Week 7 [Oct 1]
Todo
Admin info to read:
Update UG and DG in the repo, attempt to do global-impact changes to the code base.
Milestone progress is graded. Be reminded that reaching individual and team milestones are considered for
Most aspects project progress are tracked using automated scripts. lease follow our instructions closely or else the script will not be able to detect your progress. We prefer not to spend admin resources processing requests for partial credit for work that did not follow the instructions precisely, unless the progress was not detected due to a bug in the script.
Milestone requirements are cumulative. The recommended progress for the mid-milestone is an implicit requirement for the actual milestone unless a milestone requirement overrides a mid-milestone requirement e.g., mid-milestone requires a document to be in a temp format while the actual milestone requires it to be in the proper format. Similarly, a requirement for milestone n is also an implicit requirement for milestone n+1 unless n+1 overrides the n requirement. This means if you miss some requirement at milestone n, you should try to achieve it before milestone n+1 or else it could be noted again as a 'missed requirement' at milestone n+1.
v1.1 Summary of Milestone
| Milestone | Minimum acceptable performance to consider as 'reached' |
|---|---|
| Team org/repo set up | as stated in |
| Some code enhancements done | created PRs to do local/global changes |
| Photo uploaded | a photo complying to |
| Project docs updated | updated docs are merged to the master branch |
| Milestone wrapped up | a commit in the master branch tagged as v1.1 |
Set up project repo, start moving UG and DG to the repo, attempt to do local-impact changes to the code base.
Project Management:
Set up the team org and the team repo as explained below:
Relevant: [
Organization setup
Please follow the organization/repo name format precisely because we use scripts to download your code or else our scripts will not be able to detect your work.
After receiving your team ID, one team member should do the following steps:
- Create a GitHub organization with the following details:
- Organization name :
CS2103-AY1819S1-TEAM_ID. e.g.CS2103-AY1819S1-W12-1 - Plan: Open Source ($0/month)
- Organization name :
- Add members to the organization:
- Create a team called
developersto your organization. - Add your team members to the developers team.
- Create a team called
Relevant: [
Repo setup
Only one team member:
- Fork Address Book Level 4 to your team org.
- Rename the forked repo as
main. This repo (let's call it the team repo) is to be used as the repo for your project. - Ensure the issue tracker of your team repo is enabled. Reason: our bots will be posting your weekly progress reports on the issue tracker of your team repo.
- Ensure your team members have the desired level of access to your team repo.
- Enable Travis CI for the team repo.
- Set up auto-publishing of docs. When set up correctly, your project website should be available via the URL
https://nus-cs2103-ay1819s1-{team-id}.github.io/maine.g.,https://cs2103-ay1819s1-w13-1.github.io/main/. This also requires you to enable the GitHub Pages feature of your team repo and configure it to serve the website from thegh-pagesbranch. - create a team PR for us to track your project progress: i.e., create a PR from your team repo
masterbranch to [nus-cs2103-AY1819S1/addressbook-level4]masterbranch. PR name:[Team ID] Product Namee.g.,[T09-2] Contact List Pro. As you merge code to your team repo'smasterbranch, this PR will auto-update to reflect how much your team's product has progressed. In the PR description@mention the other team members so that they get notified when the tutor adds comments to the PR.
All team members:
- Watchthe
mainrepo (created above) i.e., go to the repo and click on thewatchbutton to subscribe to activities of the repo - Fork the
mainrepo to your personal GitHub account. - Clone the fork to your Computer.
- Recommended: Set it up as an Intellij project (follow the instructions in the Developer Guide carefully).
- Set up the developer environment in your computer. You are recommended to use JDK 9 for AB-4 as some of the libraries used in AB-4 have not updated to support Java 10 yet. JDK 9 can be downloaded from the Java Archive.
Note that some of our download scripts depend on the following folder paths. Please do not alter those paths in your project.
/src/main/src/test/docs
When updating code in the repo, follow the workflow explained below:
Relevant: [
Workflow
Before you do any coding for the project,
- Ensure you have
set the Git username correctly (as explained in Appendix E) in all Computers you use for coding. - Read
our reuse policy (in Admin: Appendix B) , in particular, how to give credit when you reuse code from the Internet or classmates:
Setting Git Username to Match GitHub Username
We use various tools to analyze your code. For us to be able to identify your commits, you should use the GitHub username as your Git username as well. If there is a mismatch, or if you use multiple user names for Git, our tools might miss some of your work and as a result you might not get credit for some of your work.
In each Computer you use for coding, after installing Git, you should set the Git username as follows.
- Open a command window that can run Git commands (e.g., Git bash window)
- Run the command
git config --global user.name YOUR_GITHUB_USERNAME
e.g.,git config --global user.name JohnDoe
More info about setting Git username is here.
Policy on reuse
Reuse is encouraged. However, note that reuse has its own costs (such as the learning curve, additional complexity, usage restrictions, and unknown bugs). Furthermore, you will not be given credit for work done by others. Rather, you will be given credit for using work done by others.
- You are allowed to reuse work from your classmates, subject to following conditions:
- The work has been published by us or the authors.
- You clearly give credit to the original author(s).
- You are allowed to reuse work from external sources, subject to following conditions:
- The work comes from a source of 'good standing' (such as an established open source project). This means you cannot reuse code written by an outside 'friend'.
- You clearly give credit to the original author. Acknowledge use of third party resources clearly e.g. in the welcome message, splash screen (if any) or under the 'about' menu. If you are open about reuse, you are less likely to get into trouble if you unintentionally reused something copyrighted.
- You do not violate the license under which the work has been released. Please do not use 3rd-party images/audio in your software unless they have been specifically released to be used freely. Just because you found it in the Internet does not mean it is free for reuse.
- Always get permission from us before you reuse third-party libraries. Please post your 'request to use 3rd party library' in our forum. That way, the whole class get to see what libraries are being used by others.
Giving credit for reused work
Given below are how to give credit for things you reuse from elsewhere. These requirements are specific to this module i.e., not applicable outside the module (outside the module you should follow the rules specified by your employer and the license of the reused work)
If you used a third party library:
- Mention in the
README.adoc(under the Acknowledgements section) - mention in the
Project Portfolio Page if the library has a significant relevance to the features you implemented
If you reused code snippets found on the Internet e.g. from StackOverflow answers or
referred code in another software or
referred project code by current/past student:
- If you read the code to understand the approach and implemented it yourself, mention it as a comment
Example://Solution below adapted from https://stackoverflow.com/a/16252290 {Your implmentation of the reused solution here ...} - If you copy-pasted a non-trivial code block (possibly with minor modifications renaming, layout changes, changes to comments, etc.), also mark the code block as reused code (using
@@authortags
Format://@@author {yourGithubUsername}-reused //{Info about the source...} {Reused code (possibly with minor modifications) here ...} //@@authorpersons = getList() //@@author johndoe-reused //Reused from https://stackoverflow.com/a/34646172 with minor modifications Collections.sort(persons, new Comparator<CustomData>() { @Override public int compare(CustomData lhs, CustomData rhs) { return lhs.customInt > rhs.customInt ? -1 : (lhs.customInt < rhs.customInt) ? 1 : 0; } }); //@@author return persons;
Adding @@author tags indicate authorship
-
Mark your code with a
//@@author {yourGithubUsername}. Note the double@.
The//@@authortag should indicates the beginning of the code you wrote. The code up to the next//@@authortag or the end of the file (whichever comes first) will be considered as was written by that author. Here is a sample code file://@@author johndoe method 1 ... method 2 ... //@@author sarahkhoo method 3 ... //@@author johndoe method 4 ... -
If you don't know who wrote the code segment below yours, you may put an empty
//@@author(i.e. no GitHub username) to indicate the end of the code segment you wrote. The author of code below yours can add the GitHub username to the empty tag later. Here is a sample code with an emptyauthortag:method 0 ... //@@author johndoe method 1 ... method 2 ... //@@author method 3 ... method 4 ... -
The author tag syntax varies based on file type e.g. for java, css, fxml. Use the corresponding comment syntax for non-Java files.
Here is an example code from an xml/fxml file.<!-- @@author sereneWong --> <textbox> <label>...</label> <input>...</input> </textbox> ... -
Do not put the
//@@authorinside java header comments.
👎/** * Returns true if ... * @@author johndoe */👍
//@@author johndoe /** * Returns true if ... */
What to and what not to annotate
-
Annotate both functional and test code There is no need to annotate documentation files.
-
Annotate only significant size code blocks that can be reviewed on its own e.g., a class, a sequence of methods, a method.
Claiming credit for code blocks smaller than a method is discouraged but allowed. If you do, do it sparingly and only claim meaningful blocks of code such as a block of statements, a loop, or an if-else statement.- If an enhancement required you to do tiny changes in many places, there is no need to annotate all those tiny changes; you can describe those changes in the Project Portfolio page instead.
- If a code block was touched by more than one person, either let the person who wrote most of it (e.g. more than 80%) take credit for the entire block, or leave it as 'unclaimed' (i.e., no author tags).
- Related to the above point, if you claim a code block as your own, more than 80% of the code in that block should have been written by yourself. For example, no more than 20% of it can be code you reused from somewhere.
- 💡 GitHub has a blame feature and a history feature that can help you determine who wrote a piece of code.
-
Do not try to boost the quantity of your contribution using unethical means such as duplicating the same code in multiple places. In particular, do not copy-paste test cases to create redundant tests. Even repetitive code blocks within test methods should be extracted out as utility methods to reduce code duplication. Individual members are responsible for making sure code attributed to them are correct. If you notice a team member claiming credit for code that he/she did not write or use other questionable tactics, you can email us (after the final submission) to let us know.
-
If you wrote a significant amount of code that was not used in the final product,
- Create a folder called
{project root}/unused - Move unused files (or copies of files containing unused code) to that folder
- use
//@@author {yourGithubUsername}-unusedto mark unused code in those files (note the suffixunused) e.g.
//@@author johndoe-unused method 1 ... method 2 ...Please put a comment in the code to explain why it was not used.
- Create a folder called
-
If you reused code from elsewhere, mark such code as
//@@author {yourGithubUsername}-reused(note the suffixreused) e.g.//@@author johndoe-reused method 1 ... method 2 ... -
You can use empty
@@authortags to mark code as not yours when RepoSense attribute the to you incorrectly.-
Code generated by the IDE/framework, should not be annotated as your own.
-
Code you modified in minor ways e.g. adding a parameter. These should not be claimed as yours but you can mention these additional contributions in the Project Portfolio page if you want to claim credit for them.
-
At the end of the project each student is required to submit a Project Portfolio Page.
-
Objective:
- For you to use (e.g. in your resume) as a well-documented data point of your SE experience
- For us to use as a data point to evaluate your,
- contributions to the project
- your documentation skills
-
Sections to include:
-
Overview: A short overview of your product to provide some context to the reader.
-
Summary of Contributions:
- Code contributed: Give a link to your code on Project Code Dashboard, which should be
https://nus-cs2103-ay1819s1.github.io/cs2103-dashboard/#=undefined&search=githbub_username_in_lower_case(replacegithbub_username_in_lower_casewith your actual username in lower case e.g.,johndoe). This link is also available in the Project List Page -- linked to the icon under your photo. - Main feature implemented: A summary of the main feature (the so called major enhancement) you implemented
- Other contributions:
- Other minor enhancements you did which are not related to your main feature
- Contributions to project management e.g., setting up project tools, managing releases, managing issue tracker etc.
- Evidence of helping others e.g. responses you posted in our forum, bugs you reported in other team's products,
- Evidence of technical leadership e.g. sharing useful information in the forum
- Code contributed: Give a link to your code on Project Code Dashboard, which should be
-
Contributions to the User Guide: Reproduce the parts in the User Guide that you wrote. This can include features you implemented as well as features you propose to implement.
The purpose of allowing you to include proposed features is to provide you more flexibility to show your documentation skills. e.g. you can bring in a proposed feature just to give you an opportunity to use a UML diagram type not used by the actual features. -
Contributions to the Developer Guide: Reproduce the parts in the Developer Guide that you wrote. Ensure there is enough content to evaluate your technical documentation skills and UML modelling skills. You can include descriptions of your design/implementations, possible alternatives, pros and cons of alternatives, etc.
-
If you plan to use the PPP in your Resume, you can also include your SE work outside of the module (will not be graded)
-
-
Format:
-
File name:
docs/team/githbub_username_in_lower_case.adoce.g.,docs/team/johndoe.adoc -
Follow the example in the AddressBook-Level4, but ignore the following two lines in it.
- Minor enhancement: added a history command that allows the user to navigate to previous commands using up/down keys.
- Code contributed: [Functional code] [Test code] {give links to collated code files}
-
💡 You can use the Asciidoc's
includefeature to include sections from the developer guide or the user guide in your PPP. Follow the example in the sample. -
It is assumed that all contents in the PPP were written primarily by you. If any section is written by someone else e.g. someone else wrote described the feature in the User Guide but you implemented the feature, clearly state that the section was written by someone else (e.g.
Start of Extract [from: User Guide] written by Jane Doe). Reason: Your writing skills will be evaluated based on the PPP -
Page limit: If you have more content than the limit given below, shorten (or omit some content) so that you do not exceed the page limit. Having too much content in the PPP will be viewed unfavorably during grading. Note: the page limits given below are after converting to PDF format. The actual amount of content you require is actually less than what these numbers suggest because the HTML → PDF conversion adds a lot of spacing around content.
Content Limit Overview + Summary of contributions 0.5-1 Contributions to the User Guide 1-3 Contributions to the Developer Guide 3-6 Total 5-10
-
Follow the
- Get team members to review PRs. A workflow without PR reviews is a risky workflow.
- Do not merge PRs failing
CI . After setting up Travis, the CI status of a PR is reported at the bottom of the PR page. The screenshot below shows the status of a PR that is passing all CI checks.
