposed to know well at this point. You will lose marks if that is the case.
- Consider this PR (
-
Processing PE Bug Reports:
There will be a review period for you to respond to the bug reports you received.
Duration: The review period will start around 1 day after the PE (exact time to be announced) and will last until the following Wednesday midnight. However, you are recommended to finish this task ASAP, to minimize cutting into your exam preparation work.
Bug reviewing is recommended to be done as a team as some of the decisions need team consensus.
Instructions for Reviewing Bug Reports
-
First, don't freak out if there are lot of bug reports. Many can be duplicates and some can be false positives. In any case, we anticipate that all of these products will have some bugs and our penalty for bugs is not harsh. Furthermore, it depends on the severity of the bug. Some bug may not even be penalized.
-
Do not edit the subject or the description. Do not close bug reports. Your response (if any) should be added as a comment.
-
If the bug is reported multiple times, mark all copies EXCEPT one as duplicates using the
duplicatetag (if the duplicates have different severity levels, you should keep the one with the highest severity). In addition, use this technique to indicate which issue they are duplicates of. Duplicates can be omitted from processing steps given below. -
If a bug seems to be for a different product (i.e. wrongly assigned to your team), let us know (email prof).
-
Decide if it is a real bug and apply ONLY one of these labels.
Response Labels:
response.Accepted: You accept it as a bug.response.Rejected: What tester treated as a bug is in fact the expected behavior. The penalty for rejecting a bug using an unjustifiable explanation is higher than the penalty if the same bug was accepted. You can reject bugs that you inherited from AB4.response.CannotReproduce: You are unable to reproduce the behavior reported in the bug after multiple tries.response.IssueUnclear: The issue description is not clear.
- If applicable, decide the type of bug. Bugs without
type-are consideredtype-FunctionalityBugby default (which are liable to a heavier penalty):
Bug Type Labels:
type-FunctionalityBug: the bug is a flaw in how the product works.type-DocumentationBug: the bug is in the documentation.
- If you disagree with the original severity assigned to the bug, you may change it to the correct level, in which case add a comment justifying the change. All such changes will be double-checked by the teaching team and unreasonable lowering of severity will be penalized extra.:
Bug Severity labels:
severity.Low: A flaw that is unlikely to affect normal operations of the product. Appears only in very rare situations and causes a minor inconvenience only.severity.Medium: A flaw that causes occasional inconvenience to some users but they can continue to use the product.severity.High: A flaw that affects most users and causes major problems for users. i.e., makes the product almost unusable for most users.
-
Decide who should fix the bug. Use the
Assigneesfield to assign the issue to that person(s). There is no need to actually fix the bug though. It's simply an indication/acceptance of responsibility. If there is no assignee, we will distribute the penalty for that bug (if any) among all team members. -
Add an explanatory comment explaining your choice of labels and assignees.
- There is no requirement for a minimum coverage level. Note that in a production environment you are often required to have at least 90% of the code covered by tests. In this project, it can be less. The less coverage you have, the higher the risk of regression bugs, which will cost marks if not fixed before the final submission.
- You must write some tests so that we can evaluate your ability to write tests.
- How much of each type of testing should you do? We expect you to decide. You learned different types of testing and what they try to achieve. Based on that, you should decide how much of each type is required. Similarly, you can decide to what extent you want to automate tests, depending on the benefits and the effort required.
- Applying
TDD is optional. If you plan to test something, it is better to apply TDD because TDD ensures that you write functional code in a testable way. If you do it the normal way, you often find that it is hard to test the functional code because the code has low testability.
Evaluates: How good are the sections you wrote for the user guide and the developer guide?
Based on: the relevant sections of your project portfolio. Criteria considered:
- Explanation should be clear and written to match the audience.
- Good use of visuals to complement text.
- Use of correct UML notations (where applicable)
A. Process:
Evaluates: How well you did in project management related aspects of the project, as an individual and as a team
Based on: Supervisor observations of project milestones and GitHub data.
Milestones need to be reached the midnight before of the tutorial for it to be counted as achieved. To get a good grade for this aspect, achieve at least 60% of the recommended milestone progress.
Other criteria:
- Good use of GitHub milestones
- Good use of GitHub release mechanism
- Good version control, based on the repo
- Reasonable attempt to use the forking workflow
- Good task definition, assignment and tracking, based on the issue tracker
- Good use of buffers (opposite: everything at the last minute)
- Project done iteratively and incrementally (opposite: doing most of the work in one big burst)
B. Team-based tasks:
Evaluates: how much you contributed to common team-based tasks
Based on: peer evaluations and tutor observations
Relevant: [
Here is a non-exhaustive list of team-tasks:
- Necessary general code enhancements e.g.,
- Work related to renaming the product
- Work related to changing the product icon
- Morphing the product into a different product
- Setting up the GitHub, Travis, AppVeyor, etc.
- Maintaining the issue tracker
- Release management
- Updating user/developer docs that are not specific to a feature e.g. documenting the target user profile
- Incorporating more useful tools/libraries/frameworks into the product or the project workflow (e.g. automate more aspects of the project workflow using a GitHub plugin)
10 marks allocated for participation can be earned in the following ways (there are 30+ available marks to choose from):
-
Good peer ratings - Criteria for professional conduct (1 mark for each criterion, max 7)
- Competency criteria (2 marks for each, max 6)
- Quizzes
- In-lecture quizzes (1 each, max 10 marks)
Post-lecture quizzes (0.5 each, max 5 marks)
- Module admin tasks done on time and as instructed
- Peer evaluations (1 marks each, max 3)
- Pre-module survey (1 marks)
- Enhanced AB1-AB3 (2 mark each, max 6 marks)
Relevant: [
Peer evaluation criteria: professional conduct
- Professional Communication :
- Communicates sufficiently and professionally. e.g. Does not use offensive language or excessive slang in project communications.
- Responds to communication from team members in a timely manner (e.g. within 24 hours).
- Punctuality: Does not cause others to waste time or slow down project progress by frequent tardiness.
- Dependability: Promises what can be done, and delivers what was promised.
- Effort: Puts in sufficient effort to, and tries their best to keep up with the module/project pace. Seeks help from others when necessary.
- Quality: Does not deliver work products that seem to be below the student's competence level i.e. tries their best to make the work product as high quality as possible within her competency level.
- Meticulousness:
- Rarely overlooks submission requirements.
- Rarely misses compulsory module activities such as pre-module survey.
- Teamwork: How willing are you to act as part of a team, contribute to team-level tasks, adhere to team decisions, etc.
Peer evaluation criteria: competency
- Technical Competency: Able to gain competency in all the required tools and techniques.
- Mentoring skills: Helps others when possible. Able to mentor others well.
- Communication skills: Able to communicate (written and spoken) well. Takes initiative in discussions.
Your tutor will serve as your project supervisor too.
The supervisor's main job is to observe, facilitate self/peer learning, evaluate, and give feedback.
Tutorial time is the main avenue for meeting your supervisor. In addition, you can meet the supervisor before/after the tutorial, or any other time, as many times you need, subject to availability in his/her schedule.
Note that it is not the supervisor’s job to chase you down and give help. It is up to you to get as much feedback from the as you need. You are free to request more feedback from the supervisor as necessary. Similarly, it is not the job of the supervisor to lead your project to success.
What if I don’t carry around a laptop?
If you do not have a laptop or prefer not to bring the laptop, it is up to you to show your work to the tutor in some way (e.g. by connecting to your home PC remotely), without requiring extra time/effort from the tutor or team members.
Reason: As you enjoy the benefits of not bring the laptop; you (not others) should bear the cost too.
Outcomes
Implementation
W3.1 Can refactor code at a basic level
W3.1a Can explain refactoring
Implementation → Refactoring →
The first version of the code you write may not be of production quality. It is OK to first concentrate on making the code work, rather than worry over the quality of the code, as long as you improve the quality later. This process of improving a program's internal structure in small steps without modifying its external behavior is called refactoring.
- Refactoring is not rewriting: Discarding poorly-written code entirely and re-writing it from scratch is not refactoring because refactoring needs to be done in small steps.
- Refactoring is not bug fixing: By definition, refactoring is different from bug fixing or any other modifications that alter the external behavior (e.g. adding a feature) of the component in concern.
💡 Improving code structure can have many secondary benefits: e.g.
- hidden bugs become easier to spot
- improve performance (sometimes, simpler code runs faster than complex code because simpler code is easier for the compiler to optimize).
Given below are two common refactorings (
- Java: http://refactoring.com/catalog/ - This is a list of common refactorings, maintained by Martin Fowler, a leading authority on refactoring. He is also the author of the ‘bestseller’ on refactoring: Refactoring: Improving the Design of Existing Code
- Python: https://refactoring.guru/refactoring/catalog -- A catalog of refactorings applicable to Python code.
Refactoring Name: Consolidate Duplicate Conditional Fragments
Situation: The same fragment of code is in all branches of a conditional expression.
Method: Move it outside of the expression.
Example:
|
→ |
|
|
→ |
|
Refactoring Name: Extract Method
Situation: You have a code fragment that can be grouped together.
Method: Turn the fragment into a method whose name explains the purpose of the method.
Example:
void printOwing() {
printBanner();
//print details
System.out.println("name: " + name);
System.out.println("amount " + getOutstanding());
}
void printOwing() {
printBanner();
printDetails(getOutstanding());
}
void printDetails (double outstanding) {
System.out.println("name: " + name);
System.out.println("amount " + outstanding);
}
def print_owing():
print_banner()
//print details
print("name: " + name)
print("amount " + get_outstanding())
def print_owing():
print_banner()
print_details(get_outstanding())
def print_details(amount):
print("name: " + name)
print("amount " + amount)
💡 Some IDEs have built in support for basic refactorings such as automatically renaming a variable/method/class in all places it has been used.
Refactoring, even if done with the aid of an IDE, may still result in regressions. Therefore, each small refactoring should be followed by regression testing.