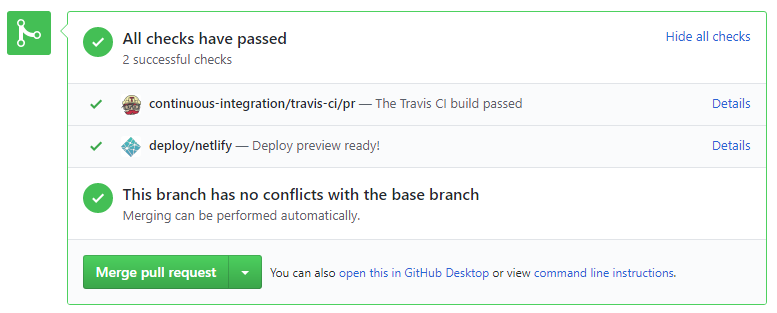
If there is a failure, you can click on theDetailslink in corresponding line to find out more about the failure. Once you figure out the cause of the failure, push the a fix to the PR. - After setting up Netlify, you can use Netlify PR Preview to preview changes to documentation files, if the PR contains updates to documentation. To see the preview, click on the
Detailslink in front of the Netlify status reported (refer screenshot above).
After completing v1.1, you can adjust process rigor to suit your team's pace, as explained below.
-
Reduce automated tests have benefits, but they can be a pain to write/maintain; GUI tests are especially hard to maintain because their behavior can sometimes depend on things such as the OS, resolution etc.
It is OK to get rid of some of the troublesome tests and rely more on manual testing instead. The less automated tests you have, the higher the risk of regressions; but it may be an acceptable trade-off under the circumstances if tests are slowing you down too much.
There is no direct penalty for removing GUI tests. Also noteour expectation on test code . -
Reduce automated checks: You can also reduce the rigor of checkstyle checks to expedite PR processing.
-
Switch to a lighter workflow: While forking workflow is the safest, it is also rather heavy. You an switch to a simpler workflow if the forking workflow is slowing you down. Refer the textbook to find more about alternative workflows: branching workflow, centralized workflow. However, we still recommend that you use PR reviews, at least for PRs affecting others' features.
You can also increase the rigor/safety of your workflow in the following ways:
- Use GitHub's Protected Branches feature to protect your
masterbranch against rogue PRs.
- There is no requirement for a minimum coverage level. Note that in a production environment you are often required to have at least 90% of the code covered by tests. In this project, it can be less. The less coverage you have, the higher the risk of regression bugs, which will cost marks if not fixed before the final submission.
- You must write some tests so that we can evaluate your ability to write tests.
- How much of each type of testing should you do? We expect you to decide. You learned different types of testing and what they try to achieve. Based on that, you should decide how much of each type is required. Similarly, you can decide to what extent you want to automate tests, depending on the benefits and the effort required.
- Applying
TDD is optional. If you plan to test something, it is better to apply TDD because TDD ensures that you write functional code in a testable way. If you do it the normal way, you often find that it is hard to test the functional code because the code has low testability.
Project Management → Revision Control →
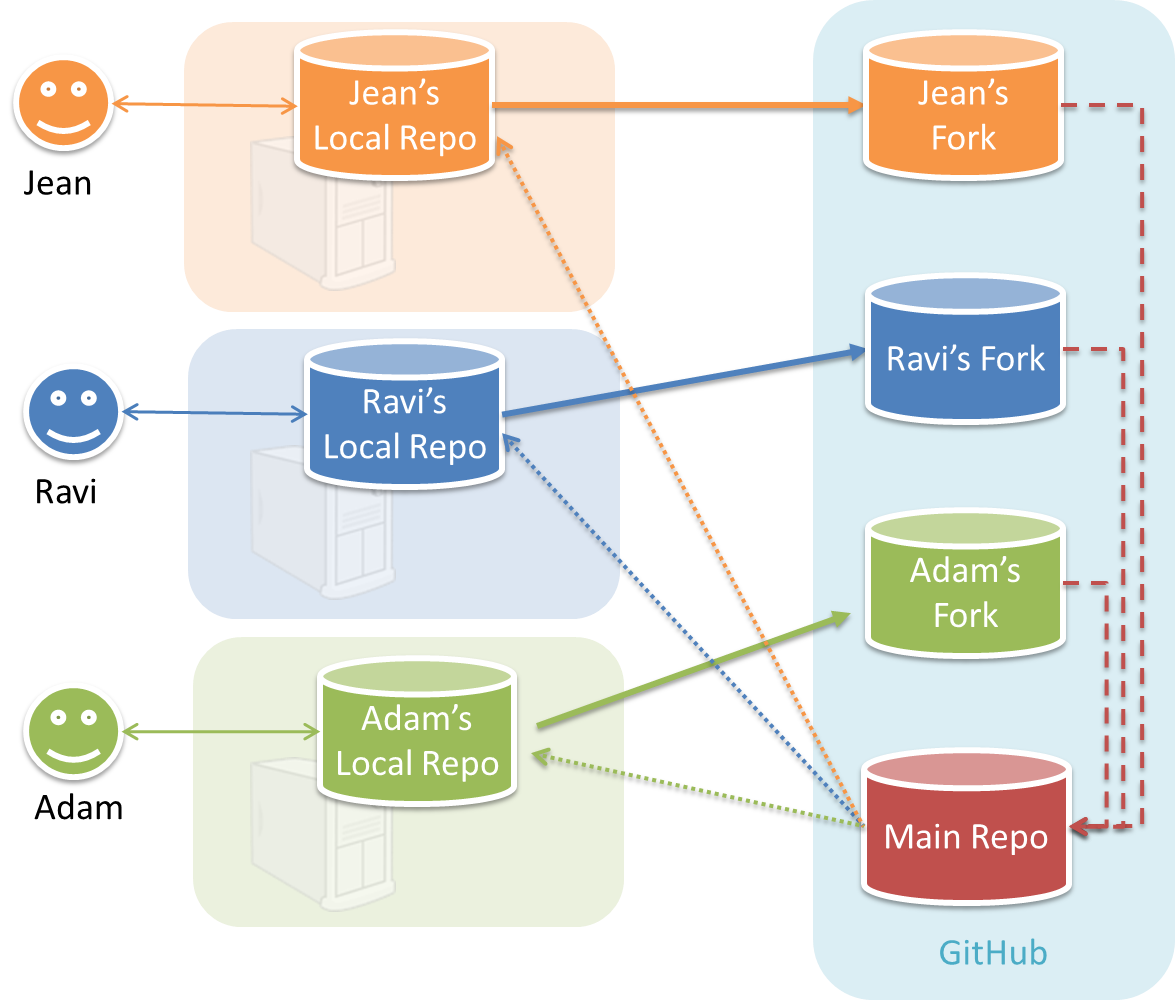
In the forking workflow, the 'official' version of the software is kept in a remote repo designated as the 'main repo'. All team members fork the main repo create pull requests from their fork to the main repo.
To illustrate how the workflow goes, let’s assume Jean wants to fix a bug in the code. Here are the steps:
- Jean creates a separate branch in her local repo and fixes the bug in that branch.
- Jean pushes the branch to her fork.
- Jean creates a pull request from that branch in her fork to the main repo.
- Other members review Jean’s pull request.
- If reviewers suggested any changes, Jean updates the PR accordingly.
- When reviewers are satisfied with the PR, one of the members (usually the team lead or a designated 'maintainer' of the main repo) merges the PR, which brings Jean’s code to the main repo.
- Other members, realizing there is new code in the upstream repo, sync their forks with the new upstream repo (i.e. the main repo). This is done by pulling the new code to their own local repo and pushing the updated code to their own fork.
- A detailed explanation of the Forking Workflow - From Atlassian
Documentation:
Recommended procedure for updating docs:
- Divide among yourselves who will update which parts of the document(s).
- Update the team repo by following the workflow mentioned above.
Update the following pages in your project repo:
- About Us page:
This page is used for module admin purposes. Please follow the format closely or else our scripts will not be able to give credit for your work.
- Replace info of SE-EDU developers with info of your team, including a suitable photo as described
here . - Including the name/photo of the supervisor/lecturer is optional.
- The photo of a team member should be
doc/images/githbub_username_in_lower_case.pnge.g.docs/images/damithc.png. If you photo is in jpg format, name the file as.pnganyway. - Indicate the different roles played and responsibilities held by each team member. You can reassign these
roles and responsibilities (as explained in Admin Project Scope) later in the project, if necessary.
- Replace info of SE-EDU developers with info of your team, including a suitable photo as described
-
The purpose of the profile photo is for the teaching team to identify you. Therefore, you should choose a recent individual photo showing your face clearly (i.e., not too small) -- somewhat similar to a passport photo. Some examples can be seen in the 'Teaching team' page. Given below are some examples of good and bad profile photos.

-
If you are uncomfortable posting your photo due to security reasons, you can post a lower resolution image so that it is hard for someone to misuse that image for fraudulent purposes. If you are concerned about privacy, you can request permission to omit your photo from the page by writing to prof.
Roles indicate aspects you are in charge of and responsible for. E.g., if you are in charge of documentation, you are the person who should allocate which parts of the documentation is to be done by who, ensure the document is in right format, ensure consistency etc.
This is a non-exhaustive list; you may define additional roles.
- Team lead: Responsible for overall project coordination.
- Documentation (short for ‘in charge of documentation’): Responsible for the quality of various project documents.
- Testing: Ensures the testing of the project is done properly and on time.
- Code quality: Looks after code quality, ensures adherence to coding standards, etc.
- Deliverables and deadlines: Ensure project deliverables are done on time and in the right format.
- Integration: In charge of versioning of the code, maintaining the code repository, integrating various parts of the software to create a whole.
- Scheduling and tracking: In charge of defining, assigning, and tracking project tasks.
- [Tool ABC] expert: e.g. Intellij expert, Git expert, etc. Helps other team member with matters related to the specific tool.
- In charge of[Component XYZ]: e.g. In charge of
Model,UI,Storage, etc. If you are in charge of a component, you are expected to know that component well, and review changes done to that component in v1.3-v1.4.
Please make sure each of the important roles are assigned to one person in the team. It is OK to have a 'backup' for each role, but for each aspect there should be one person who is unequivocally the person responsible for it.
-
Contact Us Page: Update to match your product.
-
README.adoc page: Update it to match your project.
-
Add a UI mockup of your intended final product.
Note that the image of the UI should bedocs/images/Ui.pngso that it can be downloaded by our scripts. Limit the file to contain one screenshot/mockup only and ensure the new image is roughly the sameheight x widthproportions as the original one. Reason: when we compile these images from all teams into one page (example), yours should not look out of place. -
The original
README.adocfile (which doubles as the landing page of your project website) is written to read like the introduction to an SE learning/teaching resource. You should restructure this page to look like the home page of a real product (not a school project) targeting real users e.g. remove references to addressbook-level3, Learning Outcomes etc. mention target users, add a marketing blurb etc. On a related note, also removeLearning Outcomeslink and related pages. -
Update the link of the Travis build status badge (
 ) so that it reflects the build status of your team repo.
) so that it reflects the build status of your team repo.
For the other badges,- either set up the respective tool for your project (AB-4 Developer Guide has instructions on how to set up AppVeyor and Coveralls) and update the badges accordingly,
- or remove the badge.
-
Acknowledge the original source of the code i.e. AddressBook-Level4 project created by SE-EDU initiative at
https://github.com/se-edu/
-
-
User Guide: Start moving the content from your User Guide (draft created in previous weeks) into the User Guide page in your repository. If a feature is not implemented, mark it as 'Coming in v2.0' (example).
-
Developer Guide: Similar to the User Guide, start moving the content from your Developer Guide (draft created in previous weeks) into the Developer Guide page in your team repository.
Product:
-
Each member can attempt to do a
local-impact change to the code base.Objective: To familiarize yourself with at least one
components of the product.Description: Divide the components among yourselves. Each member can do some small enhancements to their component(s) to learn the code of that component. Some suggested enhancements are given in the AddressBook-Level4 developer guide.
Submission: Create PRs from your own fork to your team repo. Get it merged by following your team's workflow.
A. Process:
Evaluates: How well you did in project management related aspects of the project, as an individual and as a team
Based on: Supervisor observations of project milestones and GitHub data.
Milestones need to be reached the midnight before of the tutorial for it to be counted as achieved. To get a good grade for this aspect, achieve at least 60% of the recommended milestone progress.
Other criteria:
- Good use of GitHub milestones
- Good use of GitHub release mechanism
- Good version control, based on the repo
- Reasonable attempt to use the forking workflow
- Good task definition, assignment and tracking, based on the issue tracker
- Good use of buffers (opposite: everything at the last minute)
- Project done iteratively and incrementally (opposite: doing most of the work in one big burst)
B. Team-based tasks:
Evaluates: how much you contributed to common team-based tasks
Based on: peer evaluations and tutor observations
Relevant: [
Here is a non-exhaustive list of team-tasks:
- Necessary general code enhancements e.g.,
- Work related to renaming the product
- Work related to changing the product icon
- Morphing the product into a different product
- Setting up the GitHub, Travis, AppVeyor, etc.
- Maintaining the issue tracker
- Release management
- Updating user/developer docs that are not specific to a feature e.g. documenting the target user profile
- Incorporating more useful tools/libraries/frameworks into the product or the project workflow (e.g. automate more aspects of the project workflow using a GitHub plugin)
-
The purpose of the profile photo is for the teaching team to identify you. Therefore, you should choose a recent individual photo showing your face clearly (i.e., not too small) -- somewhat similar to a passport photo. Some examples can be seen in the 'Teaching team' page. Given below are some examples of good and bad profile photos.
-
If you are uncomfortable posting your photo due to security reasons, you can post a lower resolution image so that it is hard for someone to misuse that image for fraudulent purposes. If you are concerned about privacy, you can request permission to omit your photo from the page by writing to prof.
v1.1 Project Management
- Fix any errors in org/repo set up (e.g. wrong repo name).
- Wrap up the milestone using a git tag
v1.1as explained below:- When the milestone deadline is near (e.g., 0.5 days before the deadline), if you think some of the ongoing work intended for the current milestone may not finish in time, reassign them to a future milestone.
- After all changes that can be merged before the milestone deadline has been merged, use
git tagfeature to tag the current version with the milestone and push the tag to the team repo.
v1.1 Documentation
-
Update User Guide, Developer Guide, README, and About Us pages as described earlier in
mid-v1.1 progress guide .Submission: merge your changes to the master branch of your repo.
Set up project repo, start moving UG and DG to the repo, attempt to do local-impact changes to the code base.
Project Management:
Set up the team org and the team repo as explained below:
Relevant: [
Organization setup
Please follow the organization/repo name format precisely because we use scripts to download your code or else our scripts will not be able to detect your work.
After receiving your team ID, one team member should do the following steps:
- Create a GitHub organization with the following details:
- Organization name :
CS2103-AY1819S1-TEAM_ID. e.g.CS2103-AY1819S1-W12-1 - Plan: Open Source ($0/month)
- Organization name :
- Add members to the organization:
- Create a team called
developersto your organization. - Add your team members to the developers team.
- Create a team called
Relevant: [
Repo setup
Only one team member:
- Fork Address Book Level 4 to your team org.
- Rename the forked repo as
main. This repo (let's call it the team repo) is to be used as the repo for your project. - Ensure the issue tracker of your team repo is enabled. Reason: our bots will be posting your weekly progress reports on the issue tracker of your team repo.
- Ensure your team members have the desired level of access to your team repo.
- Enable Travis CI for the team repo.
- Set up auto-publishing of docs. When set up correctly, your project website should be available via the URL
https://nus-cs2103-ay1819s1-{team-id}.github.io/maine.g.,https://cs2103-ay1819s1-w13-1.github.io/main/. This also requires you to enable the GitHub Pages feature of your team repo and configure it to serve the website from thegh-pagesbranch. - create a team PR for us to track your project progress: i.e., create a PR from your team repo
masterbranch to [nus-cs2103-AY1819S1/addressbook-level4]masterbranch. PR name:[Team ID] Product Namee.g.,[T09-2] Contact List Pro. As you merge code to your team repo'smasterbranch, this PR will auto-update to reflect how much your team's product has progressed. In the PR description@mention the other team members so that they get notified when the tutor adds comments to the PR.
All team members:
- Watchthe
mainrepo (created above) i.e., go to the repo and click on thewatchbutton to subscribe to activities of the repo - Fork the
mainrepo to your personal GitHub account. - Clone the fork to your Computer.
- Recommended: Set it up as an Intellij project (follow the instructions in the Developer Guide carefully).
- Set up the developer environment in your computer. You are recommended to use JDK 9 for AB-4 as some of the libraries used in AB-4 have not updated to support Java 10 yet. JDK 9 can be downloaded from the Java Archive.
Note that some of our download scripts depend on the following folder paths. Please do not alter those paths in your project.
/src/main/src/test/docs
When updating code in the repo, follow the workflow explained below:
Relevant: [
Workflow
Before you do any coding for the project,
- Ensure you have
set the Git username correctly (as explained in Appendix E) in all Computers you use for coding. - Read
our reuse policy (in Admin: Appendix B) , in particular, how to give credit when you reuse code from the Internet or classmates:
Setting Git Username to Match GitHub Username
We use various tools to analyze your code. For us to be able to identify your commits, you should use the GitHub username as your Git username as well. If there is a mismatch, or if you use multiple user names for Git, our tools might miss some of your work and as a result you might not get credit for some of your work.
In each Computer you use for coding, after installing Git, you should set the Git username as follows.
- Open a command window that can run Git commands (e.g., Git bash window)
- Run the command
git config --global user.name YOUR_GITHUB_USERNAME
e.g.,git config --global user.name JohnDoe
More info about setting Git username is here.
Policy on reuse
Reuse is encouraged. However, note that reuse has its own costs (such as the learning curve, additional complexity, usage restrictions, and unknown bugs). Furthermore, you will not be given credit for work done by others. Rather, you will be given credit for using work done by others.
- You are allowed to reuse work from your classmates, subject to following conditions:
- The work has been published by us or the authors.
- You clearly give credit to the original author(s).
- You are allowed to reuse work from external sources, subject to following conditions:
- The work comes from a source of 'good standing' (such as an established open source project). This means you cannot reuse code written by an outside 'friend'.
- You clearly give credit to the original author. Acknowledge use of third party resources clearly e.g. in the welcome message, splash screen (if any) or under the 'about' menu. If you are open about reuse, you are less likely to get into trouble if you unintentionally reused something copyrighted.
- You do not violate the license under which the work has been released. Please do not use 3rd-party images/audio in your software unless they have been specifically released to be used freely. Just because you found it in the Internet does not mean it is free for reuse.
- Always get permission from us before you reuse third-party libraries. Please post your 'request to use 3rd party library' in our forum. That way, the whole class get to see what libraries are being used by others.
Giving credit for reused work
Given below are how to give credit for things you reuse from elsewhere. These requirements are specific to this module i.e., not applicable outside the module (outside the module you should follow the rules specified by your employer and the license of the reused work)
If you used a third party library:
- Mention in the
README.adoc(under the Acknowledgements section) - mention in the
Project Portfolio Page if the library has a significant relevance to the features you implemented
If you reused code snippets found on the Internet e.g. from StackOverflow answers or
referred code in another software or
referred project code by current/past student:
- If you read the code to understand the approach and implemented it yourself, mention it as a comment
Example://Solution below adapted from https://stackoverflow.com/a/16252290 {Your implmentation of the reused solution here ...} - If you copy-pasted a non-trivial code block (possibly with minor modifications renaming, layout changes, changes to comments, etc.), also mark the code block as reused code (using
@@authortags
Format://@@author {yourGithubUsername}-reused //{Info about the source...} {Reused code (possibly with minor modifications) here ...} //@@authorpersons = getList() //@@author johndoe-reused //Reused from https://stackoverflow.com/a/34646172 with minor modifications Collections.sort(persons, new Comparator<CustomData>() { @Override public int compare(CustomData lhs, CustomData rhs) { return lhs.customInt > rhs.customInt ? -1 : (lhs.customInt < rhs.customInt) ? 1 : 0; } }); //@@author return persons;
Adding @@author tags indicate authorship
-
Mark your code with a
//@@author {yourGithubUsername}. Note the double@.
The//@@authortag should indicates the beginning of the code you wrote. The code up to the next//@@authortag or the end of the file (whichever comes first) will be considered as was written by that author. Here is a sample code file://@@author johndoe method 1 ... method 2 ... //@@author sarahkhoo method 3 ... //@@author johndoe method 4 ... -
If you don't know who wrote the code segment below yours, you may put an empty
//@@author(i.e. no GitHub username) to indicate the end of the code segment you wrote. The author of code below yours can add the GitHub username to the empty tag later. Here is a sample code with an emptyauthortag:method 0 ... //@@author johndoe method 1 ... method 2 ... //@@author method 3 ... method 4 ... -
The author tag syntax varies based on file type e.g. for java, css, fxml. Use the corresponding comment syntax for non-Java files.
Here is an example code from an xml/fxml file.<!-- @@author sereneWong --> <textbox> <label>...</label> <input>...</input> </textbox> ... -
Do not put the
//@@authorinside java header comments.
👎/** * Returns true if ... * @@author johndoe */👍
//@@author johndoe /** * Returns true if ... */
What to and what not to annotate
-
Annotate both functional and test code There is no need to annotate documentation files.
-
Annotate only significant size code blocks that can be reviewed on its own e.g., a class, a sequence of methods, a method.
Claiming credit for code blocks smaller than a method is discouraged but allowed. If you do, do it sparingly and only claim meaningful blocks of code such as a block of statements, a loop, or an if-else statement.- If an enhancement required you to do tiny changes in many places, there is no need to annotate all those tiny changes; you can describe those changes in the Project Portfolio page instead.
- If a code block was touched by more than one person, either let the person who wrote most of it (e.g. more than 80%) take credit for the entire block, or leave it as 'unclaimed' (i.e., no author tags).
- Related to the above point, if you claim a code block as your own, more than 80% of the code in that block should have been written by yourself. For example, no more than 20% of it can be code you reused from somewhere.
- 💡 GitHub has a blame feature and a history feature that can help you determine who wrote a piece of code.
-
Do not try to boost the quantity of your contribution using unethical means such as duplicating the same code in multiple places. In particular, do not copy-paste test cases to create redundant tests. Even repetitive code blocks within test methods should be extracted out as utility methods to reduce code duplication. Individual members are responsible for making sure code attributed to them are correct. If you notice a team member claiming credit for code that he/she did not write or use other questionable tactics, you can email us (after the final submission) to let us know.
-
If you wrote a significant amount of code that was not used in the final product,
- Create a folder called
{project root}/unused - Move unused files (or copies of files containing unused code) to that folder
- use
//@@author {yourGithubUsername}-unusedto mark unused code in those files (note the suffixunused) e.g.
//@@author johndoe-unused method 1 ... method 2 ...Please put a comment in the code to explain why it was not used.
- Create a folder called
-
If you reused code from elsewhere, mark such code as
//@@author {yourGithubUsername}-reused(note the suffixreused) e.g.//@@author johndoe-reused method 1 ... method 2 ... -
You can use empty
@@authortags to mark code as not yours when RepoSense attribute the to you incorrectly.-
Code generated by the IDE/framework, should not be annotated as your own.
-
Code you modified in minor ways e.g. adding a parameter. These should not be claimed as yours but you can mention these additional contributions in the Project Portfolio page if you want to claim credit for them.
-
At the end of the project each student is required to submit a Project Portfolio Page.
-
Objective:
- For you to use (e.g. in your resume) as a well-documented data point of your SE experience
- For us to use as a data point to evaluate your,
- contributions to the project
- your documentation skills
-
Sections to include:
-
Overview: A short overview of your product to provide some context to the reader.
-
Summary of Contributions:
- Code contributed: Give a link to your code on Project Code Dashboard, which should be
https://nus-cs2103-ay1819s1.github.io/cs2103-dashboard/#=undefined&search=githbub_username_in_lower_case(replacegithbub_username_in_lower_casewith your actual username in lower case e.g.,johndoe). This link is also available in the Project List Page -- linked to the icon under your photo. - Main feature implemented: A summary of the main feature (the so called major enhancement) you implemented
- Other contributions:
- Other minor enhancements you did which are not related to your main feature
- Contributions to project management e.g., setting up project tools, managing releases, managing issue tracker etc.
- Evidence of helping others e.g. responses you posted in our forum, bugs you reported in other team's products,
- Evidence of technical leadership e.g. sharing useful information in the forum
- Code contributed: Give a link to your code on Project Code Dashboard, which should be
-
Contributions to the User Guide: Reproduce the parts in the User Guide that you wrote. This can include features you implemented as well as features you propose to implement.
The purpose of allowing you to include proposed features is to provide you more flexibility to show your documentation skills. e.g. you can bring in a proposed feature just to give you an opportunity to use a UML diagram type not used by the actual features. -
Contributions to the Developer Guide: Reproduce the parts in the Developer Guide that you wrote. Ensure there is enough content to evaluate your technical documentation skills and UML modelling skills. You can include descriptions of your design/implementations, possible alternatives, pros and cons of alternatives, etc.
-
If you plan to use the PPP in your Resume, you can also include your SE work outside of the module (will not be graded)
-
-
Format:
-
File name:
docs/team/githbub_username_in_lower_case.adoce.g.,docs/team/johndoe.adoc -
Follow the example in the AddressBook-Level4, but ignore the following two lines in it.
- Minor enhancement: added a history command that allows the user to navigate to previous commands using up/down keys.
- Code contributed: [Functional code] [Test code] {give links to collated code files}
-
💡 You can use the Asciidoc's
includefeature to include sections from the developer guide or the user guide in your PPP. Follow the example in the sample. -
It is assumed that all contents in the PPP were written primarily by you. If any section is written by someone else e.g. someone else wrote described the feature in the User Guide but you implemented the feature, clearly state that the section was written by someone else (e.g.
Start of Extract [from: User Guide] written by Jane Doe). Reason: Your writing skills will be evaluated based on the PPP -
Page limit: If you have more content than the limit given below, shorten (or omit some content) so that you do not exceed the page limit. Having too much content in the PPP will be viewed unfavorably during grading. Note: the page limits given below are after converting to PDF format. The actual amount of content you require is actually less than what these numbers suggest because the HTML → PDF conversion adds a lot of spacing around content.
Content Limit Overview + Summary of contributions 0.5-1 Contributions to the User Guide 1-3 Contributions to the Developer Guide 3-6 Total 5-10
-
Follow the
- Get team members to review PRs. A workflow without PR reviews is a risky workflow.
- Do not merge PRs failing
CI . After setting up Travis, the CI status of a PR is reported at the bottom of the PR page. The screenshot below shows the status of a PR that is passing all CI checks.
If there is a failure, you can click on theDetailslink in corresponding line to find out more about the failure. Once you figure out the cause of the failure, push the a fix to the PR. - After setting up Netlify, you can use Netlify PR Preview to preview changes to documentation files, if the PR contains updates to documentation. To see the preview, click on the
Detailslink in front of the Netlify status reported (refer screenshot above).
After completing v1.1, you can adjust process rigor to suit your team's pace, as explained below.
-
Reduce automated tests have benefits, but they can be a pain to write/maintain; GUI tests are especially hard to maintain because their behavior can sometimes depend on things such as the OS, resolution etc.
It is OK to get rid of some of the troublesome tests and rely more on manual testing instead. The less automated tests you have, the higher the risk of regressions; but it may be an acceptable trade-off under the circumstances if tests are slowing you down too much.
There is no direct penalty for removing GUI tests. Also noteour expectation on test code . -
Reduce automated checks: You can also reduce the rigor of checkstyle checks to expedite PR processing.
-
Switch to a lighter workflow: While forking workflow is the safest, it is also rather heavy. You an switch to a simpler workflow if the forking workflow is slowing you down. Refer the textbook to find more about alternative workflows: branching workflow, centralized workflow. However, we still recommend that you use PR reviews, at least for PRs affecting others' features.
You can also increase the rigor/safety of your workflow in the following ways:
- Use GitHub's Protected Branches feature to protect your
masterbranch against rogue PRs.
- There is no requirement for a minimum coverage level. Note that in a production environment you are often required to have at least 90% of the code covered by tests. In this project, it can be less. The less coverage you have, the higher the risk of regression bugs, which will cost marks if not fixed before the final submission.
- You must write some tests so that we can evaluate your ability to write tests.
- How much of each type of testing should you do? We expect you to decide. You learned different types of testing and what they try to achieve. Based on that, you should decide how much of each type is required. Similarly, you can decide to what extent you want to automate tests, depending on the benefits and the effort required.
- Applying
TDD is optional. If you plan to test something, it is better to apply TDD because TDD ensures that you write functional code in a testable way. If you do it the normal way, you often find that it is hard to test the functional code because the code has low testability.