Choose the correct statements
- a. Refactoring can improve understandability
- b. Refactoring can uncover bugs
- c. Refactoring can result in better performance
- d. Refactoring can change the number of methods/classes
a, b, c, d
Explanation:
- (a, b, c) Although the primary aim of refactoring is to improve internal code structure, there are other secondary benefits.
- (d) Some refactorings result in adding/removing methods/classes.
Do you agree with the following statement? Justify your answer.
Statement: Whenever we refactor code to fix bugs, we need not do regression testing if the bug fix was minor.
There are two flaws in the given statement.
DISAGREE.
- Even a minor change can have major repercussions on the system. We MUST do regression testing after each change, no matter how minor it is.
- Fixing bugs is technically not refactoring.
Explain what is refactoring and why it is not the same as rewriting, bug fixing, or adding features.
Evidence:
Explain what is refactoring and why it is not the same as rewriting, bug fixing, or adding features.
W3.1b Can use automated refactoring features of the IDE
Tools → Intellij IDEA →
This video explains how to automate the 'Extract parameter' refactoring using Intellij IDEA. Most other refactorings available works similarly. i.e. select the code to refactor → find the refactoring in the context menu or use the keyboard shortcut.
Here's another video explaining how to change a method signature as part of refactoring.
- Introduction to Refactoring (in Intellij IDEA) : An article on refactorings available in Intellij IDEA.
Evidence:
Acceptable: Ability to do some automated refactoring in the IDE.
Submission: Demo during the tutorial.
W3.1c Can apply some basic refactoring
Implementation → Refactoring →
Given below are some more commonly used refactorings. A more comprehensive list is available at
- Java: http://refactoring.com/catalog/ - This is a list of common refactorings, maintained by Martin Fowler, a leading authority on refactoring. He is also the author of the ‘bestseller’ on refactoring: Refactoring: Improving the Design of Existing Code
- Python: https://refactoring.guru/refactoring/catalog -- A catalog of refactorings applicable to Python code.
Evidence:
Acceptable: Some commits that show some refactorings (not necessarily the ones in the list above) you have done.
Suggested: Do some refactoring to the addressbook-level1 code. Remember to commit after each refactoring. The commit message should mention the refactoring you applied. e.g. AddressBook.java: extract foo() method
Submission: Show the relevant commits during the tutorial.
W3.1d Can decide when to apply a given refactoring
Implementation → Refactoring →
We know that it is important to refactor frequently so as to avoid the accumulation of ‘messy’ code which might get out of control. But how much refactoring is too much refactoring? It is too much refactoring when the benefits no longer justify the cost. The costs and the benefits depend on the context. That is why some refactorings are ‘opposites’ of each other (e.g. extract method vs inline method).
‘Extract method’ and ‘Inline method’ refactorings
a
Evidence:
Give an example from any project (e.g. addressbook-level1) where a refactoring can be applied but you decide against it because it is not worth it.
W3.2 Can use intermediate level features of an IDE
W3.2a Can explain debugging
Implementation → IDEs → Debugging →
Debugging is the process of discovering defects in the program. Here are some approaches to debugging:
-
Bad -- By inserting temporary print statements: This is an ad-hoc approach in which print statements are inserted in the program to print information relevant to debugging, such as variable values. e.g.
Exiting process() method, x is 5.347. This approach is not recommended due to these reasons.- Incurs extra effort when inserting and removing the print statements.
- Unnecessary program modifications increases the risk of introducing errors into the program.
- These print statements, if not promptly removed, may even appear unexpectedly in the production version.
-
Bad -- By manually tracing through the code: Otherwise known as ‘eye-balling’, this approach doesn't have the cons of the previous approach, but it too is not recommended (other than as a 'quick try') due to these reasons:
- It is difficult, time consuming, and error-prone technique.
- If you didn't spot the error while writing code, you might not spot the error when reading code too.
-
Good -- Using a debugger: A debugger tool allows you to pause the execution, then step through one statement at a time while examining the internal state if necessary. Most IDEs come with an inbuilt debugger. This is the recommended approach for debugging.
W3.2b Can step through a program using a debugger
Tools → Intellij IDEA →
This video (from LaunchCode) gives a pretty good explanation of how to use the Intellij IDEA debugger.
- Intellij IDEA Documentation: Debugging Basics - Can be used as a reference document when you want to recall how to use a debugging feature.
Evidence:
Submission: Demo debugging features of Intellij during the tutorial.
W3.2c Can use some useful IDE productivity shortcuts
Evidence:
Submission: Demo some Intellij productivity shortcuts during the tutorial.
W3.3 Can follow a simple style guide
W3.3a Can explain the importance of code quality
Implementation → Code Quality → Introduction →
Always code as if the person who ends up maintaining your code will be a violent psychopath who knows where you live. -- Martin Golding
W3.3b Can explain the need for following a standard
Implementation → Code Quality → Style →
One essential way to improve code quality is to follow a consistent style. That is why software engineers follow a strict coding standard (aka style guide).
The aim of a coding standard is to make the entire code base look like it was written by one person. A coding standard is usually specific to a programming language and specifies guidelines such as the location of opening and closing braces, indentation styles and naming styles (e.g. whether to use Hungarian style, Pascal casing, Camel casing, etc.). It is important that the whole team/company use the same coding standard and that standard is not generally inconsistent with typical industry practices. If a company's coding standards is very different from what is used typically in the industry, new recruits will take longer to get used to the company's coding style.
💡 IDEs can help to enforce some parts of a coding standard e.g. indentation rules.
What is the recommended approach regarding coding standards?
c
What is the aim of using a coding standard? How does it help?
Evidence:
What is the aim of using a coding standard? How does it help?
W3.3c Can follow simple mechanical style rules
Implementation → Code Quality → Style →
Learn basic guidelines of the Java coding standard (by OSS-Generic)
Sample coding standard: PEP 8 Python Style Guide -- by Python.org
Consider the code given below:
import java.util.*;
public class Task {
public static final String descriptionPrefix = "description: ";
private String description;
private boolean important;
List<String> pastDescription = new ArrayList<>(); // a list of past descriptions
public Task(String d) {
this.description = d;
if (!d.isEmpty())
this.important = true;
}
public String getAsXML() { return "<task>"+description+"</task>"; }
/**
* Print the description as a string.
*/
public void printingDescription(){ System.out.println(this); }
@Override
public String toString() { return descriptionPrefix + description; }
}
In what ways the code violate the basic guidelines (i.e., those marked with one ⭐️) of the OSS-Generic Java Coding Standard given here?
Here are three:
descriptionPrefixis a constant and should be namedDESCRIPTION_PREFIX- method name
printingDescription()should be named asprintDescription() - boolean variable
importantshould be named to sound boolean e.g.,isImportant
There are many more.
Evidence:
Acceptable: Evidence of following a coding standard in any project.
Suggested: Go through the provided Java coding standard. Identify and fix any violations of basic style rules in local copy of addressbook-level1 code base. Commit after each fix.
Submission: Show the relevant commits during the tutorial.
Suggested question to discuss during tutorial:
Consider the code given below:
import java.util.*;
public class Task {
public static final String descriptionPrefix = "description: ";
private String description;
private boolean important;
List<String> pastDescription = new ArrayList<>(); // a list of past descriptions
public Task(String d) {
this.description = d;
if (!d.isEmpty())
this.important = true;
}
public String getAsXML() { return "<task>"+description+"</task>"; }
/**
* Print the description as a string.
*/
public void printingDescription(){ System.out.println(this); }
@Override
public String toString() { return descriptionPrefix + description; }
}
In what ways the code violate the basic guidelines (i.e., those marked with one ⭐️) of the OSS-Generic Java Coding Standard given here?
Here are three:
descriptionPrefixis a constant and should be namedDESCRIPTION_PREFIX- method name
printingDescription()should be named asprintDescription() - boolean variable
importantshould be named to sound boolean e.g.,isImportant
There are many more.
W3.3d Can follow intermediate style rules
Implementation → Code Quality → Style →
Go through the provided Java coding standard and learn the intermediate style rules.
According to the given Java coding standard, which one of these is not a good name?
b
Explanation: checkWeight is an action. Naming variables as actions makes the code harder to follow. isWeightValid may be a better name.
Repeat the exercise in the panel below but also find violations of intermediate level guidelines.
Consider the code given below:
import java.util.*;
public class Task {
public static final String descriptionPrefix = "description: ";
private String description;
private boolean important;
List<String> pastDescription = new ArrayList<>(); // a list of past descriptions
public Task(String d) {
this.description = d;
if (!d.isEmpty())
this.important = true;
}
public String getAsXML() { return "<task>"+description+"</task>"; }
/**
* Print the description as a string.
*/
public void printingDescription(){ System.out.println(this); }
@Override
public String toString() { return descriptionPrefix + description; }
}
In what ways the code violate the basic guidelines (i.e., those marked with one ⭐️) of the OSS-Generic Java Coding Standard given here?
Here are three:
descriptionPrefixis a constant and should be namedDESCRIPTION_PREFIX- method name
printingDescription()should be named asprintDescription() - boolean variable
importantshould be named to sound boolean e.g.,isImportant
There are many more.
Here's one you are more likely to miss:
* Print the description as a string.→* Prints the description as a string.
There are more.
Evidence:
Similar to the LO
Acceptable: Evidence of following a coding standard in any project.
Suggested: Go through the provided Java coding standard. Identify and fix any violations of basic style rules in local copy of addressbook-level1 code base. Commit after each fix.
Submission: Show the relevant commits during the tutorial.
Suggested question to discuss during tutorial:
Consider the code given below:
import java.util.*;
public class Task {
public static final String descriptionPrefix = "description: ";
private String description;
private boolean important;
List<String> pastDescription = new ArrayList<>(); // a list of past descriptions
public Task(String d) {
this.description = d;
if (!d.isEmpty())
this.important = true;
}
public String getAsXML() { return "<task>"+description+"</task>"; }
/**
* Print the description as a string.
*/
public void printingDescription(){ System.out.println(this); }
@Override
public String toString() { return descriptionPrefix + description; }
}
In what ways the code violate the basic guidelines (i.e., those marked with one ⭐️) of the OSS-Generic Java Coding Standard given here?
Here are three:
descriptionPrefixis a constant and should be namedDESCRIPTION_PREFIX- method name
printingDescription()should be named asprintDescription() - boolean variable
importantshould be named to sound boolean e.g.,isImportant
There are many more.
Revision Control
W3.4 Can communicate with a remote repo
W3.4a Can explain remote repositories
Project Management → Revision Control →
Remote repositories are copies of a repo that are hosted on remote computers. They are especially useful for sharing the revision history of a codebase among team members of a multi-person project. They can also serve as a remote backup of your code base.
You can clone a remote repo onto your computer which will create a copy of a remote repo on your computer, including the version history as the remote repo.
You can push new commits in your clone to the remote repo which will copy the new commits onto the remote repo. Note that pushing to a remote repo requires you to have write-access to it.
You can pull from the remote repos to receive new commits in the remote repo. Pulling is used to sync your local repo with latest changes to the remote repo.
While it is possible to set up your own remote repo on a server, an easier option is to use a remote repo hosting service such as GitHub or BitBucket.
A fork is a remote copy of a remote repo. If there is a remote repo that you want to push to but you do not have write access to it, you can fork the remote repo, which gives you your own remote repo that you can push to.
A pull request is mechanism for contributing code to a remote repo. It is a formal request sent to the maintainers of the repo asking them to pull your new code to their repo.
Here is a scenario that includes all the concepts introduced above (click on the slide to advance the animation):
W3.4b Can clone a remote repo
Tools → Git and GitHub →
Clone the sample repo samplerepo-things to your computer.
Note that the URL of the Github project is different form the URL you need to clone a repo in that Github project. e.g.
Github project URL: https://github.com/se-edu/samplerepo-things
Git repo URL: https://github.com/se-edu/samplerepo-things.git (note the .git at the end)
File → Clone / New… and provide the URL of the repo and the destination directory.
You can use the clone command to clone a repo.
Follow instructions given here.
Evidence:
Acceptable: Any remote repo cloned to your Computer.
Suggested: A clone of the samplerepo-things in your Computer.
Submission: Show the clone to the tutor during the tutorial.
W3.4c Can pull changes from a repo
Tools → Git and GitHub →
Clone the sample repo as explained in
Delete the last two commits to simulate cloning the repo 2 commits ago.
Can clone a remote repo
Clone the sample repo samplerepo-things to your computer.
Note that the URL of the Github project is different form the URL you need to clone a repo in that Github project. e.g.
Github project URL: https://github.com/se-edu/samplerepo-things
Git repo URL: https://github.com/se-edu/samplerepo-things.git (note the .git at the end)
File → Clone / New… and provide the URL of the repo and the destination directory.
You can use the clone command to clone a repo.
Follow instructions given here.
Right-click the target commit (i.e. the commit that is 2 commits behind the tip) and choose Reset current branch to this commit.
Choose the Hard - … option and click OK.
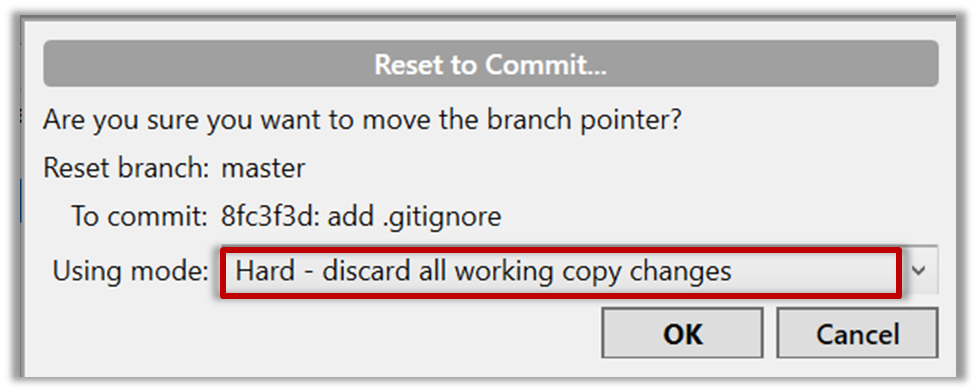
This is what you will see.
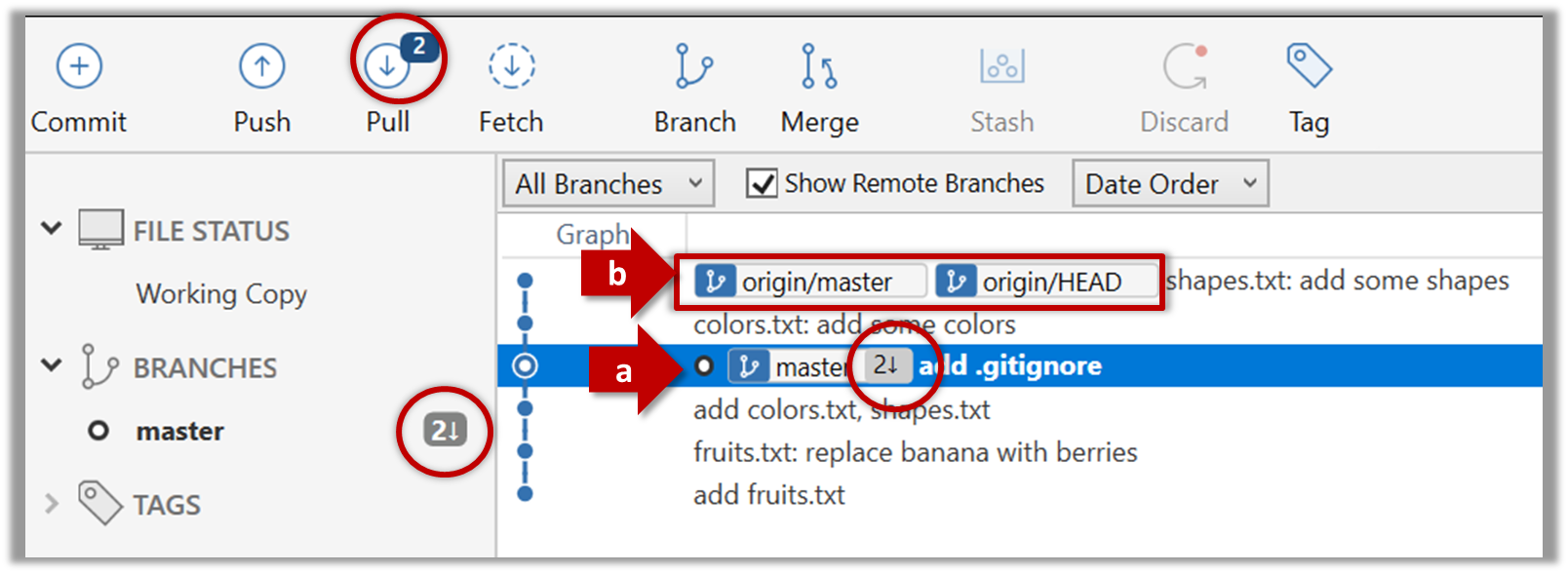
Note the following (cross refer the screenshot above):
Arrow marked as a: The local repo is now at this commit, marked by the master label.
Arrow marked as b: origin/master label shows what is the latest commit in the master branch in the remote repo.
Use the reset command to delete commits at the tip of the revision history.
git reset --hard HEAD~2
Now, your local repo state is exactly how it would be if you had cloned the repo 2 commits ago, as if somebody has added two more commits to the remote repo since you cloned it. To get those commits to your local repo (i.e. to sync your local repo with upstream repo) you can do a pull.
Click the Pull button in the main menu, choose origin and master in the next dialog, and click OK.
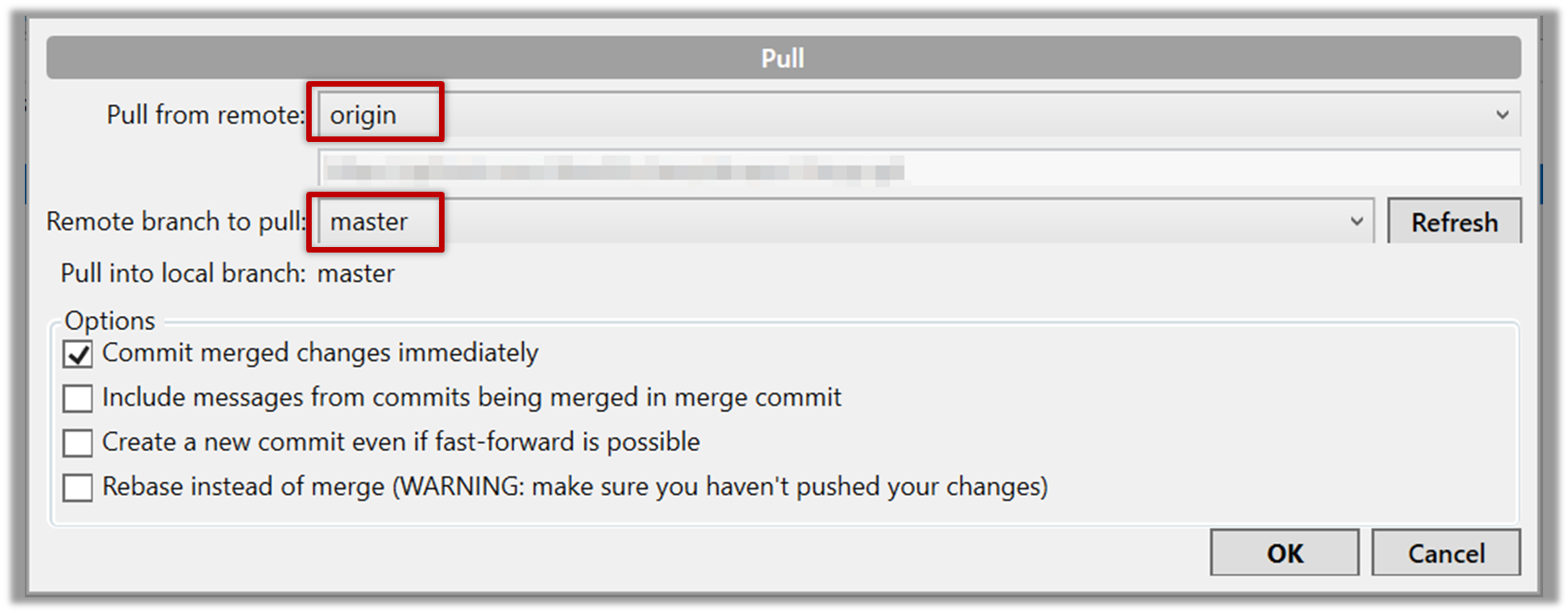
Now you should see something like this where master and origin/master are both pointing the same commit.