Project Management → Revision Control →
In the forking workflow, the 'official' version of the software is kept in a remote repo designated as the 'main repo'. All team members fork the main repo create pull requests from their fork to the main repo.
To illustrate how the workflow goes, let’s assume Jean wants to fix a bug in the code. Here are the steps:
- Jean creates a separate branch in her local repo and fixes the bug in that branch.
- Jean pushes the branch to her fork.
- Jean creates a pull request from that branch in her fork to the main repo.
- Other members review Jean’s pull request.
- If reviewers suggested any changes, Jean updates the PR accordingly.
- When reviewers are satisfied with the PR, one of the members (usually the team lead or a designated 'maintainer' of the main repo) merges the PR, which brings Jean’s code to the main repo.
- Other members, realizing there is new code in the upstream repo, sync their forks with the new upstream repo (i.e. the main repo). This is done by pulling the new code to their own local repo and pushing the updated code to their own fork.
- A detailed explanation of the Forking Workflow - From Atlassian
Documentation:
Recommended procedure for updating docs:
- Divide among yourselves who will update which parts of the document(s).
- Update the team repo by following the workflow mentioned above.
Update the following pages in your project repo:
- About Us page:
This page is used for module admin purposes. Please follow the format closely or else our scripts will not be able to give credit for your work.
- Replace info of SE-EDU developers with info of your team, including a suitable photo as described
here . - Including the name/photo of the supervisor/lecturer is optional.
- The photo of a team member should be
doc/images/githbub_username_in_lower_case.pnge.g.docs/images/damithc.png. If you photo is in jpg format, name the file as.pnganyway. - Indicate the different roles played and responsibilities held by each team member. You can reassign these
roles and responsibilities (as explained in Admin Project Scope) later in the project, if necessary.
- Replace info of SE-EDU developers with info of your team, including a suitable photo as described
-
The purpose of the profile photo is for the teaching team to identify you. Therefore, you should choose a recent individual photo showing your face clearly (i.e., not too small) -- somewhat similar to a passport photo. Some examples can be seen in the 'Teaching team' page. Given below are some examples of good and bad profile photos.
-
If you are uncomfortable posting your photo due to security reasons, you can post a lower resolution image so that it is hard for someone to misuse that image for fraudulent purposes. If you are concerned about privacy, you can request permission to omit your photo from the page by writing to prof.
Roles indicate aspects you are in charge of and responsible for. E.g., if you are in charge of documentation, you are the person who should allocate which parts of the documentation is to be done by who, ensure the document is in right format, ensure consistency etc.
This is a non-exhaustive list; you may define additional roles.
- Team lead: Responsible for overall project coordination.
- Documentation (short for ‘in charge of documentation’): Responsible for the quality of various project documents.
- Testing: Ensures the testing of the project is done properly and on time.
- Code quality: Looks after code quality, ensures adherence to coding standards, etc.
- Deliverables and deadlines: Ensure project deliverables are done on time and in the right format.
- Integration: In charge of versioning of the code, maintaining the code repository, integrating various parts of the software to create a whole.
- Scheduling and tracking: In charge of defining, assigning, and tracking project tasks.
- [Tool ABC] expert: e.g. Intellij expert, Git expert, etc. Helps other team member with matters related to the specific tool.
- In charge of[Component XYZ]: e.g. In charge of
Model,UI,Storage, etc. If you are in charge of a component, you are expected to know that component well, and review changes done to that component in v1.3-v1.4.
Please make sure each of the important roles are assigned to one person in the team. It is OK to have a 'backup' for each role, but for each aspect there should be one person who is unequivocally the person responsible for it.
-
Contact Us Page: Update to match your product.
-
README.adoc page: Update it to match your project.
-
Add a UI mockup of your intended final product.
Note that the image of the UI should bedocs/images/Ui.pngso that it can be downloaded by our scripts. Limit the file to contain one screenshot/mockup only and ensure the new image is roughly the sameheight x widthproportions as the original one. Reason: when we compile these images from all teams into one page (example), yours should not look out of place. -
The original
README.adocfile (which doubles as the landing page of your project website) is written to read like the introduction to an SE learning/teaching resource. You should restructure this page to look like the home page of a real product (not a school project) targeting real users e.g. remove references to addressbook-level3, Learning Outcomes etc. mention target users, add a marketing blurb etc. On a related note, also removeLearning Outcomeslink and related pages. -
Update the link of the Travis build status badge (
) so that it reflects the build status of your team repo.
For the other badges,- either set up the respective tool for your project (AB-4 Developer Guide has instructions on how to set up AppVeyor and Coveralls) and update the badges accordingly,
- or remove the badge.
-
Acknowledge the original source of the code i.e. AddressBook-Level4 project created by SE-EDU initiative at
https://github.com/se-edu/
-
-
User Guide: Start moving the content from your User Guide (draft created in previous weeks) into the User Guide page in your repository. If a feature is not implemented, mark it as 'Coming in v2.0' (example).
-
Developer Guide: Similar to the User Guide, start moving the content from your Developer Guide (draft created in previous weeks) into the Developer Guide page in your team repository.
Product:
-
Each member can attempt to do a
local-impact change to the code base.Objective: To familiarize yourself with at least one
components of the product.Description: Divide the components among yourselves. Each member can do some small enhancements to their component(s) to learn the code of that component. Some suggested enhancements are given in the AddressBook-Level4 developer guide.
Submission: Create PRs from your own fork to your team repo. Get it merged by following your team's workflow.
v1.1 Product
- Each member should try to add some enhancements that are in line with the vision for v2.0. After adding some local-impact changes as recommended in
mid-v1.1 progress guide , attempt to do someglobal-impact enhancements , touching as many other components as possible. Refer to the AddressBook-Level4 Developer Guide has some guidance on how to implement a new feature end-to-end.
If your team is facing difficulties due to differences in skill/motivation /availability among team members,
-
First, do not expect everyone to have the same skill/motivation level as you. It is fine if someone wants to do less and have low expectations from the module. That doesn't mean that person is a bad person. Everyone is entitled to have their own priorities.
-
Second, don't give up. It is unfortunate that your team ended up in this situation, but you can turn it into a good learning opportunity. You don't get an opportunity to save a sinking team every day 😃
-
Third, if you care about your grade and willing to work for it, you need to take initiative to turn the situation around or else the whole team is going to suffer. Don't hesitate to take charge if the situation calls for it. By doing so, you'll be doing a favor for your team. Be professional, kind, and courteous to the team members, but also be firm and assertive. It is your grade that is at stake. Don't worry about making a bad situation worse. You won't know until you try.
-
Finally, don't feel angry or 'wronged'. Teamwork problems are not uncommon in this module and we know how to grade so that you will not be penalized for others' low contribution. We can use Git to find exactly what others did. It's not your responsibility to get others to contribute.
Given below are some suggestions you can adopt if the project work is not going smooth due to team issues. Note that the below measures can result in some team members doing more work than others and earning better project grades than others. It is still better than sinking the whole team together.
-
Redistribute the work: Stronger programmers in the team should take over the critical parts of the code.
-
Enforce stricter integration workflow: Appoint an integrator (typically, the strongest programmer). His/her job is to maintain the integrated version of the code. He/she should not accept any code that breaks the existing product or is not up to the acceptable quality standard. It is up to others to submit acceptable code to the integrator. Note that if the integrator rejected your code unreasonably, you can still earn marks for that code. You are allowed to submit such 'rejected' code for grading. They can earn marks based on the quality of the code.
If you have very unreliable or totally disengaged team members :
- Re-allocate to others any mission-critical work allocated to that person so that such team members cannot bring down the entire team.
- However, do not leave out such team members from project communications. Always keep them in the loop so that they can contribute any time they wish to.
- Furthermore, evaluate them sincerely and fairly during peer evaluations so that they do get the grade their work deserves, no more, no less.
- Be courteous to such team members too. Some folks have genuine problems that prevent them from contributing more although they may not be able tell you the reasons. Just do your best for the project and assume everyone else is doing their best too, although their best may be lower than yours.
Why I’m not allowed to use my favorite tool/framework/language etc.?
We have chosen a basic set of tools after considering ease of learning, availability, typical-ness, popularity, migration path to other tools, etc. There are many reasons for limiting your choices:
Pedagogical reasons:
- Sometimes 'good enough', not necessarily the best, tools are a better fit for beginners: Most bleeding edge, most specialized, or most sophisticated tools are not suitable for a beginner course. After mastering our toolset, you will find it easy to upgrade to such high-end tools by yourself. We do expect you to eventually (after this module) migrate to better tools and, having learned more than one tool, to attain a more general understanding about a family of tools.
- We want you to learn to thrive under given conditions: As a professional Software Engineer, you must learn to be productive in any given tool environment, rather than insist on using your preferred tools. It is usually in small companies doing less important work that you get to chose your own toolset. Bigger companies working on mature products often impose some choices on developers, such as the project management tool, code repository, IDE, language etc. For example, Google used SVN as their revision control software until very recently, long after SVN fell out of popularity among developers. Sometimes this is due to cost reasons (tool licensing cost), and sometimes due to legacy reasons (because the tool is already entrenched in their code base).
While programming in school is often a solo sport, programming in the industry is a team sport. As we are training you to become professional software engineers, it is important to get over the psychological hurdle of needing to satisfy individual preferences and get used to making the best of a given environment.
Practical reasons:
- Some of the LOs are tightly coupled to tools. Allowing more tools means tutors need to learn more tools, which increases their workload.
- We provide learning resources for tools. e.g. 'Git guides'. Allowing more tools means we need to produce more resources.
- When all students use the same tool, the collective expertise of the tool is more, increasing the opportunities for you to learn from each others.
Meanwhile, feel free to share with peers your experience of using other tools.
Outcomes
Design
W7.1 Can explain architectural styles
W7.1a Can explain architectural styles
Design → Architecture → Styles
Software architectures follow various high-level styles (aka architectural patterns), just like
n-tier style, client-server style, event-driven style, transaction processing style, service-oriented style, pipes-and-filters style, message-driven style, broker style, ...
source: https://inspectapedia.com
W7.1b Can identify n-tier architectural style
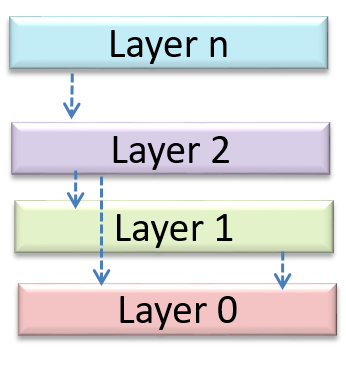
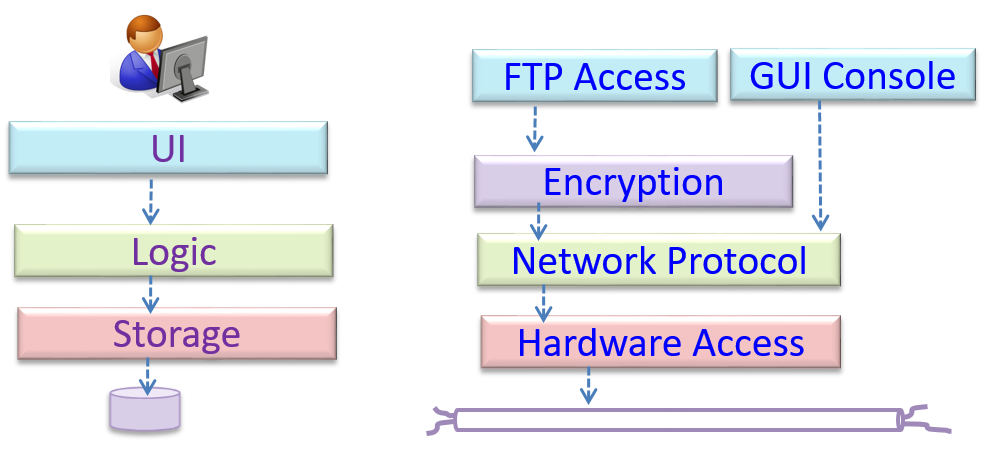
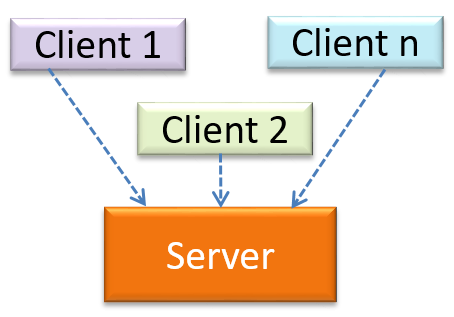
W7.1c Can identify the client-server architectural style
Design → Architecture → Styles → Client-Server Style
The client-server style has at least one component playing the role of a server and at least one client component accessing the services of the server. This is an architectural style used often in distributed applications.
The online game and the Web application below uses the client-server style.