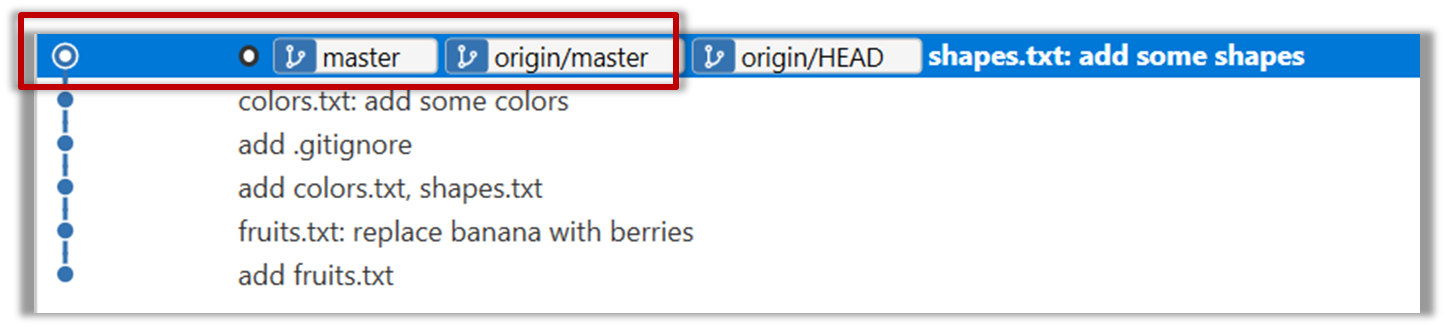
git pull origin
Evidence:
Acceptable: Any evidence of pulling from a remote Git repo.
Suggested: Follow the steps in the LO details.
Submission: Demo a pull operation to the tutor.
W3.4d Can push to a remote repo
Tools → Git and GitHub →
-
Create a GitHub account if you don't have one yet.
-
Fork the samplerepo-things to your GitHub account:
Navigate to the on GitHub and click on the
 button on the top-right corner.
button on the top-right corner. -
Clone the fork (not the original) to your computer.
-
Create some commits in your repo.
-
Push the new commits to your fork on GitHub
Click the Push button on the main menu, ensure the settings are as follows in the next dialog, and click the Push button on the dialog.
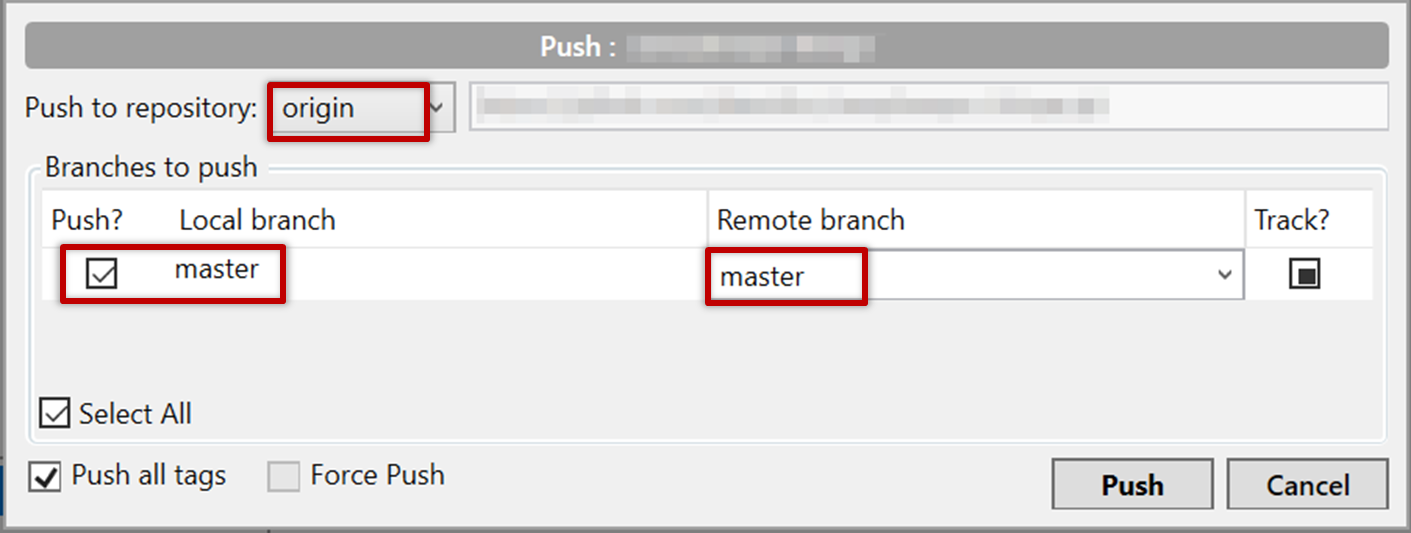
Use the command git push origin master. Enter Github username and password when prompted.
To push an existing local repo into a new remote repo on GitHub, first you need to create an empty remote repo on GitHub.
-
Login to your GitHub account and choose to create a new Repo.
-
In the next screen, provide a name for your repo but keep the
Initialize this repo ...tick box unchecked.
-
Note the URL of the repo. It will be of the form
https://github.com/{your_user_name}/{repo_name}.git
e.g.,https://github.com/johndoe/foobar.git
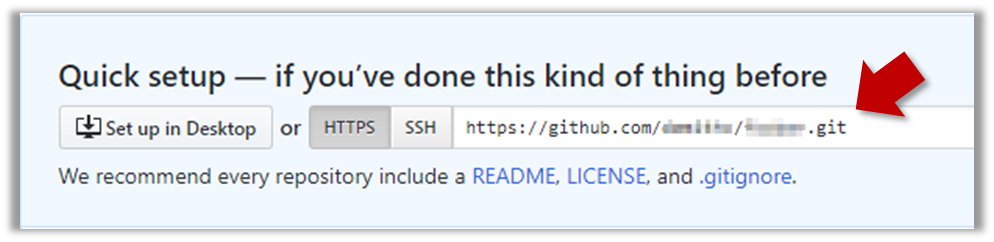
Next, you can push the existing local repo to the new remote repo as follows:
- Open the local repo in SourceTree.
- Choose
Repository→Repository Settingsmenu option. - Add a new remote to the repo with the following values.
Remote name: the name you want to assign to the remote repo. RecommendedoriginURL/path: the URL of your repo (ending in.git) that you collected earlier.Username: your GitHub username
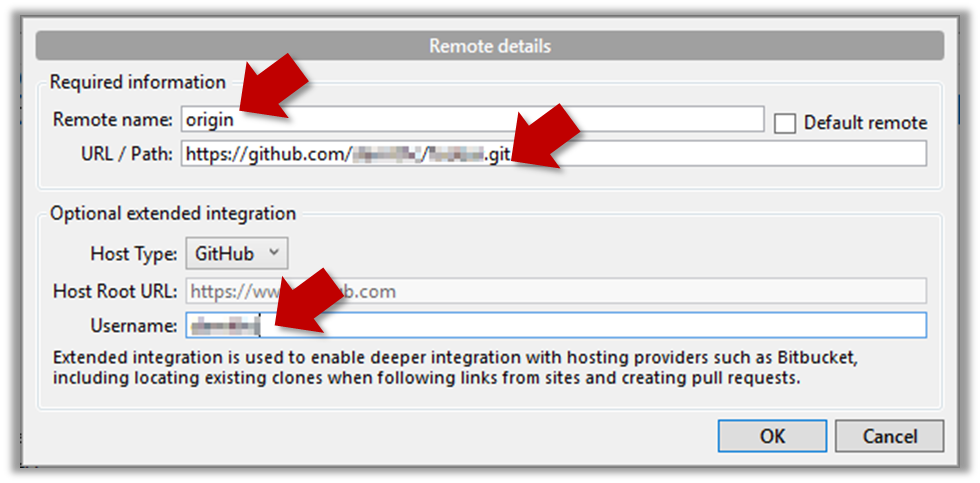
- Now you can push your repo to the new remote the usual way.
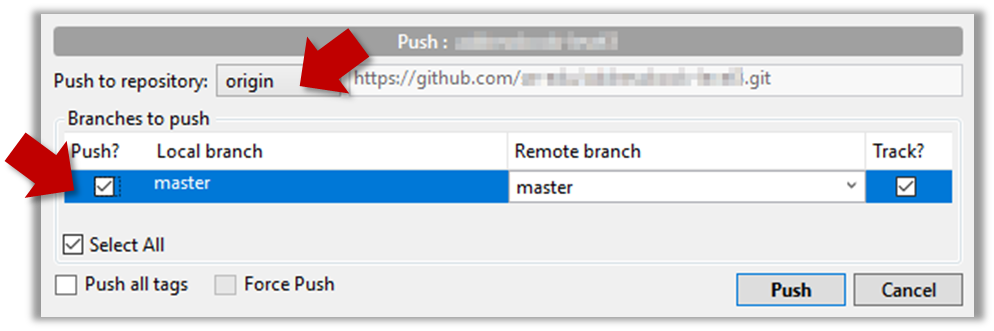
- Navigate to the folder containing the local repo.
- Set the new remote repo as a remote of the local repo.
command:git remote add {remote_name} {remote_repo_url}
e.g.,git remote add origin https://github.com/johndoe/foobar.git - Push to the new remote the usual way. You can use the
-uflag to inform Git that you wish totrack the branch.
e.g.,git push -u origin master
Evidence:
Acceptable: Any evidence of pushing to a remote Git repo.
Suggested: Follow the steps in the LO details.
Submission: Show pushed commits in the remote repo.
W3.5 Can traverse Git history
W3.5a Can explain using history
Project Management → Revision Control →
To see what changed between two points of the history, you can ask the RCS tool to diff the two commits in concern.
To restore the state of the working directory at a point in the past, you can checkout the commit in concern. i.e., we can traverse the history of the working directory simply by checking out the commits we are interested in.
RCS : Revision Control Software are the software tools that automate the process of Revision Control i.e. managing revisions of software artifacts.
W3.5b Can load a specific version of a Git repo
Tools → Git and GitHub →
Git can show you what changed in each commit.
To see which files changed in a commit, click on the commit. To see what changed in a specific file in that commit, click on the file name.
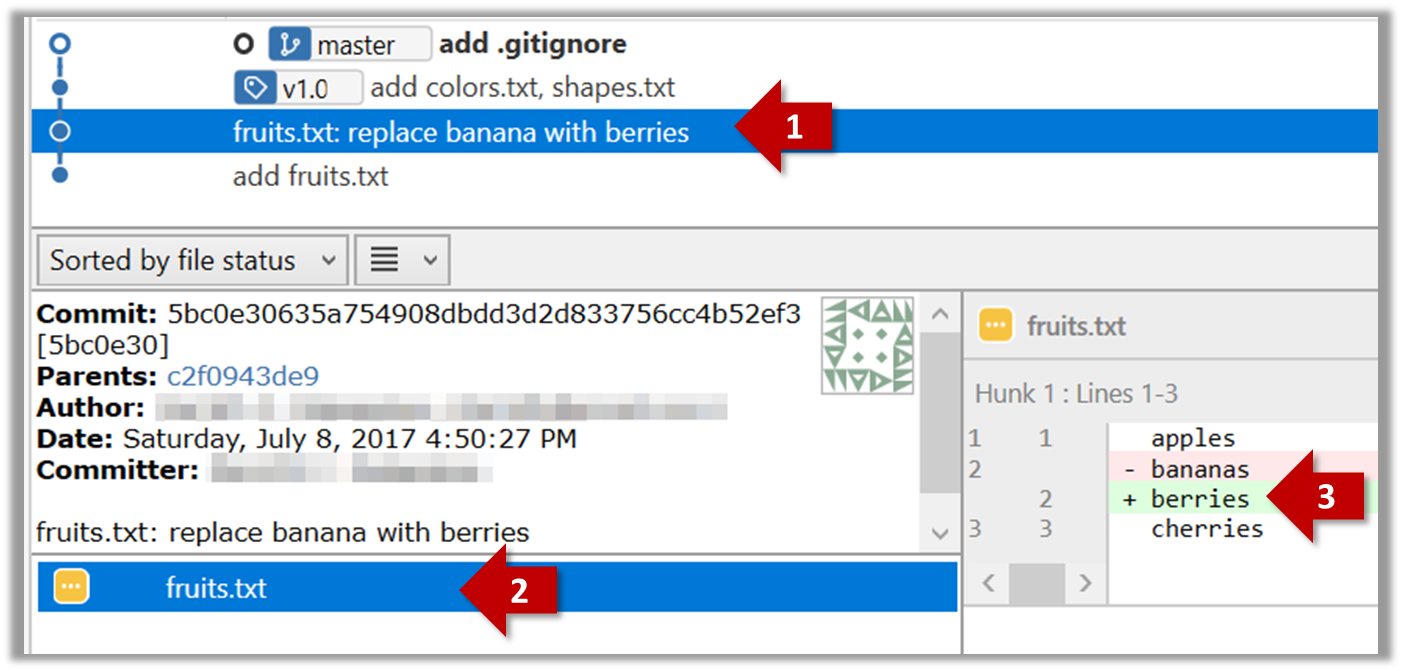
git show < part-of-commit-hash >
Example:
git show 251b4cf
commit 5bc0e30635a754908dbdd3d2d833756cc4b52ef3
Author: … < … >
Date: Sat Jul 8 16:50:27 2017 +0800
fruits.txt: replace banana with berries
diff --git a/fruits.txt b/fruits.txt
index 15b57f7..17f4528 100644
--- a/fruits.txt
+++ b/fruits.txt
@@ -1,3 +1,3 @@
apples
-bananas
+berries
cherries
Git can also show you the difference between two points in the history of the repo.
Select the two points you want to compare using Ctrl+Click.
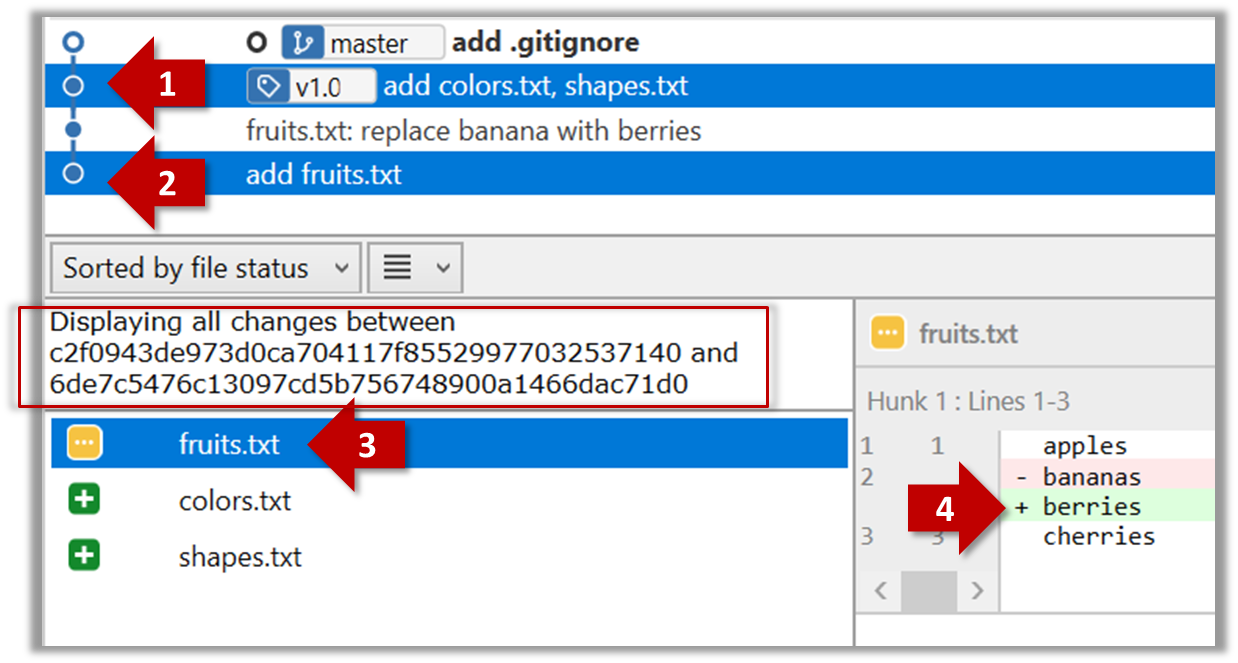
The same method can be used to compare the current state of the working directory (which might have uncommitted changes) to a point in the history.
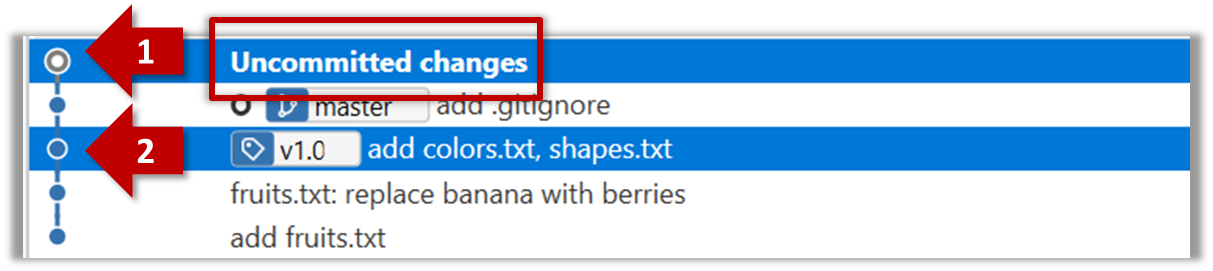
The diff command can be used to view the differences between two points of the history.
git diff: shows the changes (uncommitted) since the last commitgit diff 0023cdd..fcd6199: shows the changes between the points indicated by by commit hashesgit diff v1.0..HEAD: shows changes that happened from the commit tagged asv1.0to the most recent commit.
Git can load a specific version of the history to the working directory. Note that if you have uncommitted changes in the working directory, you need to
Tools → Git and GitHub →
You can use the git's stash feature to temporarily shelve (or stash) changes you've made to your working copy so that you can work on something else, and then come back and re-apply the stashed changes later on. -- adapted from this
Follow this article from SourceTree creators. Note the GUI shown in the article is slightly outdated but you should be able to map it to the current GUI.
Follow this article from Atlassian.
Double-click the commit you want to load to the working directory, or right-click on that commit and choose Checkout....
Click OK to the warning about ‘detached HEAD’ (similar to below).
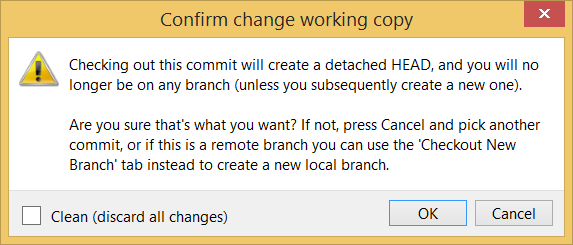
The specified version is now loaded to the working folder, as indicated by the HEAD label. HEAD is a reference to the currently checked out commit.