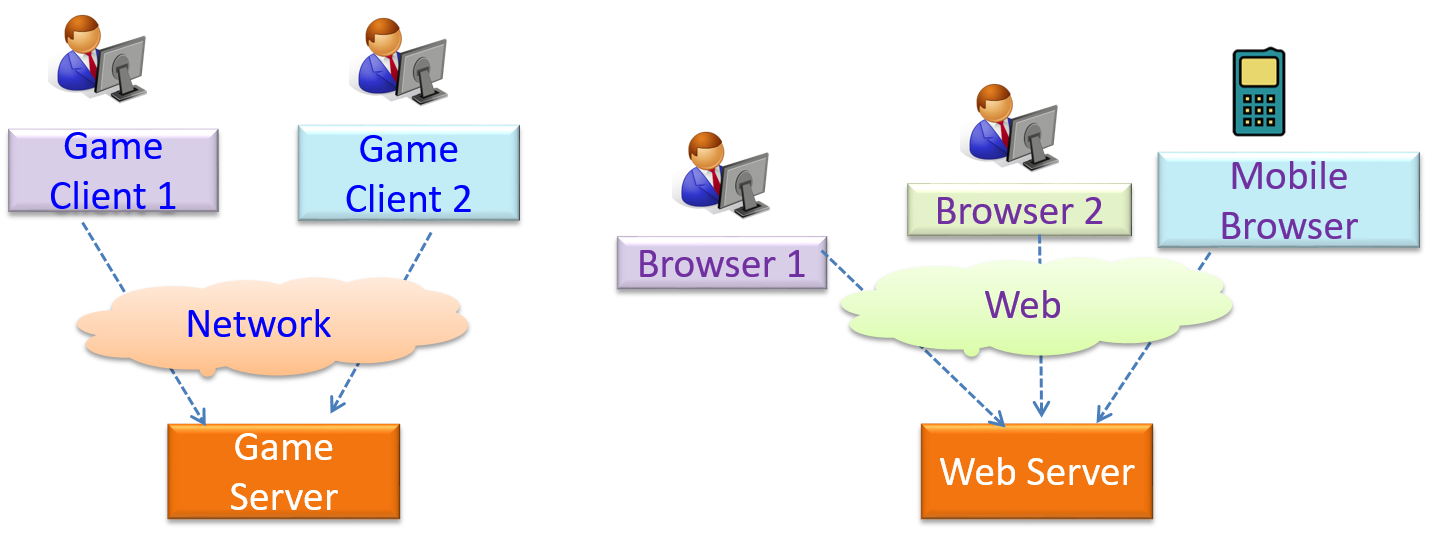
W7.1d Can identify event-driven architectural style
Design → Architecture → Styles → Event-Driven Style
Event-driven style controls the flow of the application by detecting
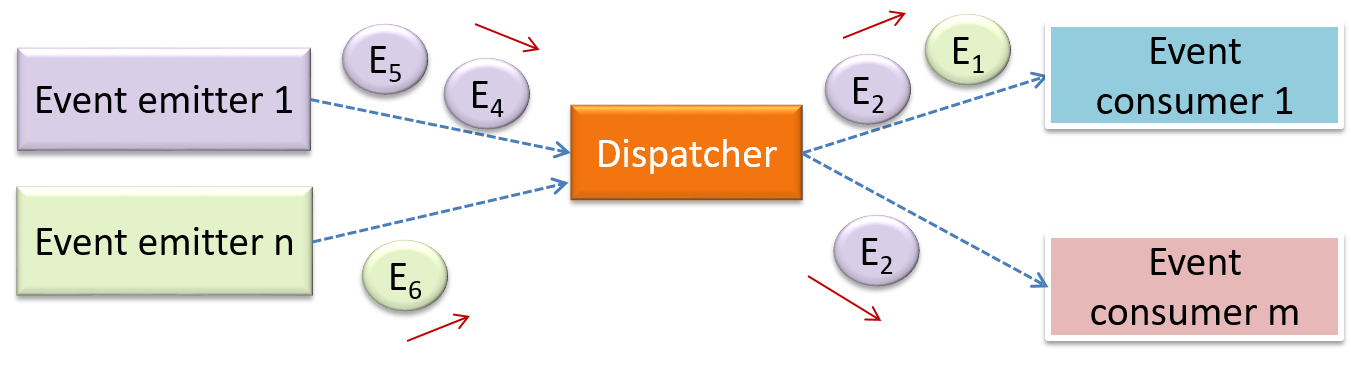
When the ‘button clicked’ event occurs in a GUI, that event can be transmitted to components that are interested in reacting to that event. Similarly, events detected at a Printer port can be transmitted to components related to operating the Printer. The same event can be sent to multiple consumers too.
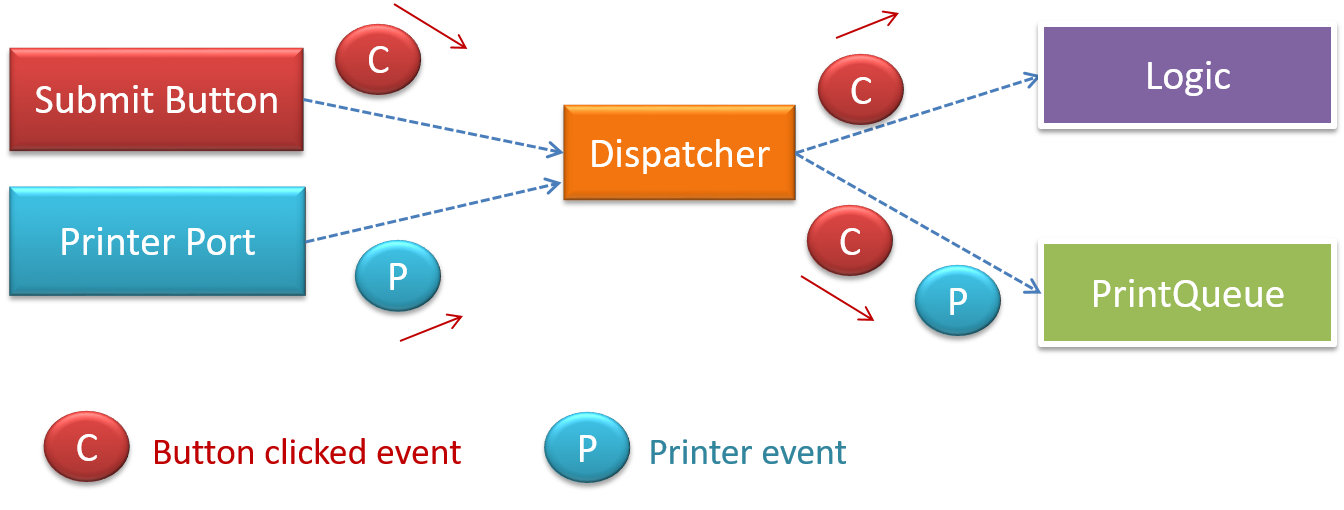
Evidence:
Explain how the AddressBook-Level4 uses Event-Driven style (refer to the Developer Guide for more info).
W7.1e Can identify transaction processing architectural style
Design → Architecture → Styles → Transaction Processing Style
The transaction processing style divides the workload of the system down to a number of transactions which are then given to a dispatcher that controls the execution of each transaction. Task queuing, ordering, undo etc. are handled by the dispatcher.
In this example from a Banking system, transactions are generated by the terminals used by
W7.1f Can identify service-oriented architectural style
Design → Architecture → Styles → Service-Oriented Style
The service-oriented architecture (SOA) style builds applications by combining functionalities packaged as programmatically accessible services. SOA aims to achieve interoperability between distributed services, which may not even be implemented using the same programming language. A common way to implement SOA is through the use of XML web services where the web is used as the medium for the services to interact, and XML is used as the language of communication between service providers and service users.
Suppose that Amazon.com provides a web service for customers to browse and buy merchandise, while HSBC provides a web service for merchants to charge HSBC credit cards. Using these web services, an ‘eBookShop’ web application can be developed that allows HSBC customers to buy merchandise from Amazon and pay for them using HSBC credit cards. Because both Amazon and HSBC services follow the SOA architecture, their web services can be reused by the web application, even if all three systems use different programming platforms.
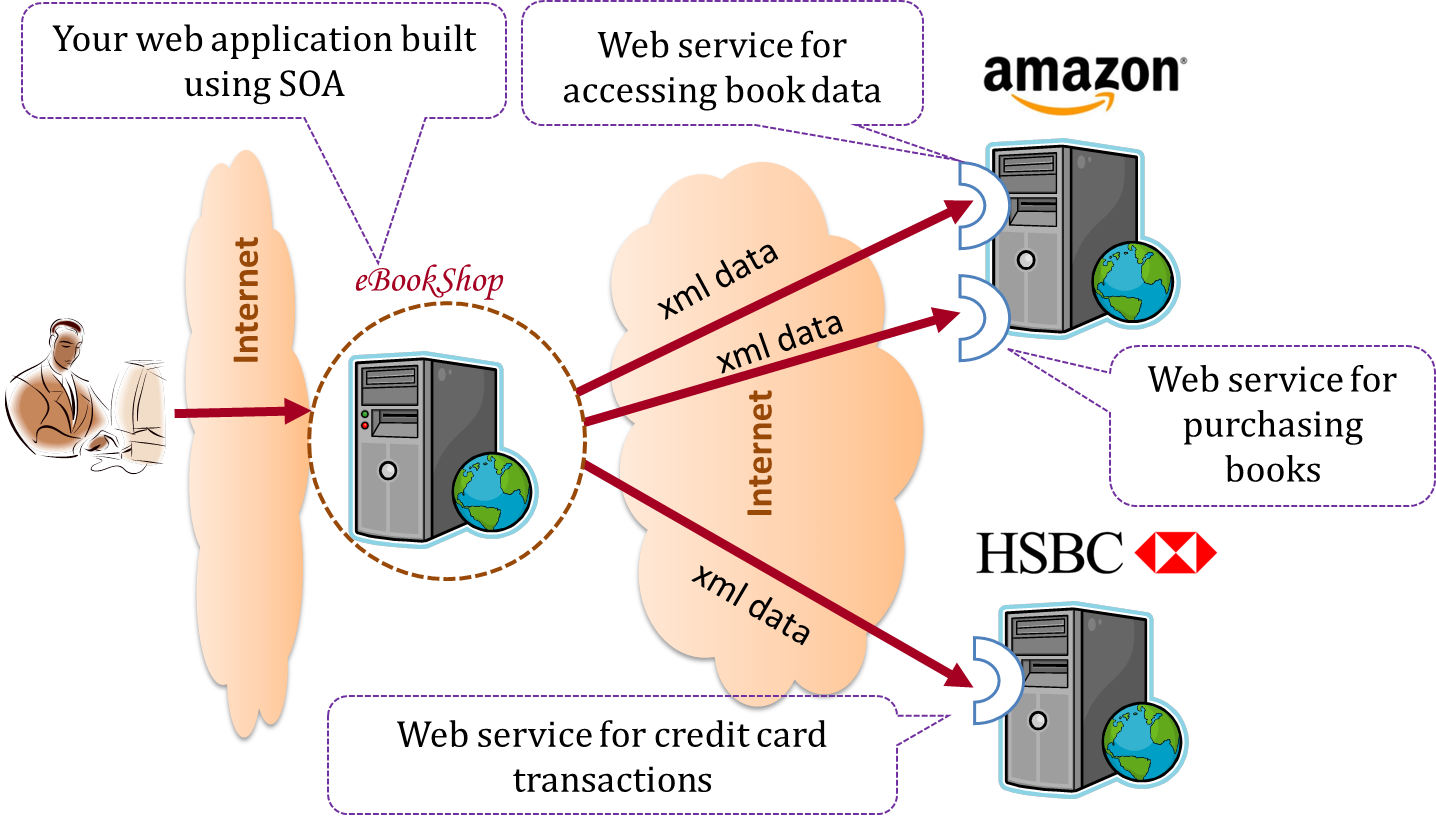
W7.1g Can name several other architecture styles
Design → Architecture → Styles
Other well-known architectural styles include the pipes-and-filters architectures, the broker architectures, the peer-to-peer architectures, and the message-oriented architectures.
-
Pipes and Filters pattern -- an article from Microsoft about the pipes and filters architectural style
-
Broker pattern -- Wikipedia article on the broker architectural style
-
Peer-to-peer pattern -- Wikipedia article on the P2P architectural style
-
Message-driven processing -- a post by Margaret Rouse
W7.1h Can explain how architectural styles are combined
Design → Architecture → Styles
Most applications use a mix of these architectural styles.
An application can use a client-server architecture where the server component comprises several layers, i.e. it uses the n-Tier architecture.
Assume you are designing a multiplayer version of the Minesweeper game where any number of players can play the same Minefield. Players use their own PCs to play the game. A player scores by deducing a cell correctly before any of the other players do. Once a cell is correctly deduced, it appears as either marked or cleared for all players.
Comment on how each of the following architectural styles could be potentially useful when designing the architecture for this game.
- Client-server
- Transaction-processing
- SOA (Service Oriented Architecture)
- multi-layer (n-tier)
- Client-server – Clients can be the game UI running on player PCs. The server can be the game logic running on one machine.
- Transaction-processing – Each player action can be packaged as transactions (by the client component running on the player PC) and sent to the server. Server processes them in the order they are received.
- SOA – The game can access a remote web services for things such as getting new puzzles, validating puzzles, charging players subscription fees, etc.
- Multi-layer – The server component can have two layers: logic layer and the storage layer.
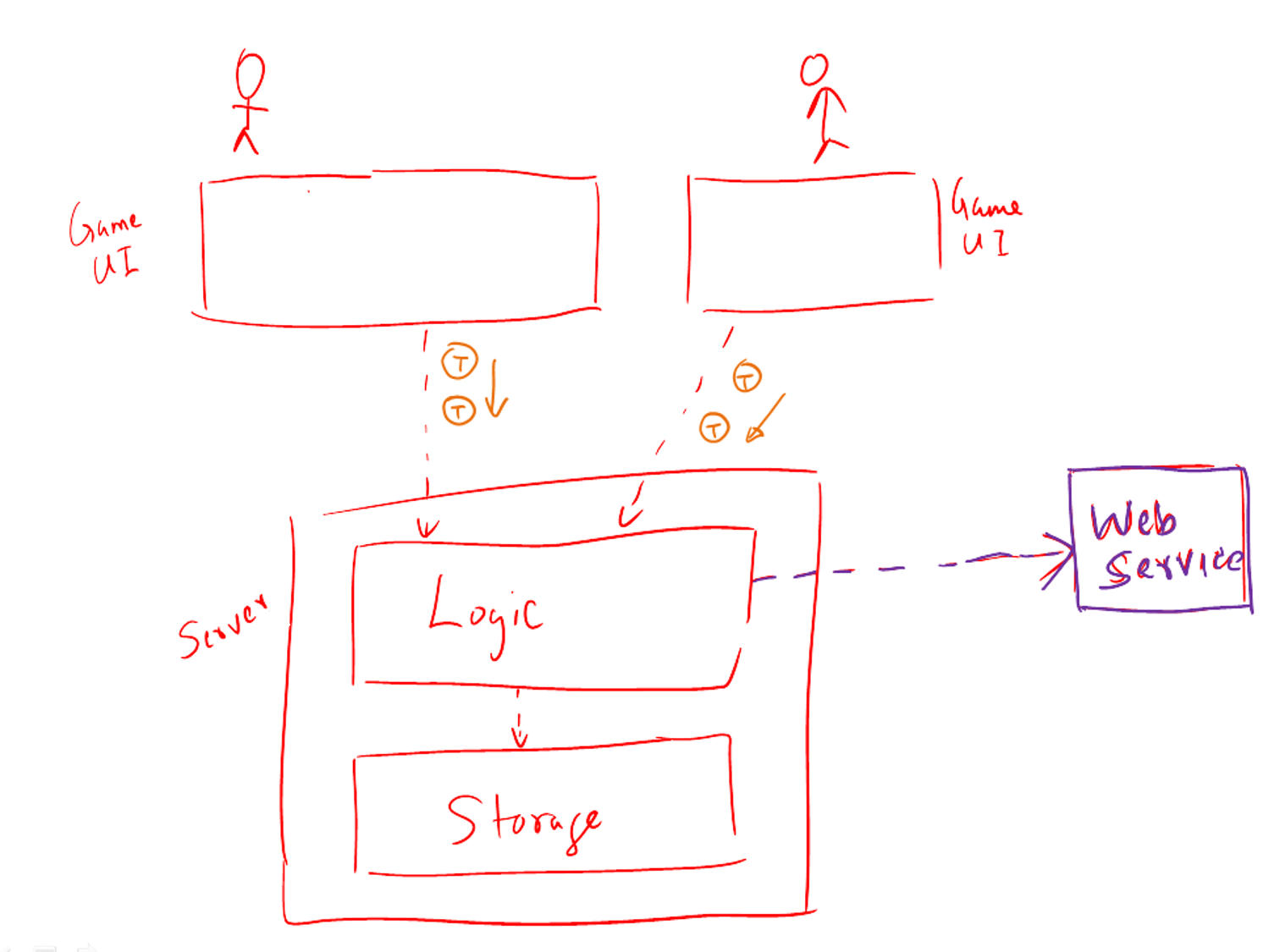
Evidence:
Explain architectural styles currently used in AddressBook-Level4. Speculate under what circumstances other architectural styles can be used in it e.g. what kind of additional features can make a certain style applicable
W7.2 Can explain APIs
W7.2a Can explain APIs
Implementation → Reuse → APIs →
An Application Programming Interface (API) specifies the interface through which other programs can interact with a software component. It is a contract between the component and its clients.