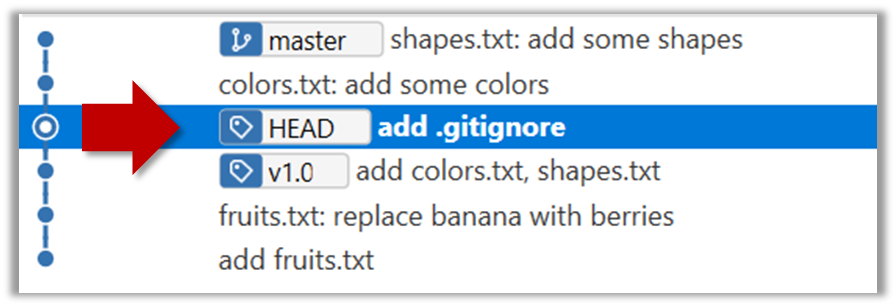
If you checkout a commit that come before the commit in which you added the .gitignore file, Git will now show ignored fiels as ‘unstaged modifications’ because at that stage Git hasn’t been told to ignore those files.
To go back to the latest commit, double-click it.
Use the checkout <commit-identifier> command to change the working directory to the state it was in at a specific past commit.
git checkout v1.0: loads the state as at commit taggedv1.0git checkout 0023cdd: loads the state as at commit with the hash0023cddgit checkout HEAD~2: loads the state that is 2 commits behind the most recent commit
For now, you can ignore the warning about ‘detached HEAD’.
Use the checkout <branch-name> to go back to the most recent commit of the current branch (the default branch in git is named master)
git checkout master
Evidence:
Acceptable: Show how to traverse history using any local repo.
Suggested: Show how to traverse history using the steps given in the LO above.
Submission: Demo during the tutorial.
W3.5c Can tag commits using Git
Tools → Git and GitHub →
Let's tag a commit in a local repo you have (e.g. the sampelrepo-things repo)
Right-click on the commit (in the graphical revision graph) you want to tag and choose Tag…
Specify the tag name e.g. v1.0 and click Add Tag.
The added tag will appear in the revision graph view.
To add a tag to the current commit as v1.0,
git tag –a v1.0
To view tags
git tag
To learn how to add a tag to a past commit, go to the ‘Git Basics – Tagging’ page of the git-scm book and refer the ‘Tagging Later’ section.
Evidence:
Acceptable: Any commit you tagged in any repo.
Suggested: Follow steps in the LO.
Submission: Show the tagged commit to the tutor during the tutorial.
W3.5d Can use Git to stash files
Tools → Git and GitHub →
You can use the git's stash feature to temporarily shelve (or stash) changes you've made to your working copy so that you can work on something else, and then come back and re-apply the stashed changes later on. -- adapted from this
Follow this article from SourceTree creators. Note the GUI shown in the article is slightly outdated but you should be able to map it to the current GUI.
Follow this article from Atlassian.
Evidence:
Submission: Demo stashing.
Documentation
W3.6 Can use some common documentation tools
Javadoc
W3.6a Can explain JavaDoc
Implementation → Documentation → Tools → JavaDoc
Javadoc is a tool for generating API documentation in HTML format from doc comments in source. In addition, modern IDEs use JavaDoc comments to generate explanatory tool tips.
An example method header comment in JavaDoc format (adapted from Oracle's Java documentation)
/**
* Returns an Image object that can then be painted on the screen.
* The url argument must specify an absolute {@link URL}. The name
* argument is a specifier that is relative to the url argument.
* <p>
* This method always returns immediately, whether or not the
* image exists. When this applet attempts to draw the image on
* the screen, the data will be loaded. The graphics primitives
* that draw the image will incrementally paint on the screen.
*
* @param url an absolute URL giving the base location of the image
* @param name the location of the image, relative to the url argument
* @return the image at the specified URL
* @see Image
*/
public Image getImage(URL url, String name) {
try {
return getImage(new URL(url, name));
} catch (MalformedURLException e) {
return null;
}
}
Generated HTML documentation:
Tooltip generated by Intellij IDE:
W3.6b Can write Javadoc comments
Implementation → Documentation → Tools → JavaDoc
In the absence of more extensive guidelines (e.g., given in a coding standard adopted by your project), you can follow the two examples below in your code.
A minimal javadoc comment example for methods:
/**
* Returns lateral location of the specified position.
* If the position is unset, NaN is returned.
*
* @param x X coordinate of position.
* @param y Y coordinate of position.
* @param zone Zone of position.
* @return Lateral location.
* @throws IllegalArgumentException If zone is <= 0.
*/
public double computeLocation(double x, double y, int zone)
throws IllegalArgumentException {
...
}
A minimal javadoc comment example for classes:
package ...
import ...
/**
* Represents a location in a 2D space. A <code>Point</code> object corresponds to
* a coordinate represented by two integers e.g., <code>3,6</code>
*/
public class Point{
//...
}
- A short tutorial on writing JavaDoc comments -- from tutorialspoint.com
- A more detailed description --from Oracle
Markdown
W3.6c Can explain Markdown
W3.6d Can write documents in Markdown format
Implementation → Documentation → Tools → Markdown
- A tutorial on Mastering Markdown --from GitHub
AsciiDoc
W3.6e Can explain AsciiDoc
Implementation → Documentation → Tools → AsciiDoc
AsciiDoc is similar to Markdown but has more powerful (but also more complex) syntax.
🅿️ Project
W3.7 Can define the target of a product
Covered by:
W3.8 Can work with a 1KLoC code base
This LO can earn you
10 marks allocated for participation can be earned in the following ways (there are 30+ available marks to choose from):
-
Good peer ratings - Criteria for professional conduct (1 mark for each criterion, max 7)
- Competency criteria (2 marks for each, max 6)
- Quizzes
- In-lecture quizzes (1 each, max 10 marks)
Post-lecture quizzes (0.5 each, max 5 marks)
- Module admin tasks done on time and as instructed
- Peer evaluations (1 marks each, max 3)
- Pre-module survey (1 marks)
- Enhanced AB1-AB3 (2 mark each, max 6 marks)
Relevant: [
Peer evaluation criteria: professional conduct
- Professional Communication :
- Communicates sufficiently and professionally. e.g. Does not use offensive language or excessive slang in project communications.
- Responds to communication from team members in a timely manner (e.g. within 24 hours).
- Punctuality: Does not cause others to waste time or slow down project progress by frequent tardiness.
- Dependability: Promises what can be done, and delivers what was promised.
- Effort: Puts in sufficient effort to, and tries their best to keep up with the module/project pace. Seeks help from others when necessary.
- Quality: Does not deliver work products that seem to be below the student's competence level i.e. tries their best to make the work product as high quality as possible within her competency level.
- Meticulousness:
- Rarely overlooks submission requirements.
- Rarely misses compulsory module activities such as pre-module survey.
- Teamwork: How willing are you to act as part of a team, contribute to team-level tasks, adhere to team decisions, etc.
Peer evaluation criteria: competency
- Technical Competency: Able to gain competency in all the required tools and techniques.
- Mentoring skills: Helps others when possible. Able to mentor others well.
- Communication skills: Able to communicate (written and spoken) well. Takes initiative in discussions.
Evidence:
Do an enhancement to [AddressBook - Level1] e.g. add a new command
- The size of the enhancement does not matter.
- Step 1: Fork address AddressBook - Level1 to your GitHub account.
- Step 2: Change the code in small steps and commit after each significant change. You may commit to the
masterbranch.- Try to stay within the procedural (not OOP) style of the code base. Reason: in this LO, we try to stretch ourselves to the limits of the procedural approach.
- Update all relevant tests. Ensure all tests pass.
- [Optional] Update all relevant documentation.
- [Optional] Try to follow our coding standard in your new code.
- Step 3: push the updated AB1 code to your fork
💡 Note that you can reuse the code you write here in your final project, if applicable.
Submission: No special submission required. Our scripts will check your fork automatically.
Tutorial 3
CS2103 students only: Form teams at the beginning of the tutorial. Be sure to conform to team forming constrains.
All students:
- Confirm your team ID with the tutor. It should be of the form
TUTORIAL_ID-TEAM_NUMBERe.g.W09-1(Wed0900 slot, team1) - As before, discuss evidence of achieving LOs as directed by the tutor.
W3.1a Can explain refactoring
Implementation → Refactoring →
The first version of the code you write may not be of production quality. It is OK to first concentrate on making the code work, rather than worry over the quality of the code, as long as you improve the quality later. This process of improving a program's internal structure in small steps without modifying its external behavior is called refactoring.
- Refactoring is not rewriting: Discarding poorly-written code entirely and re-writing it from scratch is not refactoring because refactoring needs to be done in small steps.
- Refactoring is not bug fixing: By definition, refactoring is different from bug fixing or any other modifications that alter the external behavior (e.g. adding a feature) of the component in concern.
💡 Improving code structure can have many secondary benefits: e.g.
- hidden bugs become easier to spot
- improve performance (sometimes, simpler code runs faster than complex code because simpler code is easier for the compiler to optimize).
Given below are two common refactorings (
- Java: http://refactoring.com/catalog/ - This is a list of common refactorings, maintained by Martin Fowler, a leading authority on refactoring. He is also the author of the ‘bestseller’ on refactoring: Refactoring: Improving the Design of Existing Code
- Python: https://refactoring.guru/refactoring/catalog -- A catalog of refactorings applicable to Python code.
Refactoring Name: Consolidate Duplicate Conditional Fragments
Situation: The same fragment of code is in all branches of a conditional expression.
Method: Move it outside of the expression.
Example:
|
→ |
|
|
→ |
|
Refactoring Name: Extract Method
Situation: You have a code fragment that can be grouped together.
Method: Turn the fragment into a method whose name explains the purpose of the method.
Example:
void printOwing() {
printBanner();
//print details
System.out.println("name: " + name);
System.out.println("amount " + getOutstanding());
}
void printOwing() {
printBanner();
printDetails(getOutstanding());
}
void printDetails (double outstanding) {
System.out.println("name: " + name);
System.out.println("amount " + outstanding);
}
def print_owing():
print_banner()
//print details
print("name: " + name)
print("amount " + get_outstanding())
def print_owing():
print_banner()
print_details(get_outstanding())
def print_details(amount):
print("name: " + name)
print("amount " + amount)
💡 Some IDEs have built in support for basic refactorings such as automatically renaming a variable/method/class in all places it has been used.
Refactoring, even if done with the aid of an IDE, may still result in regressions. Therefore, each small refactoring should be followed by regression testing.
Choose the correct statements
- a. Refactoring can improve understandability
- b. Refactoring can uncover bugs
- c. Refactoring can result in better performance
- d. Refactoring can change the number of methods/classes
a, b, c, d
Explanation:
- (a, b, c) Although the primary aim of refactoring is to improve internal code structure, there are other secondary benefits.
- (d) Some refactorings result in adding/removing methods/classes.
Do you agree with the following statement? Justify your answer.
Statement: Whenever we refactor code to fix bugs, we need not do regression testing if the bug fix was minor.
There are two flaws in the given statement.
DISAGREE.
- Even a minor change can have major repercussions on the system. We MUST do regression testing after each change, no matter how minor it is.
- Fixing bugs is technically not refactoring.
Explain what is refactoring and why it is not the same as rewriting, bug fixing, or adding features.
Evidence:
Explain what is refactoring and why it is not the same as rewriting, bug fixing, or adding features.
W3.1b Can use automated refactoring features of the IDE
Tools → Intellij IDEA →
This video explains how to automate the 'Extract parameter' refactoring using Intellij IDEA. Most other refactorings available works similarly. i.e. select the code to refactor → find the refactoring in the context menu or use the keyboard shortcut.
Here's another video explaining how to change a method signature as part of refactoring.
- Introduction to Refactoring (in Intellij IDEA) : An article on refactorings available in Intellij IDEA.
Evidence:
Acceptable: Ability to do some automated refactoring in the IDE.
Submission: Demo during the tutorial.
W3.1c Can apply some basic refactoring
Implementation → Refactoring →
Given below are some more commonly used refactorings. A more comprehensive list is available at
- Java: http://refactoring.com/catalog/ - This is a list of common refactorings, maintained by Martin Fowler, a leading authority on refactoring. He is also the author of the ‘bestseller’ on refactoring: Refactoring: Improving the Design of Existing Code
- Python: https://refactoring.guru/refactoring/catalog -- A catalog of refactorings applicable to Python code.
Evidence:
Acceptable: Some commits that show some refactorings (not necessarily the ones in the list above) you have done.
Suggested: Do some refactoring to the addressbook-level1 code. Remember to commit after each refactoring. The commit message should mention the refactoring you applied. e.g. AddressBook.java: extract foo() method
Submission: Show the relevant commits during the tutorial.
W3.1d Can decide when to apply a given refactoring
Implementation → Refactoring →
We know that it is important to refactor frequently so as to avoid the accumulation of ‘messy’ code which might get out of control. But how much refactoring is too much refactoring? It is too much refactoring when the benefits no longer justify the cost. The costs and the benefits depend on the context. That is why some refactorings are ‘opposites’ of each other (e.g. extract method vs inline method).
‘Extract method’ and ‘Inline method’ refactorings
a
Evidence:
Give an example from any project (e.g. addressbook-level1) where a refactoring can be applied but you decide against it because it is not worth it.
W3.2b Can step through a program using a debugger
Tools → Intellij IDEA →
This video (from LaunchCode) gives a pretty good explanation of how to use the Intellij IDEA debugger.
- Intellij IDEA Documentation: Debugging Basics - Can be used as a reference document when you want to recall how to use a debugging feature.
Evidence:
Submission: Demo debugging features of Intellij during the tutorial.
W3.2c Can use some useful IDE productivity shortcuts
W3.3b Can explain the need for following a standard
Implementation → Code Quality → Style →
One essential way to improve code quality is to follow a consistent style. That is why software engineers follow a strict coding standard (aka style guide).
The aim of a coding standard is to make the entire code base look like it was written by one person. A coding standard is usually specific to a programming language and specifies guidelines such as the location of opening and closing braces, indentation styles and naming styles (e.g. whether to use Hungarian style, Pascal casing, Camel casing, etc.). It is important that the whole team/company use the same coding standard and that standard is not generally inconsistent with typical industry practices. If a company's coding standards is very different from what is used typically in the industry, new recruits will take longer to get used to the company's coding style.
💡 IDEs can help to enforce some parts of a coding standard e.g. indentation rules.
What is the recommended approach regarding coding standards?
c
What is the aim of using a coding standard? How does it help?
Evidence:
What is the aim of using a coding standard? How does it help?
W3.3c Can follow simple mechanical style rules
Implementation → Code Quality → Style →
Learn basic guidelines of the Java coding standard (by OSS-Generic)
Sample coding standard: PEP 8 Python Style Guide -- by Python.org
Consider the code given below:
import java.util.*;
public class Task {
public static final String descriptionPrefix = "description: ";
private String description;
private boolean important;
List<String> pastDescription = new ArrayList<>(); // a list of past descriptions
public Task(String d) {
this.description = d;
if (!d.isEmpty())
this.important = true;
}
public String getAsXML() { return "<task>"+description+"</task>"; }
/**
* Print the description as a string.
*/
public void printingDescription(){ System.out.println(this); }
@Override
public String toString() { return descriptionPrefix + description; }
}
In what ways the code violate the basic guidelines (i.e., those marked with one ⭐️) of the OSS-Generic Java Coding Standard given here?
Here are three:
descriptionPrefixis a constant and should be namedDESCRIPTION_PREFIX- method name
printingDescription()should be named asprintDescription() - boolean variable
importantshould be named to sound boolean e.g.,isImportant
There are many more.
Evidence:
Acceptable: Evidence of following a coding standard in any project.
Suggested: Go through the provided Java coding standard. Identify and fix any violations of basic style rules in local copy of addressbook-level1 code base. Commit after each fix.
Submission: Show the relevant commits during the tutorial.
Suggested question to discuss during tutorial:
Consider the code given below:
import java.util.*;
public class Task {
public static final String descriptionPrefix = "description: ";
private String description;
private boolean important;
List<String> pastDescription = new ArrayList<>(); // a list of past descriptions
public Task(String d) {
this.description = d;
if (!d.isEmpty())
this.important = true;
}
public String getAsXML() { return "<task>"+description+"</task>"; }
/**
* Print the description as a string.
*/
public void printingDescription(){ System.out.println(this); }
@Override
public String toString() { return descriptionPrefix + description; }
}
In what ways the code violate the basic guidelines (i.e., those marked with one ⭐️) of the OSS-Generic Java Coding Standard given here?
Here are three:
descriptionPrefixis a constant and should be namedDESCRIPTION_PREFIX- method name
printingDescription()should be named asprintDescription() - boolean variable
importantshould be named to sound boolean e.g.,isImportant
There are many more.
W3.3d Can follow intermediate style rules
Implementation → Code Quality → Style →
Go through the provided Java coding standard and learn the intermediate style rules.
According to the given Java coding standard, which one of these is not a good name?
b
Explanation: checkWeight is an action. Naming variables as actions makes the code harder to follow. isWeightValid may be a better name.
Repeat the exercise in the panel below but also find violations of intermediate level guidelines.
Consider the code given below:
import java.util.*;
public class Task {
public static final String descriptionPrefix = "description: ";
private String description;
private boolean important;
List<String> pastDescription = new ArrayList<>(); // a list of past descriptions
public Task(String d) {
this.description = d;
if (!d.isEmpty())
this.important = true;
}
public String getAsXML() { return "<task>"+description+"</task>"; }
/**
* Print the description as a string.
*/
public void printingDescription(){ System.out.println(this); }
@Override
public String toString() { return descriptionPrefix + description; }
}
In what ways the code violate the basic guidelines (i.e., those marked with one ⭐️) of the OSS-Generic Java Coding Standard given here?
Here are three:
descriptionPrefixis a constant and should be namedDESCRIPTION_PREFIX- method name
printingDescription()should be named asprintDescription() - boolean variable
importantshould be named to sound boolean e.g.,isImportant
There are many more.
Here's one you are more likely to miss:
* Print the description as a string.→* Prints the description as a string.
There are more.
Evidence:
Similar to the LO
Acceptable: Evidence of following a coding standard in any project.
Suggested: Go through the provided Java coding standard. Identify and fix any violations of basic style rules in local copy of addressbook-level1 code base. Commit after each fix.
Submission: Show the relevant commits during the tutorial.
Suggested question to discuss during tutorial:
Consider the code given below:
import java.util.*;
public class Task {
public static final String descriptionPrefix = "description: ";
private String description;
private boolean important;
List<String> pastDescription = new ArrayList<>(); // a list of past descriptions
public Task(String d) {
this.description = d;
if (!d.isEmpty())
this.important = true;
}
public String getAsXML() { return "<task>"+description+"</task>"; }
/**
* Print the description as a string.
*/
public void printingDescription(){ System.out.println(this); }
@Override
public String toString() { return descriptionPrefix + description; }
}
In what ways the code violate the basic guidelines (i.e., those marked with one ⭐️) of the OSS-Generic Java Coding Standard given here?
Here are three:
descriptionPrefixis a constant and should be namedDESCRIPTION_PREFIX- method name
printingDescription()should be named asprintDescription() - boolean variable
importantshould be named to sound boolean e.g.,isImportant
There are many more.
W3.4b Can clone a remote repo
Tools → Git and GitHub →
Clone the sample repo samplerepo-things to your computer.
Note that the URL of the Github project is different form the URL you need to clone a repo in that Github project. e.g.
Github project URL: https://github.com/se-edu/samplerepo-things
Git repo URL: https://github.com/se-edu/samplerepo-things.git (note the .git at the end)
File → Clone / New… and provide the URL of the repo and the destination directory.
You can use the clone command to clone a repo.
Follow instructions given here.
Evidence:
Acceptable: Any remote repo cloned to your Computer.