A class has an API (e.g., API of the Java String class, API of the Python str class) which is a collection of public methods that you can invoke to make use of the class.
The GitHub API is a collection of Web request formats GitHub server accepts and the corresponding responses. We can write a program that interacts with GitHub through that API.
When developing large systems, if you define the API of each components early, the development team can develop the components in parallel because the future behavior of the other components are now more predictable.
Choose the correct statements
- a. A software component can have an API.
- b. Any method of a class is part of its API.
- c. Private methods of a class are not part of its API.
- d. The API forms the contract between the component developer and the component user.
- e. Sequence diagrams can be used to show how components interact with each other via APIs.
(a) (c) (d) (e)
Explanation: (b) is incorrect because private methods cannot be a part of the API
Defining component APIs early is useful for developing components in parallel.
True
Explanation: Yes, once we know the precise behavior expected of each component, we can start developing them in parallel.
Evidence:
Know the API of the AddressBook component you are in charge of and the APIs of the other components your component depends on.
W7.3 Can use intermediate-level sequence diagrams
W7.3a Can draw intermediate-level sequence diagrams
Design → Modelling → Modelling Behaviors
What’s going on here?
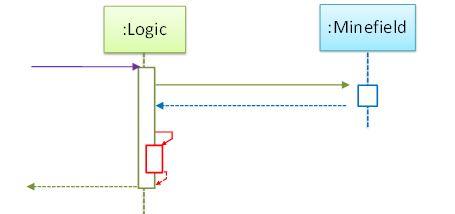
- a.
Logicobject is executing a parallel thread. - b.
Logicobject is executing a loop. - c.
Logicobject is creating anotherLogicinstance. - d. One of
Logicobject’s methods is calling another of its methods. - e.
Minefieldobject is calling a method ofLogic.
(d)
Explain the interactions depicted in this sequence diagram.
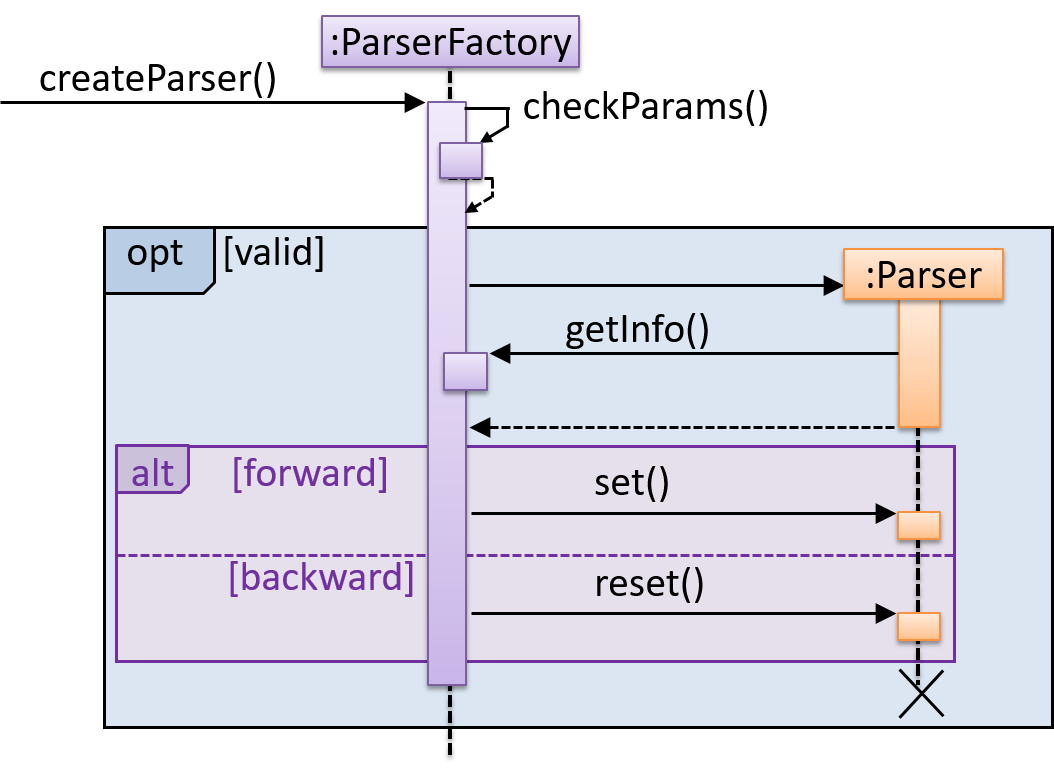
First, the createParser() method of an existing ParserFactory object is called. Then, ...
Draw a sequence diagram to represent this code snippet.
if (isFirstPage) {
new Quote().print();
}
The Quote class:
class Quote{
String q;
Quote(){
q = generate();
}
String generate(){
// ...
}
void print(){
System.out.println(q);
}
}
- Show
new Quote().print();as two method calls. - As the created Quote object is not assigned to a variable, it can be considered as 'deleted' soon after its
print()method is called.
Evidence:
Explain the interactions depicted in this sequence diagram.
First, the createParser() method of an existing ParserFactory object is called. Then, ...
Draw a sequence diagram to represent this code snippet.
if (isFirstPage) {
new Quote().print();
}
The Quote class:
class Quote{
String q;
Quote(){
q = generate();
}
String generate(){
// ...
}
void print(){
System.out.println(q);
}
}
- Show
new Quote().print();as two method calls. - As the created Quote object is not assigned to a variable, it can be considered as 'deleted' soon after its
print()method is called.
- Ability to explain the sequence diagrams given [AddressBook Level4: Developer Guide]
- Ability to add more sequence diagrams to project documentation (to be done in future weeks)
W7.3b Can interpret sequence diagrams with reference frames
Tools → UML → Sequence Diagrams →
UML uses ref frame to allow a segment of the interaction to be omitted and shown as a separate sequence diagram. Reference frames help us to break complicated sequence diagrams into multiple parts or simply to omit details we are not interested in showing.
Notation:

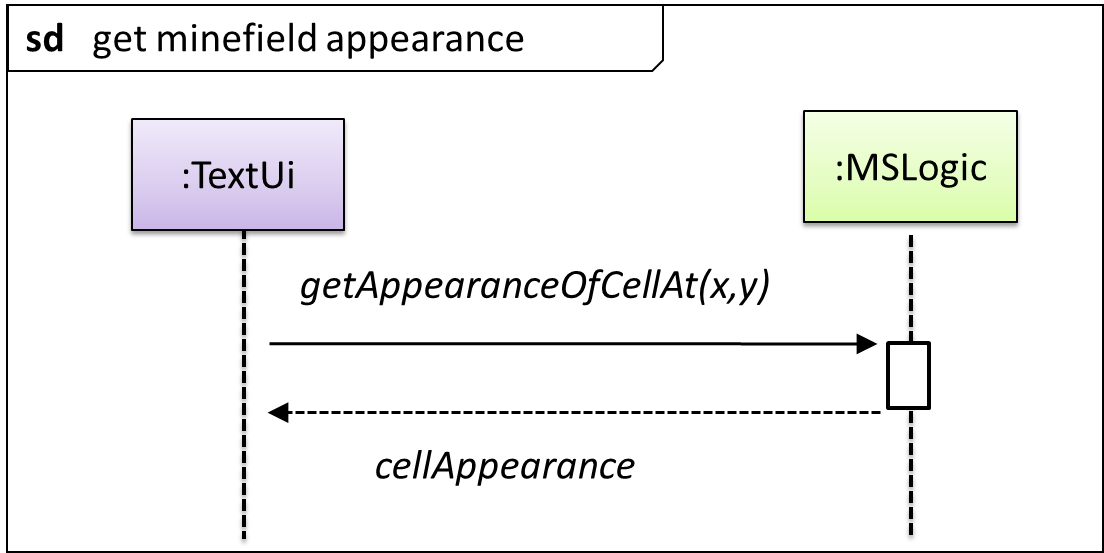
The details of the get minefield appearance interactions have been omitted from the diagram.
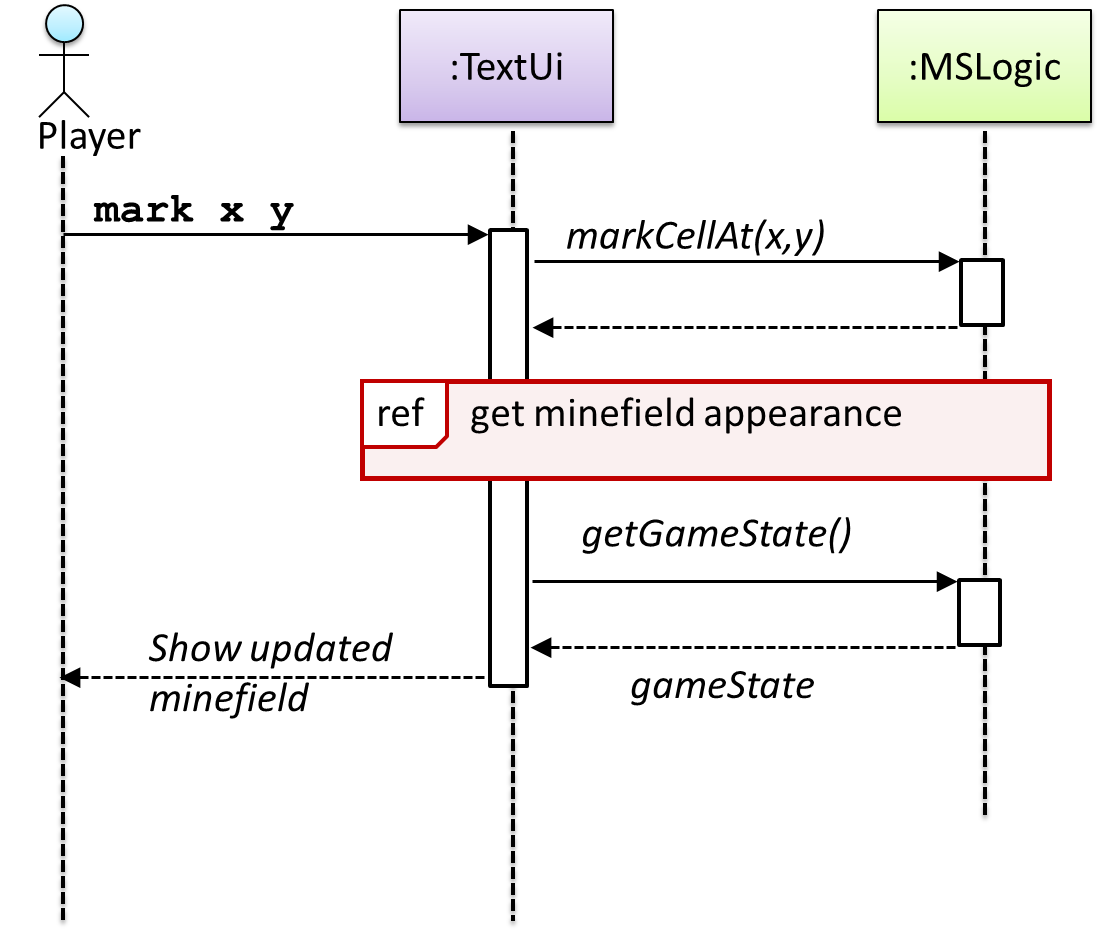
Those details are shown in a separate sequence diagram given below.
W7.3c Can interpret sequence diagrams with parallel paths
Tools → UML → Sequence Diagrams →
UML uses par frames to indicate parallel paths.
Notation:

Logic is calling methods CloudServer#poll() and LocalServer#poll() in parallel.