Suggested: A clone of the samplerepo-things in your Computer.
Submission: Show the clone to the tutor during the tutorial.
W3.4c Can pull changes from a repo
Tools → Git and GitHub →
Clone the sample repo as explained in
Delete the last two commits to simulate cloning the repo 2 commits ago.
Can clone a remote repo
Clone the sample repo samplerepo-things to your computer.
Note that the URL of the Github project is different form the URL you need to clone a repo in that Github project. e.g.
Github project URL: https://github.com/se-edu/samplerepo-things
Git repo URL: https://github.com/se-edu/samplerepo-things.git (note the .git at the end)
File → Clone / New… and provide the URL of the repo and the destination directory.
You can use the clone command to clone a repo.
Follow instructions given here.
Right-click the target commit (i.e. the commit that is 2 commits behind the tip) and choose Reset current branch to this commit.
Choose the Hard - … option and click OK.
This is what you will see.
Note the following (cross refer the screenshot above):
Arrow marked as a: The local repo is now at this commit, marked by the master label.
Arrow marked as b: origin/master label shows what is the latest commit in the master branch in the remote repo.
Use the reset command to delete commits at the tip of the revision history.
git reset --hard HEAD~2
Now, your local repo state is exactly how it would be if you had cloned the repo 2 commits ago, as if somebody has added two more commits to the remote repo since you cloned it. To get those commits to your local repo (i.e. to sync your local repo with upstream repo) you can do a pull.
Click the Pull button in the main menu, choose origin and master in the next dialog, and click OK.
Now you should see something like this where master and origin/master are both pointing the same commit.
git pull origin
Evidence:
Acceptable: Any evidence of pulling from a remote Git repo.
Suggested: Follow the steps in the LO details.
Submission: Demo a pull operation to the tutor.
W3.4d Can push to a remote repo
Tools → Git and GitHub →
-
Create a GitHub account if you don't have one yet.
-
Fork the samplerepo-things to your GitHub account:
Navigate to the on GitHub and click on the
button on the top-right corner. -
Clone the fork (not the original) to your computer.
-
Create some commits in your repo.
-
Push the new commits to your fork on GitHub
Click the Push button on the main menu, ensure the settings are as follows in the next dialog, and click the Push button on the dialog.
Use the command git push origin master. Enter Github username and password when prompted.
To push an existing local repo into a new remote repo on GitHub, first you need to create an empty remote repo on GitHub.
-
Login to your GitHub account and choose to create a new Repo.
-
In the next screen, provide a name for your repo but keep the
Initialize this repo ...tick box unchecked.
-
Note the URL of the repo. It will be of the form
https://github.com/{your_user_name}/{repo_name}.git
e.g.,https://github.com/johndoe/foobar.git
Next, you can push the existing local repo to the new remote repo as follows:
- Open the local repo in SourceTree.
- Choose
Repository→Repository Settingsmenu option. - Add a new remote to the repo with the following values.
Remote name: the name you want to assign to the remote repo. RecommendedoriginURL/path: the URL of your repo (ending in.git) that you collected earlier.Username: your GitHub username
- Now you can push your repo to the new remote the usual way.
- Navigate to the folder containing the local repo.
- Set the new remote repo as a remote of the local repo.
command:git remote add {remote_name} {remote_repo_url}
e.g.,git remote add origin https://github.com/johndoe/foobar.git - Push to the new remote the usual way. You can use the
-uflag to inform Git that you wish totrack the branch.
e.g.,git push -u origin master
Evidence:
Acceptable: Any evidence of pushing to a remote Git repo.
Suggested: Follow the steps in the LO details.
Submission: Show pushed commits in the remote repo.
W3.5b Can load a specific version of a Git repo
Tools → Git and GitHub →
Git can show you what changed in each commit.
To see which files changed in a commit, click on the commit. To see what changed in a specific file in that commit, click on the file name.
git show < part-of-commit-hash >
Example:
git show 251b4cf
commit 5bc0e30635a754908dbdd3d2d833756cc4b52ef3
Author: … < … >
Date: Sat Jul 8 16:50:27 2017 +0800
fruits.txt: replace banana with berries
diff --git a/fruits.txt b/fruits.txt
index 15b57f7..17f4528 100644
--- a/fruits.txt
+++ b/fruits.txt
@@ -1,3 +1,3 @@
apples
-bananas
+berries
cherries
Git can also show you the difference between two points in the history of the repo.
Select the two points you want to compare using Ctrl+Click.
The same method can be used to compare the current state of the working directory (which might have uncommitted changes) to a point in the history.
The diff command can be used to view the differences between two points of the history.
git diff: shows the changes (uncommitted) since the last commitgit diff 0023cdd..fcd6199: shows the changes between the points indicated by by commit hashesgit diff v1.0..HEAD: shows changes that happened from the commit tagged asv1.0to the most recent commit.
Git can load a specific version of the history to the working directory. Note that if you have uncommitted changes in the working directory, you need to
Tools → Git and GitHub →
You can use the git's stash feature to temporarily shelve (or stash) changes you've made to your working copy so that you can work on something else, and then come back and re-apply the stashed changes later on. -- adapted from this
Follow this article from SourceTree creators. Note the GUI shown in the article is slightly outdated but you should be able to map it to the current GUI.
Follow this article from Atlassian.
Double-click the commit you want to load to the working directory, or right-click on that commit and choose Checkout....
Click OK to the warning about ‘detached HEAD’ (similar to below).
The specified version is now loaded to the working folder, as indicated by the HEAD label. HEAD is a reference to the currently checked out commit.
If you checkout a commit that come before the commit in which you added the .gitignore file, Git will now show ignored fiels as ‘unstaged modifications’ because at that stage Git hasn’t been told to ignore those files.
To go back to the latest commit, double-click it.
Use the checkout <commit-identifier> command to change the working directory to the state it was in at a specific past commit.
git checkout v1.0: loads the state as at commit taggedv1.0git checkout 0023cdd: loads the state as at commit with the hash0023cddgit checkout HEAD~2: loads the state that is 2 commits behind the most recent commit
For now, you can ignore the warning about ‘detached HEAD’.
Use the checkout <branch-name> to go back to the most recent commit of the current branch (the default branch in git is named master)
git checkout master
Evidence:
Acceptable: Show how to traverse history using any local repo.
Suggested: Show how to traverse history using the steps given in the LO above.
Submission: Demo during the tutorial.
W3.5c Can tag commits using Git
Tools → Git and GitHub →
Let's tag a commit in a local repo you have (e.g. the sampelrepo-things repo)
Right-click on the commit (in the graphical revision graph) you want to tag and choose Tag…
Specify the tag name e.g. v1.0 and click Add Tag.
The added tag will appear in the revision graph view.
To add a tag to the current commit as v1.0,
git tag –a v1.0
To view tags
git tag
To learn how to add a tag to a past commit, go to the ‘Git Basics – Tagging’ page of the git-scm book and refer the ‘Tagging Later’ section.
Evidence:
Acceptable: Any commit you tagged in any repo.
Suggested: Follow steps in the LO.
Submission: Show the tagged commit to the tutor during the tutorial.
W3.5d Can use Git to stash files
Tools → Git and GitHub →
You can use the git's stash feature to temporarily shelve (or stash) changes you've made to your working copy so that you can work on something else, and then come back and re-apply the stashed changes later on. -- adapted from this
Follow this article from SourceTree creators. Note the GUI shown in the article is slightly outdated but you should be able to map it to the current GUI.
Follow this article from Atlassian.
Evidence:
Submission: Demo stashing.
W3.7 Can define the target of a product
Covered by:
W3.8 Can work with a 1KLoC code base
This LO can earn you
10 marks allocated for participation can be earned in the following ways (there are 30+ available marks to choose from):
-
Good peer ratings - Criteria for professional conduct (1 mark for each criterion, max 7)
- Competency criteria (2 marks for each, max 6)
- Quizzes
- In-lecture quizzes (1 each, max 10 marks)
Post-lecture quizzes (0.5 each, max 5 marks)
- Module admin tasks done on time and as instructed
- Peer evaluations (1 marks each, max 3)
- Pre-module survey (1 marks)
- Enhanced AB1-AB3 (2 mark each, max 6 marks)
Relevant: [
Peer evaluation criteria: professional conduct
- Professional Communication :
- Communicates sufficiently and professionally. e.g. Does not use offensive language or excessive slang in project communications.
- Responds to communication from team members in a timely manner (e.g. within 24 hours).
- Punctuality: Does not cause others to waste time or slow down project progress by frequent tardiness.
- Dependability: Promises what can be done, and delivers what was promised.
- Effort: Puts in sufficient effort to, and tries their best to keep up with the module/project pace. Seeks help from others when necessary.
- Quality: Does not deliver work products that seem to be below the student's competence level i.e. tries their best to make the work product as high quality as possible within her competency level.
- Meticulousness:
- Rarely overlooks submission requirements.
- Rarely misses compulsory module activities such as pre-module survey.
- Teamwork: How willing are you to act as part of a team, contribute to team-level tasks, adhere to team decisions, etc.
Peer evaluation criteria: competency
- Technical Competency: Able to gain competency in all the required tools and techniques.
- Mentoring skills: Helps others when possible. Able to mentor others well.
- Communication skills: Able to communicate (written and spoken) well. Takes initiative in discussions.
Evidence:
Do an enhancement to [AddressBook - Level1] e.g. add a new command
- The size of the enhancement does not matter.
- Step 1: Fork address AddressBook - Level1 to your GitHub account.
- Step 2: Change the code in small steps and commit after each significant change. You may commit to the
masterbranch.- Try to stay within the procedural (not OOP) style of the code base. Reason: in this LO, we try to stretch ourselves to the limits of the procedural approach.
- Update all relevant tests. Ensure all tests pass.
- [Optional] Update all relevant documentation.
- [Optional] Try to follow our coding standard in your new code.
- Step 3: push the updated AB1 code to your fork
💡 Note that you can reuse the code you write here in your final project, if applicable.
Submission: No special submission required. Our scripts will check your fork automatically.