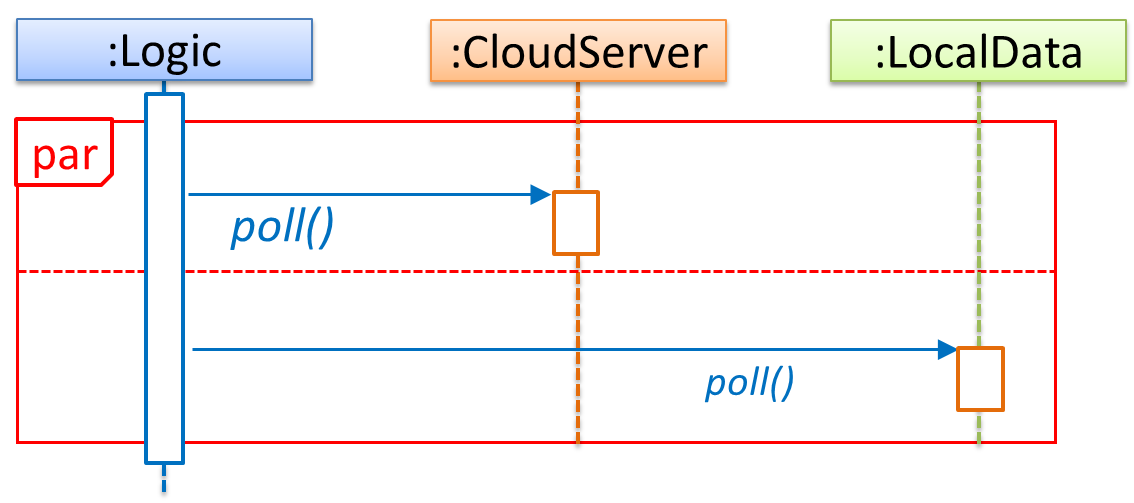
💡 If you show parallel paths in a sequence diagram, the corresponding Java implementation is likely to be multi-threaded because a normal Java program cannot do multiple things at the same time.
Implementation
W7.4 Can improve code readability
W7.4a Can explain the importance of readability
Implementation → Code Quality → Readability →
Programs should be written and polished until they acquire publication quality. --Niklaus Wirth
Among various dimensions of code quality, such as run-time efficiency, security, and robustness, one of the most important is understandability. This is because in any non-trivial software project, code needs to be read, understood, and modified by other developers later on. Even if we do not intend to pass the code to someone else, code quality is still important because we all become 'strangers' to our own code someday.
The two code samples given below achieve the same functionality, but one is easier to read.
|
Bad |
|
Good |
|
Bad |
|
Good |
W7.4b Can improve code quality using technique: avoid long methods
W7.4c Can improve code quality using technique: avoid deep nesting
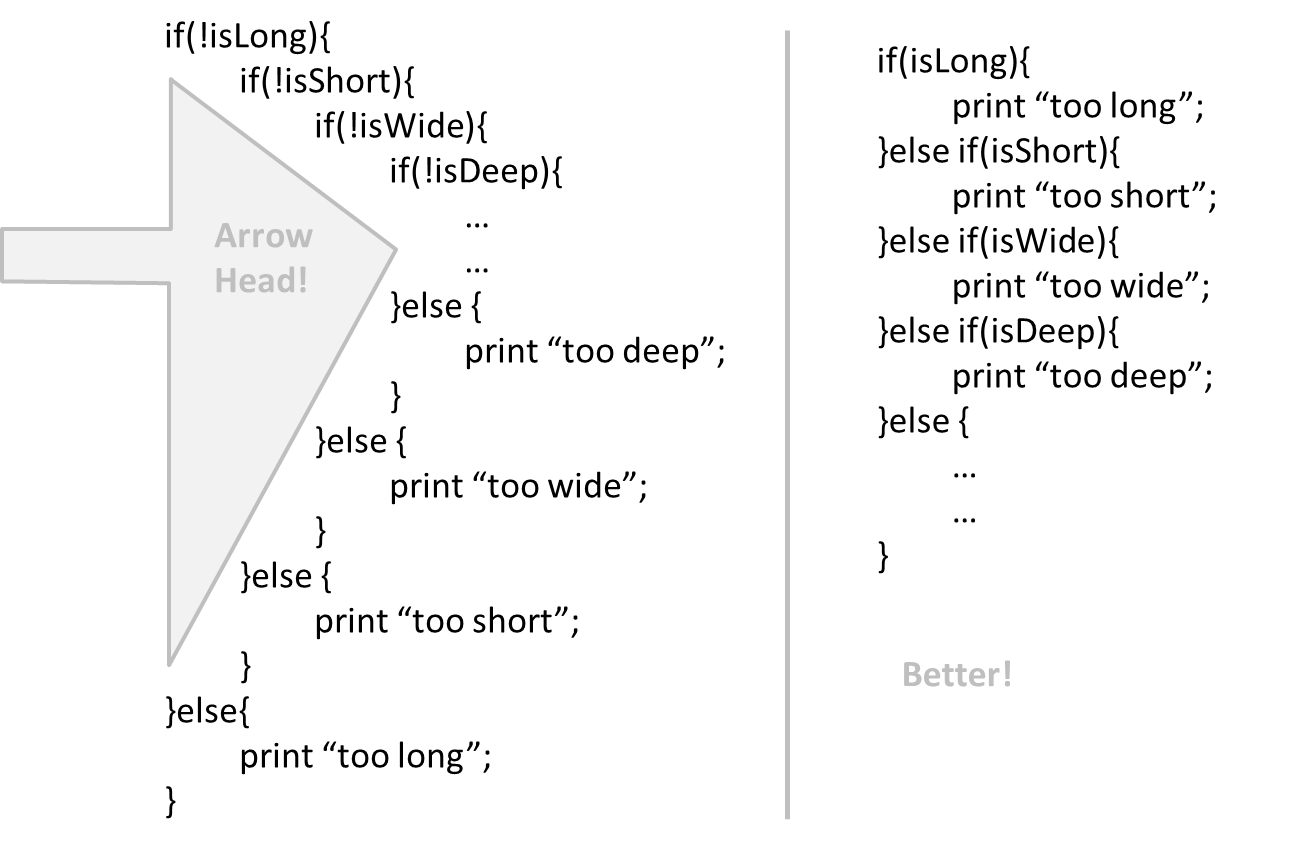
Implementation → Code Quality → Readability → Basic →
If you need more than 3 levels of indentation, you're screwed anyway, and should fix your program. --Linux 1.3.53 CodingStyle
In particular, avoid arrowhead style code.
Example:
W7.4d Can improve code quality using technique: avoid complicated expressions
Implementation → Code Quality → Readability → Basic →
Avoid complicated expressions, especially those having many negations and nested parentheses. If you must evaluate complicated expressions, have it done in steps (i.e. calculate some intermediate values first and use them to calculate the final value).
Example:
Bad
return ((length < MAX_LENGTH) || (previousSize != length)) && (typeCode == URGENT);
Good
boolean isWithinSizeLimit = length < MAX_LENGTH;
boolean isSameSize = previousSize != length;
boolean isValidCode = isWithinSizeLimit || isSameSize;
boolean isUrgent = typeCode == URGENT;
return isValidCode && isUrgent;
Example:
Bad
return ((length < MAX_LENGTH) or (previous_size != length)) and (type_code == URGENT)
Good
is_within_size_limit = length < MAX_LENGTH
is_same_size = previous_size != length
is_valid_code = is_within_size_limit or is_same_size
is_urgent = type_code == URGENT
return is_valid_code and is_urgent
The competent programmer is fully aware of the strictly limited size of his own skull; therefore he approaches the programming task in full humility, and among other things he avoids clever tricks like the plague. -- Edsger Dijkstra
W7.4e Can improve code quality using technique: avoid magic numbers
Implementation → Code Quality → Readability → Basic →
When the code has a number that does not explain the meaning of the number, we call that a magic number (as in “the number appears as if by magic”). Using a
Example:
|
Bad |
|
Good |
Note: Python does not have a way to make a variable a constant. However, you can use a normal variable with an ALL_CAPS name to simulate a constant.
|
Bad |
|
Good |
Similarly, we can have ‘magic’ values of other data types.
Bad
"Error 1432" // A magic string!
W7.4f Can improve code quality using technique: make the code obvious
Implementation → Code Quality → Readability → Basic →
Make the code as explicit as possible, even if the language syntax allows them to be implicit. Here are some examples:
- [
Java] Use explicit type conversion instead of implicit type conversion. - [
Java,Python] Use parentheses/braces to show grouping even when they can be skipped. - [
Java,Python] Useenumerations when a certain variable can take only a small number of finite values. For example, instead of declaring the variable 'state' as an integer and using values 0,1,2 to denote the states 'starting', 'enabled', and 'disabled' respectively, declare 'state' as typeSystemStateand define an enumerationSystemStatethat has values'STARTING','ENABLED', and'DISABLED'.
W7.4g Can improve code quality using technique: structure code logically
Implementation → Code Quality → Readability → Intermediate →
Lay out the code so that it adheres to the logical structure. The code should read like a story. Just like we use section breaks, chapters and paragraphs to organize a story, use classes, methods, indentation and line spacing in your code to group related segments of the code. For example, you can use blank lines to group related statements together. Sometimes, the correctness of your code does not depend on the order in which you perform certain intermediary steps. Nevertheless, this order may affect the clarity of the story you are trying to tell. Choose the order that makes the story most readable.
W7.4h Can improve code quality using technique: do not 'trip up' reader
Implementation → Code Quality → Readability → Intermediate →
Avoid things that would make the reader go ‘huh?’, such as,
- unused parameters in the method signature
- similar things look different
- different things that look similar
- multiple statements in the same line
- data flow anomalies such as, pre-assigning values to variables and modifying it without any use of the pre-assigned value
W7.4i Can improve code quality using technique: practice kissing
Implementation → Code Quality → Readability → Intermediate →
As the old adage goes, "keep it simple, stupid” (KISS). Do not try to write ‘clever’ code. For example, do not dismiss the brute-force yet simple solution in favor of a complicated one because of some ‘supposed benefits’ such as 'better reusability' unless you have a strong justification.
Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it. --Brian W. Kernighan
Programs must be written for people to read, and only incidentally for machines to execute. --Abelson and Sussman
W7.4j Can improve code quality using technique: avoid premature optimizations
Implementation → Code Quality → Readability → Intermediate →
Optimizing code prematurely has several drawbacks:
- We may not know which parts are the real performance bottlenecks. This is especially the case when the code undergoes transformations (e.g. compiling, minifying, transpiling, etc.) before it becomes an executable. Ideally, you should use a profiler tool to identify the actual bottlenecks of the code first, and optimize only those parts.
- Optimizing can complicate the code, affecting correctness and understandability
- Hand-optimized code can be harder for the compiler to optimize (the simpler the code, the easier for the compiler to optimize it). In many cases a compiler can do a better job of optimizing the runtime code if you don't get in the way by trying to hand-optimize the source code.
A popular saying in the industry is make it work, make it right, make it fast which means in most cases getting the code to perform correctly should take priority over optimizing it. If the code doesn't work correctly, it has no value on matter how fast/efficient it it.
Premature optimization is the root of all evil in programming. --Donald Knuth
Note that there are cases where optimizing takes priority over other things e.g. when writing code for resource-constrained environments. This guideline simply a caution that you should optimize only when it is really needed.
W7.4k Can improve code quality using technique: SLAP hard
Implementation → Code Quality → Readability → Intermediate →
Avoid varying the level of
Example:
Bad
readData();
salary = basic*rise+1000;
tax = (taxable?salary*0.07:0);
displayResult();
Good
readData();
processData();
displayResult();
Design → Design Fundamentals → Abstraction →
Abstraction is a technique for dealing with complexity. It works by establishing a level of complexity we are interested in, and suppressing the more complex details below that level.
The guiding principle of abstraction is that only details that are relevant to the current perspective or the task at hand needs to be considered. As most programs are written to solve complex problems involving large amounts of intricate details, it is impossible to deal with all these details at the same time. That is where abstraction can help.
Ignoring lower level data items and thinking in terms of bigger entities is called data abstraction.
Within a certain software component, we might deal with a user data type, while ignoring the details contained in the user data item such as name, and date of birth. These details have been ‘abstracted away’ as they do not affect the task of that software component.
Control abstraction abstracts away details of the actual control flow to focus on tasks at a simplified level.
print(“Hello”) is an abstraction of the actual output mechanism within the computer.
Abstraction can be applied repeatedly to obtain progressively higher levels of abstractions.
An example of different levels of data abstraction: a File is a data item that is at a higher level than an array and an array is at a higher level than a bit.
An example of different levels of control abstraction: execute(Game) is at a higher level than print(Char) which is at a higher than an Assembly language instruction MOV.
Abstraction is a general concept that is not limited to just data or control abstractions.
Some more general examples of abstraction:
- An OOP class is an abstraction over related data and behaviors.
- An architecture is a higher-level abstraction of the design of a software.
- Models (e.g., UML models) are abstractions of some aspect of reality.
W7.4l Can improve code quality using technique: make the happy path prominent
Implementation → Code Quality → Readability → Advanced →
The happy path (i.e. the execution path taken when everything goes well) should be clear and prominent in your code. Restructure the code to make the happy path unindented as much as possible. It is the ‘unusual’ cases that should be indented. Someone reading the code should not get distracted by alternative paths taken when error conditions happen. One technique that could help in this regard is the use of guard clauses.
Example:
Bad
if (!isUnusualCase) { //detecting an unusual condition
if (!isErrorCase) {
start(); //main path
process();
cleanup();
exit();
} else {
handleError();
}
} else {
handleUnusualCase(); //handling that unusual condition
}
In the code above,
- Unusual condition detection is separated from their handling.
- Main path is nested deeply.
Good
if (isUnusualCase) { //Guard Clause
handleUnusualCase();
return;
}
if (isErrorCase) { //Guard Clause
handleError();
return;
}
start();
process();
cleanup();
exit();
In contrast, the above code
- deals with unusual conditions as soon as they are detected so that the reader doesn't have to remember them for long.
- keeps the main path un-indented.
W7.5 Can use good naming
W7.5a Can explain the need for good names in code
W7.5b Can improve code quality using technique: use nouns for things and verbs for actions
Implementation → Code Quality → Naming → Basic →
Every system is built from a domain-specific language designed by the programmers to describe that system. Functions are the verbs of that language, and classes are the nouns. ― Robert C. Martin, Clean Code: A Handbook of Agile Software Craftsmanship
Use nouns for classes/variables and verbs for methods/functions.
Examples:
| Name for a | Bad | Good |
|---|---|---|
| Class | CheckLimit |
LimitChecker |
| method | result() |
calculate() |
Distinguish clearly between single-valued and multivalued variables.
Examples:
Good
Person student;
ArrayList<Person> students;
Good
student = Person('Jim')
students = [Person('Jim'), Person('Alice')]
W7.5c Can improve code quality using technique: use standard words
Implementation → Code Quality → Naming → Basic →
W7.5d Can improve code quality using technique: use name to explain
Implementation → Code Quality → Naming → Intermediate →
A name is not just for differentiation; it should explain the named entity to the reader accurately and at a sufficient level of detail.
Examples:
| Bad | Good |
|---|---|
processInput() (what 'process'?) |
removeWhiteSpaceFromInput() |
flag |
isValidInput |
temp |
If the name has multiple words, they should be in a sensible order.
Examples:
| Bad | Good |
|---|---|
bySizeOrder() |
orderBySize() |
Imagine going to the doctor's and saying "My eye1 is swollen"! Don’t use numbers or case to distinguish names.
Examples:
| Bad | Bad | Good |
|---|---|---|
value1, value2 |
value, Value |
originalValue, finalValue |
W7.5e Can improve code quality using technique: not too long, not too short
W7.5f Can improve code quality using technique: avoid misleading names
Implementation → Code Quality → Naming → Intermediate →
Related things should be named similarly, while unrelated things should NOT.
Example: Consider these variables
colorBlack: hex value for color blackcolorWhite: hex value for color whitecolorBlue: number of times blue is usedhexForRed: : hex value for color red
This is misleading because colorBlue is named similar to colorWhite and colorBlack but has a different purpose while hexForRed is named differently but has very similar purpose to the first two variables. The following is better:
hexForBlackhexForWhitehexForRedblueColorCount
Avoid misleading or ambiguous names (e.g. those with multiple meanings), similar sounding names, hard-to-pronounce ones (e.g. avoid ambiguities like "is that a lowercase L, capital I or number 1?", or "is that number 0 or letter O?"), almost similar names.
Examples:
| Bad | Good | Reason |
|---|---|---|
phase0 |
phaseZero |
Is that zero or letter O? |
rwrLgtDirn |
rowerLegitDirection |
Hard to pronounce |
right left wrong |
rightDirection leftDirection wrongResponse |
right is for 'correct' or 'opposite of 'left'? |
redBooks readBooks |
redColorBooks booksRead |
red and read (past tense) sounds the same |
FiletMignon |
egg |
If the requirement is just a name of a food, egg is a much easier to type/say choice than FiletMignon |
W7.6 Can avoid unsafe coding practices
W7.6a Can explain the need for avoiding error-prone shortcuts
W7.6b Can improve code quality using technique: use the default branch
Implementation → Code Quality → Error-Prone Practices → Basic →
Always include a default branch in case statements.
Furthermore, use it for the intended default action and not just to execute the last option. If there is no default action, you can use the 'default' branch to detect errors (i.e. if execution reached the default branch, throw an exception). This also applies to the final else of an if-else construct. That is, the final else should mean 'everything else', and not the final option. Do not use else when an if condition can be explicitly specified, unless there is absolutely no other possibility.
Bad
if (red) print "red";
else print "blue";
Good
if (red) print "red";
else if (blue) print "blue";
else error("incorrect input");
W7.6c Can improve code quality using technique: don't recycle variables or parameters
Implementation → Code Quality → Error-Prone Practices → Basic →
- Use one variable for one purpose. Do not reuse a variable for a different purpose other than its intended one, just because the data type is the same.
- Do not reuse formal parameters as local variables inside the method.
Bad
double computeRectangleArea(double length, double width) {
length = length * width;
return length;
}
Good
double computeRectangleArea(double length, double width) {
double area;
area = length * width;
return area;
}
W7.6d Can improve code quality using technique: avoid empty catch blocks
W7.6e Can improve code quality using technique: delete dead code
Implementation → Code Quality → Error-Prone Practices → Basic →
We all feel reluctant to delete code we have painstakingly written, even if we have no use for that code any more ("I spent a lot of time writing that code; what if we need it again?"). Consider all code as baggage you have to carry; get rid of unused code the moment it becomes redundant. If you need that code again, simply recover it from the revision control tool you are using. Deleting code you wrote previously is a sign that you are improving.
W7.6f Can improve code quality using technique: minimise scope of variables
Implementation → Code Quality → Error-Prone Practices → Intermediate →
Minimize global variables. Global variables may be the most convenient way to pass information around, but they do create implicit links between code segments that use the global variable. Avoid them as much as possible.
Define variables in the least possible scope. For example, if the variable is used only within the if block of the conditional statement, it should be declared inside that if block.
The most powerful technique for minimizing the scope of a local variable is to declare it where it is first used. -- Effective Java, by Joshua Bloch
Resources:
W7.6g Can improve code quality using technique: minimise code duplication
Implementation → Code Quality → Error-Prone Practices → Intermediate →
Code duplication, especially when you copy-paste-modify code, often indicates a poor quality implementation. While it may not be possible to have zero duplication, always think twice before duplicating code; most often there is a better alternative.
This guideline is closely related to the
Supplmentary → Principles →
DRY (Don't Repeat Yourself) Principle: Every piece of knowledge must have a single, unambiguous, authoritative representation within a system The Pragmatic Programmer, by Andy Hunt and Dave Thomas
This principle guards against duplication of information.
The functionality implemented twice is a violation of the DRY principle even if the two implementations are different.
The value a system-wide timeout being defined in multiple places is a violation of DRY.
W7.7 Can write good code comments
W7.7a Can explain the need for commenting minimally but sufficiently
Implementation → Code Quality → Comments →
Good code is its own best documentation. As you’re about to add a comment, ask yourself, ‘How can I improve the code so that this comment isn’t needed?’ Improve the code and then document it to make it even clearer. --Steve McConnell, Author of Clean Code
Some think commenting heavily increases the 'code quality'. This is not so. Avoid writing comments to explain bad code. Improve the code to make it self-explanatory.
W7.7b Can improve code quality using technique: do not repeat the obvious
W7.7c Can improve code quality using technique: write to the reader
Implementation → Code Quality → Comments → Basic →
Do not write comments as if they are private notes to self. Instead, write them well enough to be understood by another programmer. One type of comments that is almost always useful is the header comment that you write for a class or an operation to explain its purpose.
Examples:
Bad Reason: this comment will only make sense to the person who wrote it
// a quick trim function used to fix bug I detected overnight
void trimInput(){
....
}
Good
/** Trims the input of leading and trailing spaces */
void trimInput(){
....
}
Bad Reason: this comment will only make sense to the person who wrote it
# a quick trim function used to fix bug I detected overnight
def trim_input():
...
Good
def trim_input():
"""Trim the input of leading and trailing spaces"""
...
W7.7d Can improve code quality using technique: explain what and why, not how
Implementation → Code Quality → Comments → Intermediate →
Comments should explain what and why aspect of the code, rather than the how aspect.
What : The specification of what the code supposed to do. The reader can compare such comments to the implementation to verify if the implementation is correct
Example: This method is possibly buggy because the implementation does not seem to match the comment. In this case the comment could help the reader to detect the bug.
/** Removes all spaces from the {@code input} */
void compact(String input){
input.trim();
}
Why : The rationale for the current implementation.
Example: Without this comment, the reader will not know the reason for calling this method.
// Remove spaces to comply with IE23.5 formatting rules
compact(input);
How : The explanation for how the code works. This should already be apparent from the code, if the code is self-explanatory. Adding comments to explain the same thing is redundant.
Example:
Bad Reason: Comment explains how the code works.
// return true if both left end and right end are correct or the size has not incremented
return (left && right) || (input.size() == size);
Good Reason: Code refactored to be self-explanatory. Comment no longer needed.
boolean isSameSize = (input.size() == size) ;
return (isLeftEndCorrect && isRightEndCorrect) || isSameSize;
🅿️ Project
W7.8 Can do small changes to an existing software
Covered by the 'Product' component of v1.1:
Tutorial 7
Questions to discuss during tutorial:
- Which architecture styles are used by AB-4?
- What is an API? How is it used in AB-4?
Explain the interactions depicted in this sequence diagram.
First, the createParser() method of an existing ParserFactory object is called. Then, ...
Draw a sequence diagram to represent this code snippet.
if (isFirstPage) {
new Quote().print();
}
The Quote class:
class Quote{
String q;
Quote(){
q = generate();
}
String generate(){
// ...
}
void print(){
System.out.println(q);
}
}
- Show
new Quote().print();as two method calls. - As the created Quote object is not assigned to a variable, it can be considered as 'deleted' soon after its
print()method is called.
See the chapter on Code Quality.
Suggest ways to improve the quality of the code below.
import java.io.FileNotFoundException;
import java.util.*;
public class CliApp {
//...
private static final String MESSAGE_COMMAND_HELP_PARAMETERS = "Parameters: %1$s";
private static final String MESSAGE_COMMAND_HELP_EXAMPLE = "Example: %1$s";
private static final String MESSAGE_DISPLAY_PERSON_DATA = "%1$s Phone Number: %2$s Email: %3$s";
private static final String GOODBYE_MESSAGE = "Exiting Address Book... Good bye!";
private static final String MESSAGE_INVALID_COMMAND_FORMAT = "Invalid command format: %1$s";
//...
/**
* List of all persons in the address book.
*/
private static final ArrayList<String> person = new ArrayList<>();
//...
public static void main(String[] args) {
String userCommand = "nothing"; boolean exit = false;
if (args.length > 0) {
showWelcomeMessage();
processProgramArgs(args);
loadDataFromStorage();
while (!exit) {
System.out.print("Enter command: ");
userCommand = SCANNER.nextLine();
userCommand = userCommand.trim();
showToUser(userCommand);
String feedback = executeCommand(userCommand);
showResultToUser(feedback);
}
} else {
showToUser("Incorrect usage!");
}
}
private static void showResultToUser(String feedback) {
switch (feedback) {
case "0":
feedback = "Good (0)";
break;
case "1":
feedback = "Better (1)";
break;
}
try {
writeToFile(feedback);
} catch (FileNotFoundException e) {
//e.printStackTrace();
}
}
private static void matcher(String s1, String s2) {
// ...
}
/**
* Show the {@code message} to the user
*/
private static void showToUser(String message) {
System.out.println(LINE_PREFIX + message.trim()); // add LINE_PREFIX in front
}
// ...
}
W7.1d Can identify event-driven architectural style
Design → Architecture → Styles → Event-Driven Style
Event-driven style controls the flow of the application by detecting
When the ‘button clicked’ event occurs in a GUI, that event can be transmitted to components that are interested in reacting to that event. Similarly, events detected at a Printer port can be transmitted to components related to operating the Printer. The same event can be sent to multiple consumers too.
Evidence:
Explain how the AddressBook-Level4 uses Event-Driven style (refer to the Developer Guide for more info).
W7.1h Can explain how architectural styles are combined
Design → Architecture → Styles
Most applications use a mix of these architectural styles.
An application can use a client-server architecture where the server component comprises several layers, i.e. it uses the n-Tier architecture.
Assume you are designing a multiplayer version of the Minesweeper game where any number of players can play the same Minefield. Players use their own PCs to play the game. A player scores by deducing a cell correctly before any of the other players do. Once a cell is correctly deduced, it appears as either marked or cleared for all players.
Comment on how each of the following architectural styles could be potentially useful when designing the architecture for this game.
- Client-server
- Transaction-processing
- SOA (Service Oriented Architecture)
- multi-layer (n-tier)
- Client-server – Clients can be the game UI running on player PCs. The server can be the game logic running on one machine.
- Transaction-processing – Each player action can be packaged as transactions (by the client component running on the player PC) and sent to the server. Server processes them in the order they are received.
- SOA – The game can access a remote web services for things such as getting new puzzles, validating puzzles, charging players subscription fees, etc.
- Multi-layer – The server component can have two layers: logic layer and the storage layer.
Evidence:
Explain architectural styles currently used in AddressBook-Level4. Speculate under what circumstances other architectural styles can be used in it e.g. what kind of additional features can make a certain style applicable
W7.2a Can explain APIs
Implementation → Reuse → APIs →
An Application Programming Interface (API) specifies the interface through which other programs can interact with a software component. It is a contract between the component and its clients.
A class has an API (e.g., API of the Java String class, API of the Python str class) which is a collection of public methods that you can invoke to make use of the class.
The GitHub API is a collection of Web request formats GitHub server accepts and the corresponding responses. We can write a program that interacts with GitHub through that API.
When developing large systems, if you define the API of each components early, the development team can develop the components in parallel because the future behavior of the other components are now more predictable.
Choose the correct statements
- a. A software component can have an API.
- b. Any method of a class is part of its API.
- c. Private methods of a class are not part of its API.
- d. The API forms the contract between the component developer and the component user.
- e. Sequence diagrams can be used to show how components interact with each other via APIs.
(a) (c) (d) (e)
Explanation: (b) is incorrect because private methods cannot be a part of the API
Defining component APIs early is useful for developing components in parallel.
True
Explanation: Yes, once we know the precise behavior expected of each component, we can start developing them in parallel.
Evidence:
Know the API of the AddressBook component you are in charge of and the APIs of the other components your component depends on.
W7.3a Can draw intermediate-level sequence diagrams
Design → Modelling → Modelling Behaviors
What’s going on here?
- a.
Logicobject is executing a parallel thread. - b.
Logicobject is executing a loop. - c.
Logicobject is creating anotherLogicinstance. - d. One of
Logicobject’s methods is calling another of its methods. - e.
Minefieldobject is calling a method ofLogic.
(d)
Explain the interactions depicted in this sequence diagram.
First, the createParser() method of an existing ParserFactory object is called. Then, ...
Draw a sequence diagram to represent this code snippet.
if (isFirstPage) {
new Quote().print();
}
The Quote class:
class Quote{
String q;
Quote(){
q = generate();
}
String generate(){
// ...
}
void print(){
System.out.println(q);
}
}
- Show
new Quote().print();as two method calls. - As the created Quote object is not assigned to a variable, it can be considered as 'deleted' soon after its
print()method is called.
Evidence:
Explain the interactions depicted in this sequence diagram.
First, the createParser() method of an existing ParserFactory object is called. Then, ...
Draw a sequence diagram to represent this code snippet.
if (isFirstPage) {
new Quote().print();
}
The Quote class:
class Quote{
String q;
Quote(){
q = generate();
}
String generate(){
// ...
}
void print(){
System.out.println(q);
}
}
- Show
new Quote().print();as two method calls. - As the created Quote object is not assigned to a variable, it can be considered as 'deleted' soon after its
print()method is called.
- Ability to explain the sequence diagrams given [AddressBook Level4: Developer Guide]
- Ability to add more sequence diagrams to project documentation (to be done in future weeks)
W7.8 Can do small changes to an existing software
Covered by the 'Product' component of v1.1: